【RunPod+ComfyUI+WAN】キャラクターが崩れない最強動画AI「Wan2.2」完全攻略ガイド

【i2vで”静止画キャラから動画生成”】【t2vで”テキストから動画生成”】
現在、動画生成AIの領域で「実写・アニメ問わず、キャラクターの再現性がズバ抜けて高い」と猛烈に注目を集めているのが、Alibaba(阿里巴巴集団)のAI研究部門「DAMO Academy(達摩院)」が開発したオープンウェイトモデル「Wan(ワン)」シリーズです。
従来の動画AI(KlingやLeonardo AIなど)で頻発していた「動かすとキャラの顔や服が別人になってしまう」という問題をクリアし、自作イラストを思い通りに動かせる時代が到来しました。
この記事では、最新のWan2.2を中心に、その圧倒的な機能と、クラウドGPUのRunpodで「ComfyUI」を使って最高環境で動画を生成する方法を徹底解説します!
目次
WAN(VACE)とは?
Wanは、Alibabaが提唱する次世代の動画・音声統合フレームワーク「VACE(Video-Audio-Content Engine)」の核となる動画生成モデルシリーズです。
商用利用可能な Apache 2.0 ライセンスで公開されており、1080pから4Kクオリティの出力、そして極めて自然な物理挙動と質感を表現できることから「映画級のオープンソース動画AI」と評されています。
AlibabaのAI”VACE”に関する深掘りはこちらをCLICK!
AlibabaがAIに力を入れている
Alibabaは単なるEC企業ではなく、近年では
- 大規模言語モデル(ChatGPT的な)「Qwen」シリーズの開発
- データセンター / クラウド(Alibaba Cloud)
- AIアート、生成画像、翻訳などの研究
に非常に力を入れています。
VACEは、その中でも**「動画分野の戦略的技術」**として位置付けられていて、Stability AIやRunway、Pikaなどの生成系企業に対抗する動きと見られています。
VACE(Wan2.1‑VACE)の元論文要約
Wan2.1‑VACEは、AlibabaのTongyi Lab(DAMO Academy)が開発したマルチモーダル動画生成・編集統合モデルです。引用元:arxiv.org+5alibabacloud.com+5github.com+5。以下が主なポイントです
- マルチモーダル対応
