【Runpod】GPUの選び方「時間とお金を両方溶かす」前に読む話|VRAM・コスト・失敗パターンまとめ

Runpodで適切なGPUを選んで作業効率を最大化する方法
Runpodの基本的な使い方はRunpodの使い方と料金で解説しています。
目次
GPU選びを間違えると、何が起きるか
Runpodを始めたばかりのときは、「安いGPUで試してみよう」と選んでしまいがちです。
それ自体は問題ではありません。
しかし、「安い=お得」とはならないのが、Runpodの時間課金の現実だと、じわじわと気付くことになります。
お金だけじゃなく、「時間」と「失敗率」がすべてコストになる
この事を考えずにスタートしたSAKASAは、1セッションで数ドル消えた上に何も生成できていない、という事態が頻繁に起こりました。
これが一体どういう事なのかについて、この記事で解説したいと思います。
 SAKASA
SAKASA痛い経験をお話します・・・( ;∀;)
よくある誤解:「安いGPUの方が得」
Runpodで選ばれやすいGPUといえば RTX 4090 やL4,、A4000。 時間単価が安く見えるので「コスパがいい」と感じます。
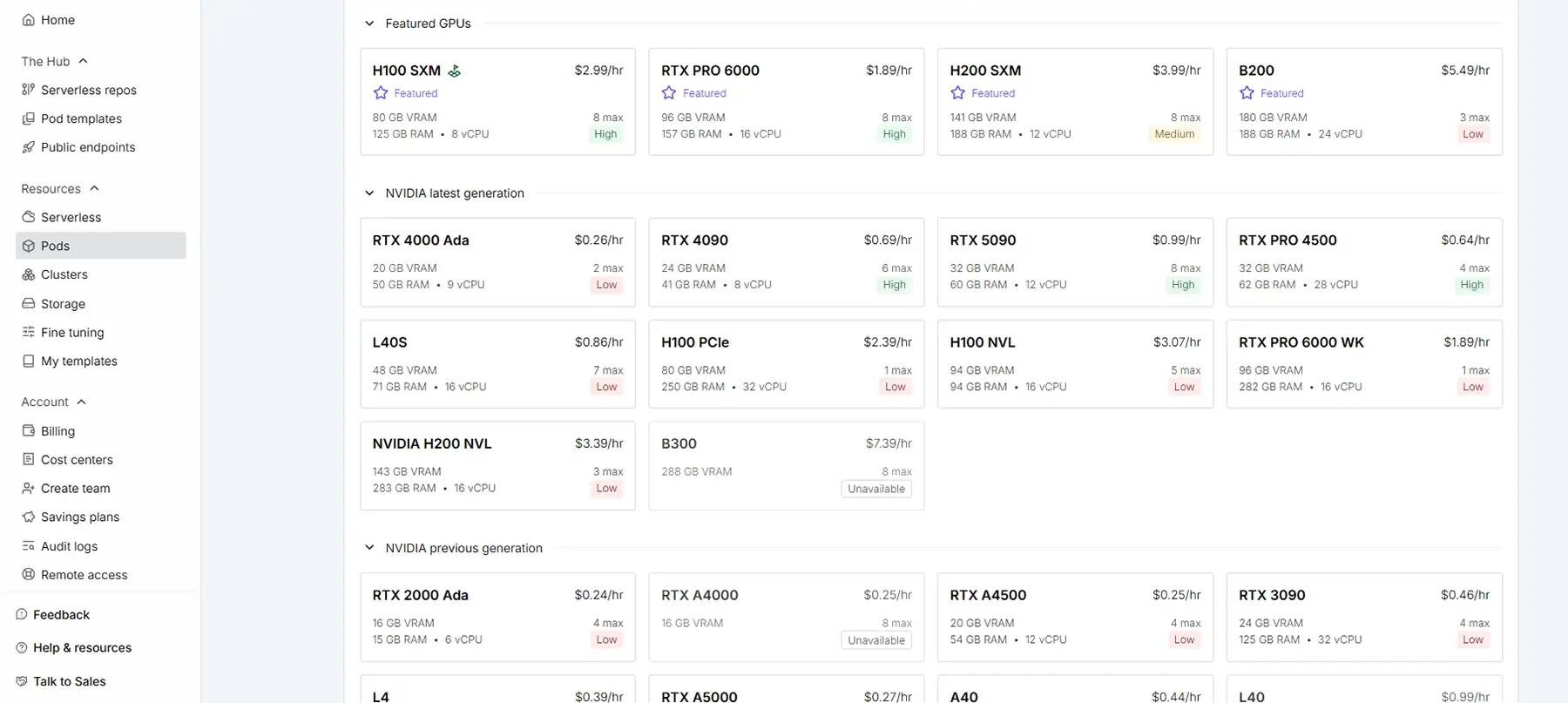
でも、ここに一つ目の落とし穴があります。
本当に見るべきポイント3つ
1. VRAM不足で「workflowが動かない」
まず、ワークフローには、最低VRAMの壁があります。
SAKASA最低VRAMとは・・・
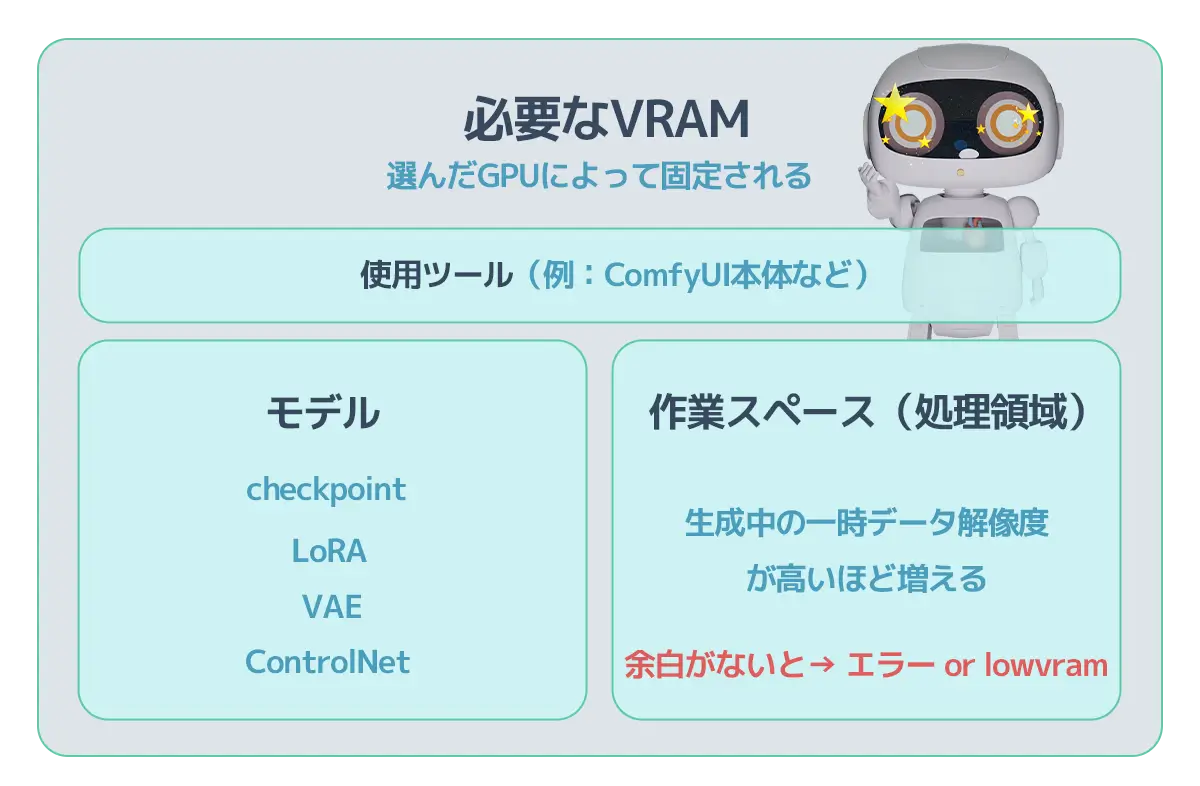
使用したいAIツール(たとえば、ComfyUIなど)を使用する際に最低限必要なVRAMのサイズの事です。
主に見落とされがちなのが、作業領域のための余白です。
ここには、生成処理をする為の余白を残しておく必要があります。
VRAM不足で起きること
- ワークフロー自体が起動しない
- 強制lowvramモードで動作(品質低下・速度激落ち)
- 生成途中でエラー終了 → やり直し
SDXL系で最低8GB、FLUXや動画生成系(WANなど)では24GB以上(ただしこれは、ギリギリ動くという意味です。エラーで止まらないサイズは50GB以上です。)が実用ライン。
動画生成・LoRA学習を含めるなら24〜48GBは欲しいところ。
 未来
未来あれ?なんか動いて無くない?
と、思ったら止まってたって経験ありませんか?
2. 生成時間の増加=「試行回数が減る」
二つ目のポイントは、生成AIの作業は、1回で終わらない。という事です。
プロンプト調整・構図確認・再生成をくり返して1作品が完成します。その為、単純な時間計算で見ると
処理速度が遅いGPUは、試行回数そのものが減ってしまいます。
1回の生成に2分かかるGPUと30秒のGPUでは、同じ1時間で試せる回数が4倍も違う。
未来そうだね。
SAKASAここら辺も価格に反映されていたと気付いたのはずっと後になってからでした・・・
3. 再起動・やり直しは時間コストが積み重なって無駄!