テキスト・画像・動画・マスクという複数モーダルを統一フォーマットで処理し、幅広い動画タスクに対応。引用元:hyper.ai+5arxiv.org+5linkedin.com+5。 - Video Condition Unit(VCU)
それぞれのモーダルをひとつの内部条件表現にまとめられるため、柔軟かつ簡潔なインターフェイス設計が可能。引用元:arxiv.org+4the-decoder.com+4arxiv.org+4。 - 多様な動画タスクを統合処理
- T2V(テキスト→動画)
- R2V(画像→動画)
- V2V(動画→動画編集)
- MV2V(マスク付き動画編集 / 部分編集・補完)
のすべてを1モデルで扱える多機能性。引用元:comfyui-wiki.comalibabacloud.com+8arxiv.org+8github.com+8github.com+1alibabacloud.com+1。
- 概念分離(Concept Decoupling)
編集したい部分と固定したい部分をしっかり分けて処理できる仕組みを搭載。引用元:en.wikipedia.org+4the-decoder.com+4comfyui-wiki.com+4。 - 応用範囲が広い
短編動画、広告素材、映画向け効果・編集、教育用動画など、さまざまな用途に利用可能なユーティリティ性を持っています。
実際の表記例(GitHubや研究論文から)
- 「Wan2.1-VACE achieves unified generation and editing…」(論文より)
- 「We present VACE, a unified framework… powered by Wan models」(公式発表より)
- ComfyUIテンプレートでは「Wan2.1」 or 「VACE」どちらも登場し、実質的に同じものを指しています。
研究論文や発表は以下のような名前で出ています
- “Video and Audio Collaboration Engine (VACE)” by Alibaba DAMO
- GitHubやHuggingFaceにも公式ページがあります。
関連用語の整理
- VACE (Video-Audio-Content Engine): 動画・音声・編集を1つのアーキテクチャで統合するAlibabaの全体フレームワーク。
- Wan2.1 / Wan2.2: VACEに対応した具体的な動画生成モデルのバージョン。最新のWan2.2では、さらに高精細かつ意図通りの制御が可能になりました。
ComfyUIなどの環境では、以下の多彩なワークフロー(テンプレート)を選択して動画を生成・編集できます。
| 呼称 | 意味・内容 |
|---|---|
| VACE | Video-Audio-Content Engine の略称。動画生成・編集を1つのアーキテクチャで統合するAlibabaのフレームワーク全体を指す |
| Wan | VACE内部で使われる 動画生成モデルのシリーズ名。Stable Video Diffusionに近い役割 |
| Wan2.1-VACE | 最新のVACE対応モデルの1つで、「統合エンジン(VACE)」に対応した動画生成モデル(2.1はバージョン番号) |
| Wan Video | 多くの場合、「WanモデルによるVideo生成機能」のことを指し、ComfyUIではi2v/t2vモードとして扱われる |
1. I2V(Image-to-Video / 画像 → 動画)
一枚の静止画(イラストや写真)を原画として、プロンプトで指示した動きを与えます。
2. MV2V(マスク付き動画編集)
動画の特定部分(例:人物だけ)をマスクで指定し、衣装の入れ替え、カラー変更、モーションの追加などを部分修正します。
3. V2V(Video-to-Video / 動画 → 動画変換)
既存の動画の構図や動きを維持したまま、実写をアニメ風に、あるいはサイバーパンク風にスタイル変換します。
4. T2V(Text-to-Video / テキスト → 動画)
「ジャンプする猫」など、テキストプロンプトのみからゼロベースで動画を生み出します。
5. F2V(First-and-Last-to-Video / 前後画像補間)
「開始画像」と「終了画像」の2枚を入力し、AIがその間の「中割りの動き」を自然に補間生成します。
WANの機能
特定のキャラクターを固定して動画を作りたいクリエイターにとって、現状「Wan2.2 14B (I2V) + High Noise設定」以上の選択肢はないと言われています。(2026年5月記載)
他の商用動画AIでは、1フレームごとに顔の造形が微妙に変化して(モーフィング現象)美化されたり崩れたりしがちですが、Wanは「1枚目のキャラクターの顔、服装、特徴を頑なにキープ」して動かしてくれます。