そして、三つ目のポイントは、
Runpodの時間課金でじわじわ効くのが「作業外の時間」です。
- モデルのDL待ち(5〜15分)WanやFluxなどの重いモデルだとダウンロードだけで20分~かかる
- セットアップのやり直し
- エラー対応で画面と格闘している時間
この時間もすべて課金対象&時間コストになります。
Runpod特有の落とし穴”作業外の時間”
「遅いGPUが逆に高くなる」という逆転もおこる
Runpodは時間課金なので、処理が速いGPUの方がトータルコストが下がるケースが多いのです。
単価が高くても生成時間が短ければ、支払いは同じかむしろ安くなります。 「時間単価の安さ」だけで選ぶと、逆に高くつく場合があるのはこの為です。
セットアップ失敗でも課金と時間は進む
Pod起動後、モデルのダウンロード中やテンプレートエラー中もすべて時間と課金が走ります。
そのため、起動してすぐ「使える状態」になるかどうかが最初の分岐点です。
NetworkVolumeあり(50GB・$3.50/月) GPU単価:5090($0.99/hr) GPU単価:A40($0.44/hr)
5090で元が取れる回数
月14回〜
週3〜4回ペースで到達
A40で元が取れる回数
月32回〜
週8回ペースで到達
NetworkVolume月額(50GB)
$3.50
$0.07 × 50GB
※ DL時間15分・GPU単価で計算。実際の時間は環境により異なります。RunPodの料金は変動します。
そういう意味ではNetworkVolumeは一見、追加課金に思えますが、実際は逆です。
上の表のように、価格だけで見るとピンときませんが、Network Volume(保存用ストレージ)がない場合、毎回起動のたびにモデルのDL時間が発生します。ComfyUIの起動と、モデルのダウンロードを含めると15分以上かかることも珍しくありません。
そのため、NetworkVolumeは、使用するモデルの重さ(ダウンロードにかかる時間)で使用を決めます。
月10回起動すれば、それだけで**150分以上がDL待ちに消えるモデルの場合。**お金に換算すると、5090($0.99/hr)なら約$2.50。NetworkVolume 50GBの月額$3.50とほぼ変わりません。
回数が増えるほど差は広がります。NetworkVolumeは「節約のために使わない」ものではなく、「時間とお金を守るために使う」ものです。
あわせて読みたい
【2026年最新版】RunpodのNetwork Volume(保存用ストレージ)の作成方法と使用方法 ストレージ(Storage)の設定 この記事では、クラウドGPU Runpodの”NetworkVolumeの作成方法と使用方法”について解説しています Network Volume(永続ストレージ/networ...
GPU別:生成作業の現実イメージ
| GPU | VRAM | 目安時間単価 | 向いている用途 | 注意点 |
|---|---|---|---|---|
| RTX 3090 | 24GB | 低〜中 | SD系・SDXL・FLUX軽量 | 動画生成はギリギリ |
| RTX 4090 | 24GB | 中 | SD系・SDXL・FLUX軽量 | 動画系は遅め |
| A40 | 48GB | 中 | FLUX・動画生成・LoRA学習 | バランス良 |
| A6000 | 48GB | 中〜高 | 高解像度・大規模LoRA | 安定動作 |
| A100 | 80GB | 高 | 動画生成・超高負荷 | 速度◎ コスト高め |
| RTX 5090 | 32GB | 高 | FLUX・高速生成 | 最新アーキ・速い |
※価格は変動しますRunpod公式で最新確認を。
4090 vs 高性能GPU:イメージ
4090は画像生成では実用的に速いです。
しかし、動画生成・高解像度・LoRA学習・重いworkflowになるとその差が出ます。
体感の違いは「待ちながら微調整するか、サクサク試行できるか」の差です。
 未来
未来試行回数が増えると、作品の完成度も上がります。
環境構築ツールを活用するともっと楽になる
SAKASA AI開発の【Runpod 時短ツール】ワンクリックセットアップ
初心者の方でも簡単に使える、超速時短のためのワンクリックセットアップツールを開発しています。

Runpod>>>起動からモデル配置までをワンクリックセットアップ >起動後すぐに使えるモデル&ノード構築済みComfyUIです。
テンプレート選びや、ノード追加、モデル導入の手間をすべて排除しました。ComfyUI起動後すぐに本格制作が可能。使い捨ても出来る環境構築セットアップツールです。
まとめ:GPUは「価格」ではなく「総作業時間」で選ぶ
- VRAMは用途に対して余裕があるか
- 生成速度で試行回数を確保できるか
- セットアップ含めたトータルコストで考えているか
この3点を意識するだけで、RunPodの使い方は大きく変わります。
あわせて読みたい
【2026年最新版】Runpod記事まとめ|テンプレート・環境構築・トラブル解決ガイド 【2026年最新版】RunPod総合ガイド|ComfyUI・LoRA学習・注目テンプレートまとめ 本ページは、Runpodの使い方や料金、具体的な活用方法などに関する記事のリンクをまと...