そんなWanですが、上でご紹介した主な5つの使用方法(I2VやV2Vなど)の内、どの方法で、動画を作成するかによって使用するテンプレートやモデルが変わってきます。
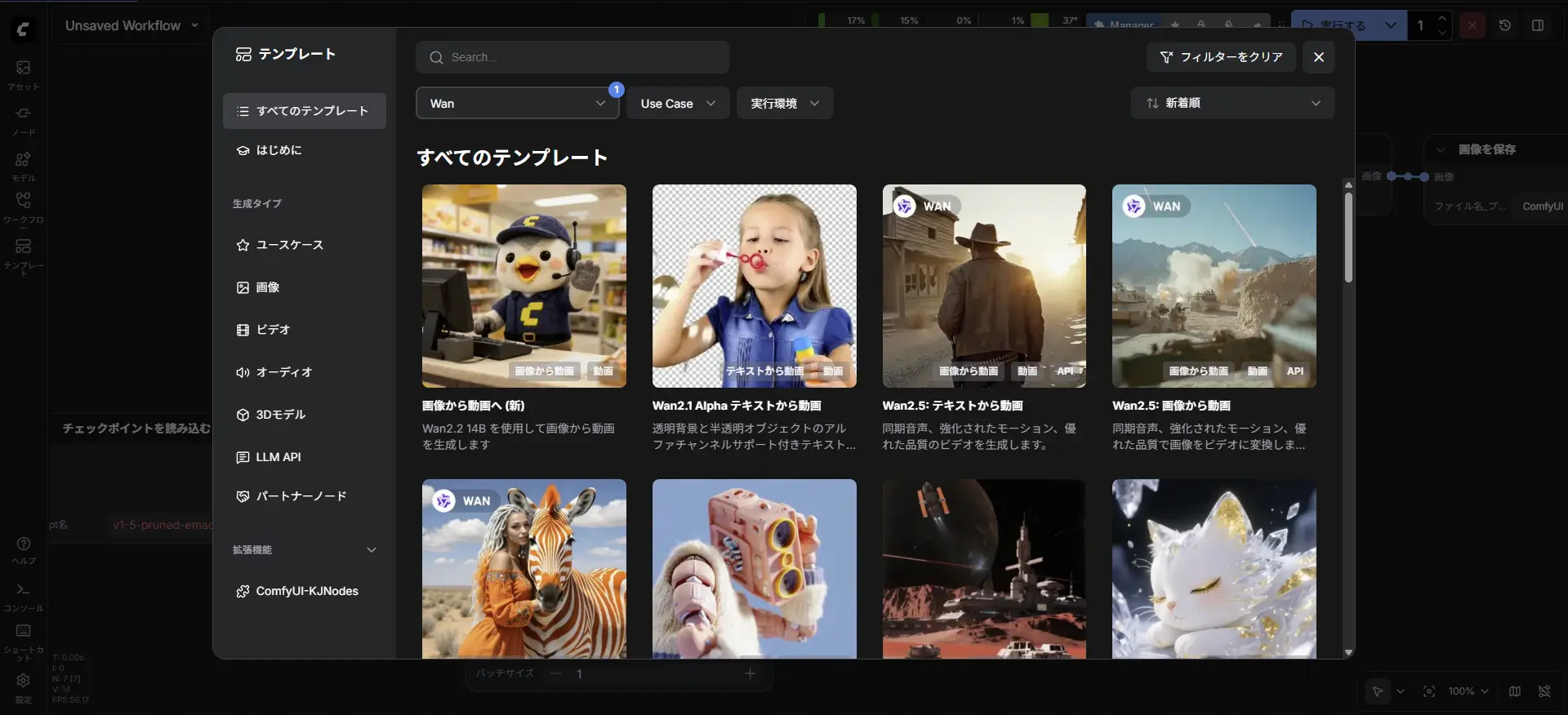
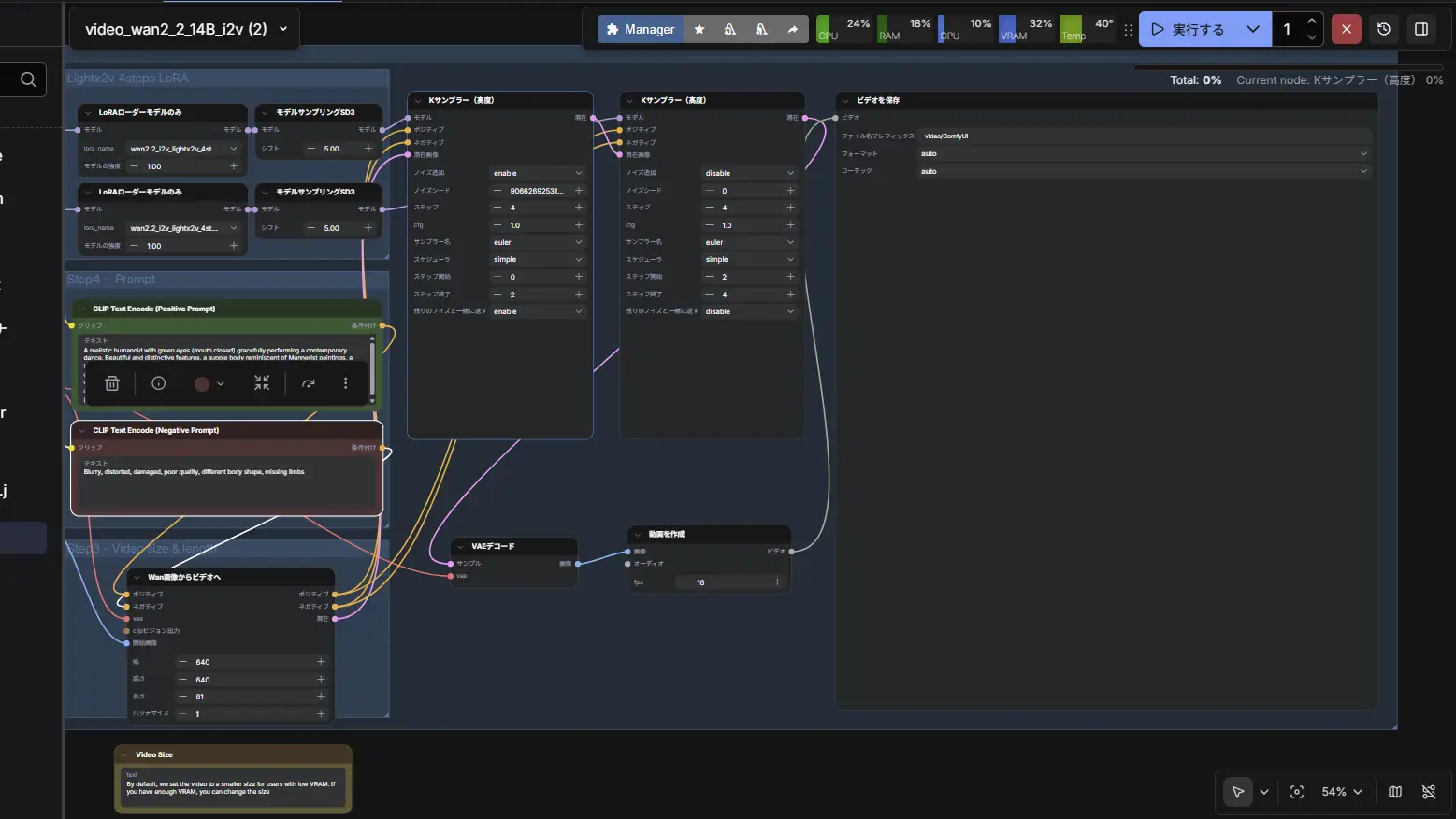
最新の検証トレンド ComfyUI上では、GGUF形式(Q8_0など)に軽量化された14Bモデルを用い、Wan専用に開発されたLoRA(例: LightX2Vなど)を組み合わせることで、わずか数ステップの高速生成でも、驚異的なキャラクター再現性を維持した動画制作が可能になっています。
キャラクターの再現性
下の動画では、Wanのキャラクター再現性の高さが分かりやすいとおもいます。
他ツールで良く起こる、”キャラクターが変わってしまう”という問題が起こりにくいというのが特徴です。
この動画ではWan 2.2 / 14B (I2V )で生成しています。
ちなみにこちらはRTX5090を使用しています。
必要なVRAM目安と目的別おすすめGPU
主力である最高画質の「14B(140億パラメータ)」モデルは非常に巨大で、ローカルのRTX 4090(24GB)でもVRAMの限界に達します。そのため、多くのクリエイターがクラウドGPUサービス「RunPod」(※後ほど解説)などで大容量VRAMをレンタルして運用しています。
 SAKASA
SAKASASAKASAはクラウドGPUのRunpodで30GB以上のGPUを使用しています。
GPU 選択の際の目安
| Wan モデル | 必要 VRAM目安 | RunPodで狙うGPU |
|---|---|---|
| Wan 2.1 / 1.3B (T2V, 480p) | 8GB〜 | RTX A4000 (16GB)、RTX 3090 (24GB) |
| Wan 2.2 / 5B (T2V/I2V) | 8GB〜(オフロード対応) | A4000 (16GB) でもOK、余裕を見るならRTX 3090 / 4090 |
| Wan 2.2 / 14B (I2V / 720p) | 約20GB〜30GB | RTX 5090(32GB)、L40S (48GB)、A100 / H100 (40GB/80GB) |
動画生成の時間感覚
長尺 → 15秒以上(高VRAM GPU必須、生成時間が現実的でなくなる場合も)
中尺 → 8〜12秒(挑戦レベル、設定調整や工夫が必要)
短尺 → 3〜5秒(試し撮りサイズ、安定して動作)
コスパで中尺を狙う → RTX 4090
安定性と余裕で中尺をやる → L40S (48GB)
本格的に長尺・高解像度も → A100 / H100 (40GB以上)
公式ブログ情報(Wan 2.1 1.3Bモデル)
- Wan 2.1 1.3Bモデルは480p 5秒で RTX 4090 使用時に 約4分。
- 14B モデルだとこの倍以上の時間がかかると見込まれる。
このように公式も書いていますが、RTX4090では遅くてとても待っていられないレベルです。
 未来
未来上に掲載した参考動画はWan 2.2 / 14B を、RTX5090で動かしていますが、それでもかなり待ち遠しいですよね。
Runpodの使用方法
Runpodでの使用方法を三通りご紹介します。
SAKASAおすすめは、断然③の方法です。
アカウントの作成などについてはこちらの記事で書いています【Runpodの使い方と料金】Stable Diffusionを使用して画像生成とLoRA学習をする方法【②実践編】
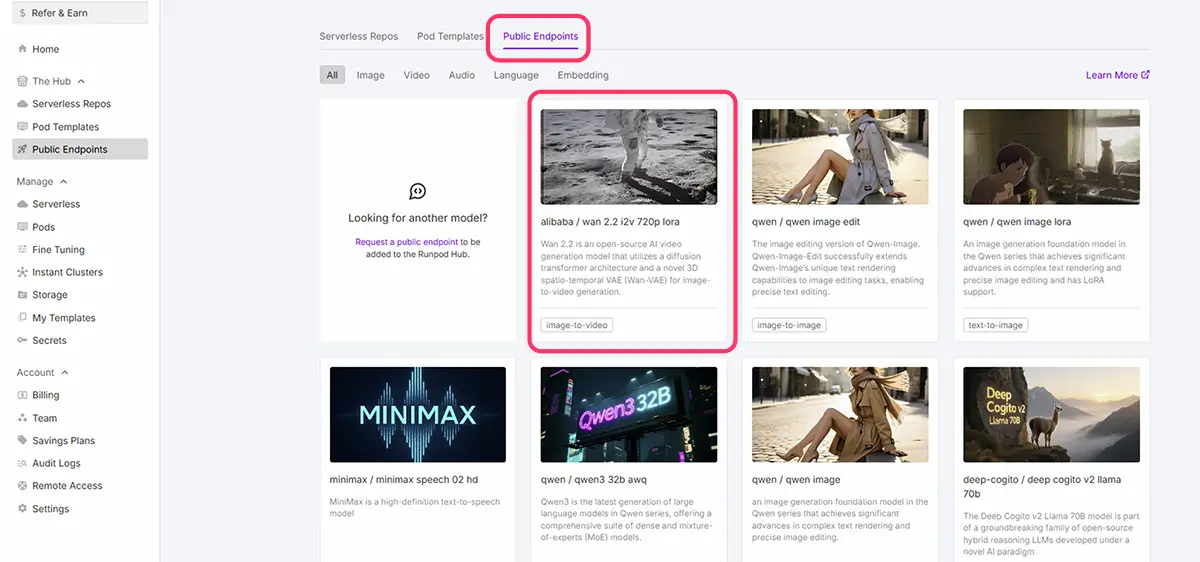
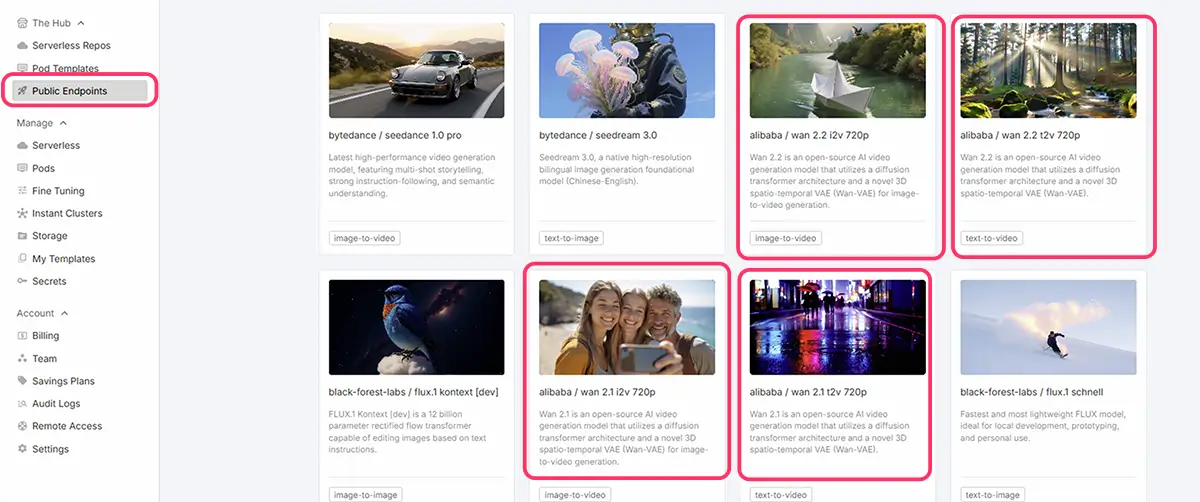
①RunpodのPublic Endpointsで使用する方法
- 自作イラストを読み込んで、動きやアニメーションを付けられます。

右は、Runpodの
Public Endpoints内の
Wan 2.2 I2V 720pで
左の画像から、ワンクリック生成した8秒動画。
この、画像からの動画生成では、プロンプトのみを指定した。
生成時間は4分20秒
Runpod公式ホームページのPublic EndpointsからWan 2.2 I2V 720p
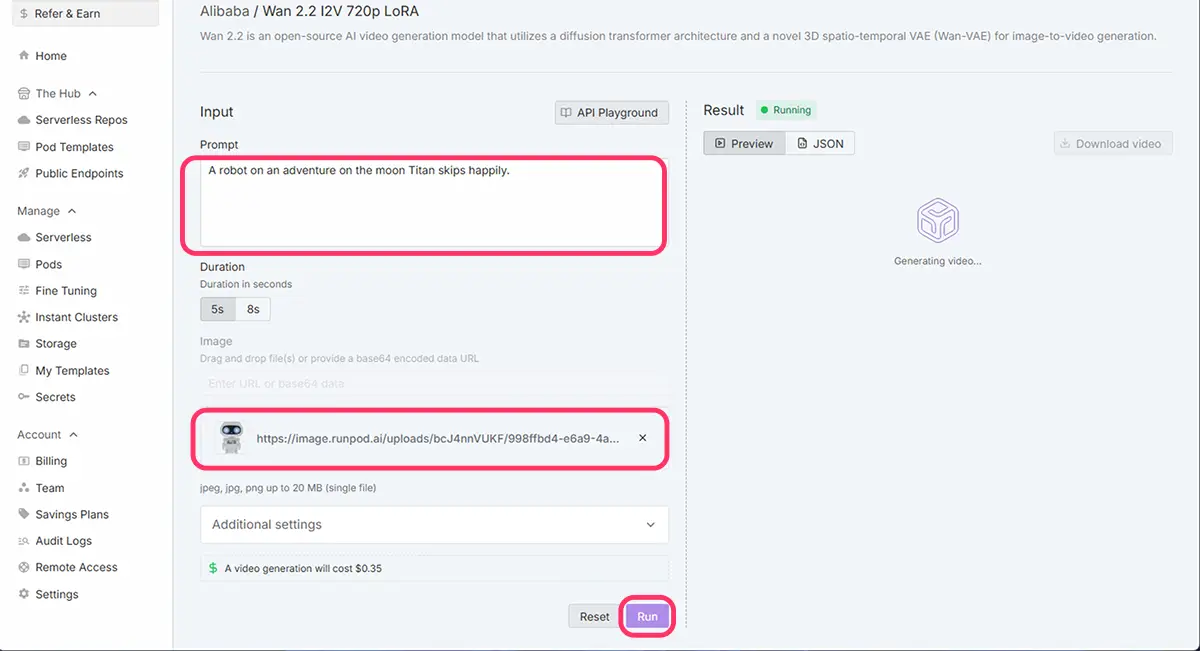
 未来
未来RunpodのPublic Endpointsは、好きなツールを選択するだけで、すぐに生成できる手軽さがおすすめポイントです。
②Runpodのテンプレート(ComfyUI + Wan)を使用する方法
WanはRunpod内のComfyUIテンプレートを用いて使用できます。
アカウントの作成などについてはこちらの記事をご覧ください【RunPodの使い方と料金】Stable Diffusionを使用して画像生成とLoRA学習をする方法【②実践編】
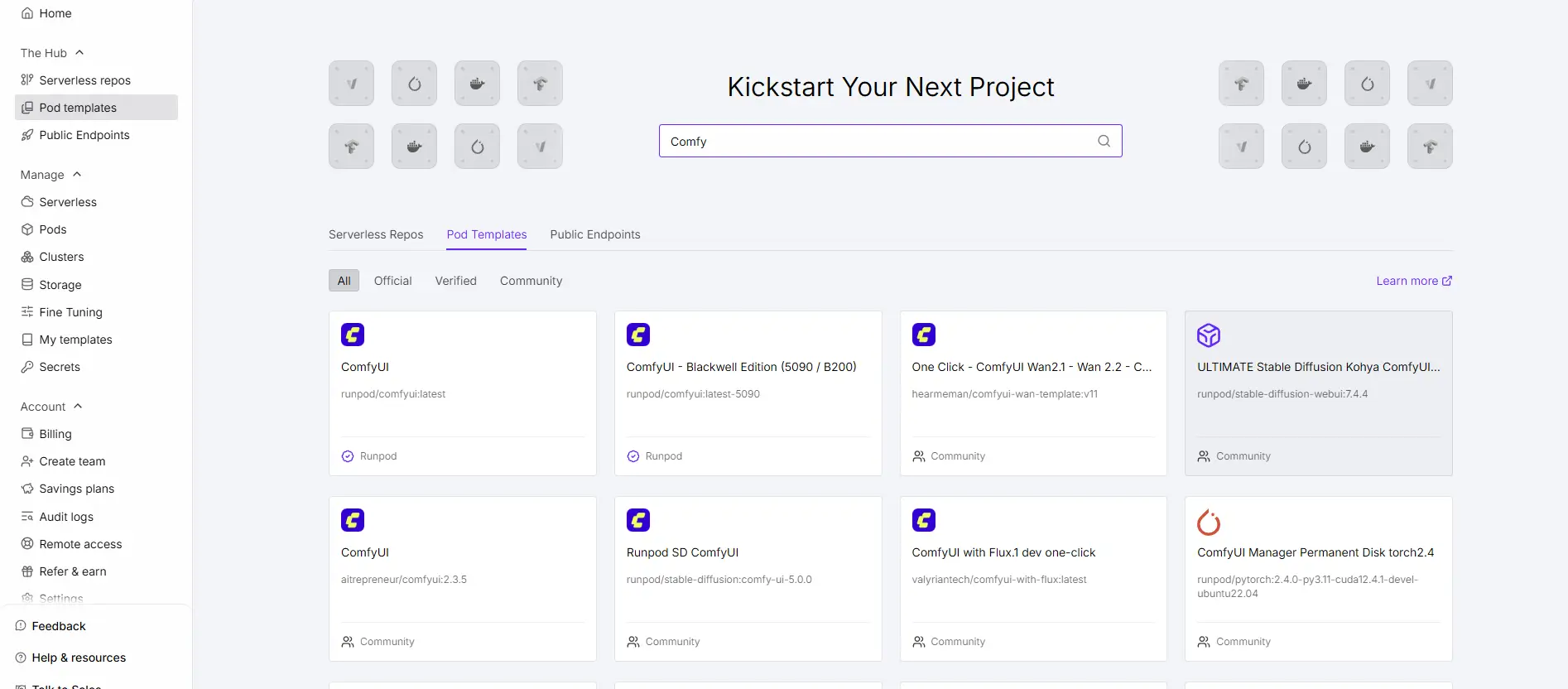
ComfyUでは、テキスト・画像・動画元素材から簡単に動画を生成できるテンプレートが沢山用意されています。
ComfyUIの画面を立ち上げるとノードのテンプレートがワンクリックで選択が出来るようになっています。
モデルのインストール方法はこちらの記事をご覧ください
ComfyUIとは?使い方・モデル・テンプレート・基本機能を解説【2026年版】 ComfyUI 使い方導入ガイド|モデル・テンプレート ComfyUIは、画像・動画・3D生成をノードベースのワークフロー形式で操作できる生成AIツールです。「モデルは何を使え…
初期セットアップの手順
step
RunPodでテンプレートをデプロイ
“ ComfyUI、Wan t2v i2v VACE、WAN” などを選び、Podを起動。
step
Podが起動
デプロイ後、Podのログで” Ready”などのメッセージを確認します。
Jupyter / SSH / WebUIに接続
step
ターミナルでモデルをダウンロード(wget / git clone / HF CLIなど)
/workspace に保存して使う
step
ComfyUIのUIにアクセス
Web ブラウザから指定URLにアクセスして、ComfyUIが表示される状態になっていればOK。
便利設定・Tips
- モデルのダウンロード設定:テンプレートデプロイ時に「環境変数でモデルをダウンロードするよう設定」してください。さもないと、実行時にエラーになります 。
- リアルタイムプレビューを有効に
- ComfyUIの VHS設定で Advanced Previews を “Always”、Preview method を “Auto” にすると、動画生成途中でもプレビューが表示され、失敗パラメータに気づきやすいです。引用元: reddit.com。
③当サイトのセットアップツールを使用する方法
面倒な設定や、テンプレート選びなどの手間を省きたい方の為に、当サイトが制作しているセットアップツールを使用する方法をご紹介します。
Runpodアカウントをお持ちの方であれば、今から約4~10分後には、一枚目の画像を選択し、動画の生成を始められるほどのスピード感で使用できます。
ワンクリックセットアップツールの内容
販売物はZIP形式です。ダウンロード後にZIPファイルを左クリック➡すべて展開すると下記のファイルが入っています。
- .txt(READMEー初めにお読みくださいー)
- ワンクリックセットアップツール(本体)
- .json(ワークフローファイル)
- .png(サンプル画像)
※READMEー初めにお読みくださいー内の、■こちらのURLの”導入ガイド”をご覧ください■のURLを開き、手順通りに進めていくだけです。
唯一の注意点は、最高性能の14Bのセットアップをきちんと動かせるように、GPUの選択の際に、VRAM32GB以上のGPUを選択する事だけです。
SAKASAちなみに、このセットアップツールでのおすすめGPUはA40です。
A40が空いていたら超ラッキー!!
セットアップツールの詳しい解説はこちらのページをご覧ください。
SAKASA AI
【Runpod 時短ツール】ワンクリックセットアップ | SAKASA AI RunPodで生成を始めるまでの面倒な作業を自動化 ✅ テンプレート探し不要✅ ノード探し不要✅ ダウンロード設定不要✅ モデル、ノードの設定、配置済み✅ 推奨構成が自動で…
i2v【参考画像から動画を生成】セット
Wan2.2 I2V【GGUF14B】 動作確認済みワンクリックセットアップツール for RunPod – SAKASA Workflow Lab – … RunPodのComfyUIで Wan2.2 I2V を すぐに使い始めたい方向けのワンクリックセットアップツールです ⭕Wan2.2 I2V【GGUF14B】の導入作業を自動化 ⭕ 複雑なセットアップ作業…
i2v(画像→動画)の基本手順
- ComfyUI内で i2vワークフロー を選択。
- 「Load Image」ノードに、自分の絵のファイルを接続。
- フレーム数・解像度・プロンプトなどを設定。
- 実行ボタン(▶)を押すと、一定時間後に
ComfyUI/output/videoに mp4 が出力されます。
t2v(テキスト→動画)の基本
- プロンプトを「キャラが動いてる様子」など具体的に記述。
- フレーム数や解像度を指定。
- ▶を押せば動画が生成され、処理後は同じく
output/videoに保存されます 。
どのテンプレートを選んだ後も、ComfyUIの画面ではフローを編集できます。また、フロータブからいつでもテンプレートを変更できますので、気軽に選んでみまし
- 解像度変更
- フレーム数の増減
- 動きのスムーズさの調整(interp系)
もカスタマイズ可能です!
「Start image」「End image」がある場合の設定
| 項目名 | 意味 | 役割 |
|---|---|---|
| Start image | 開始フレーム(最初の画像) | 動画の1フレーム目をこの画像から生成 |
| End image | 終了フレーム(最後の画像) | 動画の最終フレームをこの画像に近づけるよう補間生成 |
この2枚を指定すると、AIがその間の動きを「補完」して動画を生成します。
- 例:
- Start image → 女性が前を向いている絵
- End image → 同じ人物が少し横を向いている絵
→ その間の動きを自然に繋いでくれるようなショート動画になります。
2つのCLIP Text Encode
ComfyUIフロー内に「CLIP Text Encode(Clipテキストエンコード)」ノードが 2つあります。
画像生成・動画生成系のAIでは、複数のプロンプト入力を使い分けるためにエンコードノードが複数使われます。
| 目的 | 説明 | ノードの役割 |
|---|---|---|
| ① 正規のプロンプト(positive prompt) | 「こうしてほしい」方向の指示 | 明るい・女性・水彩・幻想的など |
| ② ネガティブプロンプト(negative prompt) | 「こうならないでほしい」方向の指示 | ノイズ・崩れ・奇形・にじみ・extra limbs など |
例:
CLIP Text Encode(Positive) ← "a woman walking in the wind, smooth, cinematic"
CLIP Text Encode(Negative) ← "blurry, deformed, extra limbs, low quality"最低限の手順(i2vで Start / End を使う)
step
Start image を読み込む
自分の描いたイラストや写真などを設定
step
End image を読み込む(任意)
変化させたい目標フレーム(同じキャラの別ポーズなど)
step
プロンプトを入力する
例:a girl turns her head slightly, gentle lighting, smooth motion"
step
必要があればフレーム数・出力サイズの確認
例:16フレーム / 480p(初期値のままでもOK)
step
▶ 実行!- プロンプトは「動きの方向性」を示す程度にする。
(例:「歩き出す」「振り返る」「風になびく」など) - StartとEndの絵が似すぎていると、あまり動かない。
→ ポーズや視線を少し変えてみる。 - 出力がカクつく場合は、「interpolation(補間)」のオプションを増やしてみる。
Wan動画用プロンプト変換 β版
日本語で情景を書くと、Wan向けの英語タグ列に整形します。
ここに変換結果が表示されます
その他のオプション
| 項目名 | 意味 | 推奨値(初回) |
|---|---|---|
| Num Frames | 生成する動画の長さ(フレーム数) | 16〜24 |
| Resolution | 出力解像度 | 480p(初回は小さめでOK) |
| FPS | フレームレート | 6〜12(後から調整可) |
LoRAモデルをWanで使う方法
既に学習済みのLoRAモデルを使う場合、Wanでも特別な操作は不要です。基本は モデルを所定のフォルダに入れるだけ で利用可能です。
手順
step
モデルファイルを準備する
学習済みLoRAファイル(.safetensors または .ckpt など)を用意します。
step
WanのLoRAフォルダにコピー
Wanのインストールディレクトリ内の以下フォルダにモデルを入れます。
models/LoRA/step
Wanを再起動
起動時に新しいモデルが自動で認識されます。
step
プロンプトで呼び出す
- LoRAモデルはプロンプトに以下の形式で指定します: <lora:モデル名:重み>
- 例:
<lora:MyLoRA:1.0> - 重みは0.5〜1.0程度で調整可能です。
注意点
- 互換性
- SD 2.x系モデル用のLoRAはWanでも問題なく使用可能
- SD 1.x系の場合、精度や出力の雰囲気が微妙に変わることがあります
- 精度
- 重みによって生成結果が変化します。最初は1.0で試し、必要に応じて0.5なども試すとよいです
- 出力の違い
- Wanの独自処理(ノイズスケジューリングやサンプラーの違い)により、微妙に絵柄が変わることがある
エラー/トラブル
最近のトラブル”2つ目のKサンプラーでクラッシュする件”についてこちらで書いています
あわせて読みたい
【Reconnectingエラー】ComfyUI Wan 2.2 I2V:2つ目のKSamplerでクラッシュする問題と解決法 ComfyUI Wan 2.2 I2Vのエラー Reconnecting 最近(2026年4月上旬)【video_wan_2_2_14B_i2v】WanのI2Vで2つ目のKサンプラーで毎回、停止してしまうようになりました。 …
ComfyUIで動画の背景だけを再生成する方法3選
こちらの記事では、ComfyUIで動画の背景だけを再生成する方法について、3通りの方法を紹介しています。
SAKASA AI
【Wan、BiRefNet】ComfyUIで動画の背景を差し替える3つの方法【比較まとめ】 | SAKASA AI ComfyUIで動画の背景を差し替える3つの方法を解説。BiRefNetによるマスク生成から合成、Wan Video2Video、インペインティングまで、用途別に「速さ・自然さ・手間」で比較…
動画の背景をComfyUIで削除(透明背景)する方法
動画の背景を消して高精度の背景透過動画を作りたい時に活躍!
SAKASA AI
【ComfyUI】ZhengPeng7/BiRefNetを使用して動画の背景を高精度で削除する方法 | SAKASA AI ZhengPeng7/BiRefNet BiRefNetは画像処理の“AIモデル(=処理エンジン本体)で、 最大の特徴は、髪の毛・レース・細いパーツなどの再現が強く、2K〜4Kでも劣化しにくい事(…