【CodeFormerの使い方】3通りの方法

3通りの使い方
目次
CodeFormerとは?
顔の復元・補完・高画質化に特化したAIツールです。
主に次のような用途に向いています
- ぼやけた顔写真を鮮明にしたいとき
- AI生成画像の崩れた顔(目・口・鼻)を修正したいとき
- ノイズが多い古い写真の顔を補完したいとき

CodeFormerの使用環境
CodeFormerやReal-ESRGAN、GFPGANのようなツールは、一般に以下のような環境を前提としています。
- Python(3.8~3.10あたり)
- PyTorch(+CUDAドライバ:NVIDIAのGPUがあれば)
- Git
- LinuxまたはLinux系OS(Ubuntuなど)での動作
しかし、これらの環境が無くても使用できる方法もあります。
今回は、上記の環境(ローカル)以外で使用できる方法を含めた、3通りの使用方法について、解説していきます。
1⃣【手軽】ブラウザで試す(ローカルGPU不要)
 未来
未来CodeFormerのみを単体で試したい場合には手軽な方法です!
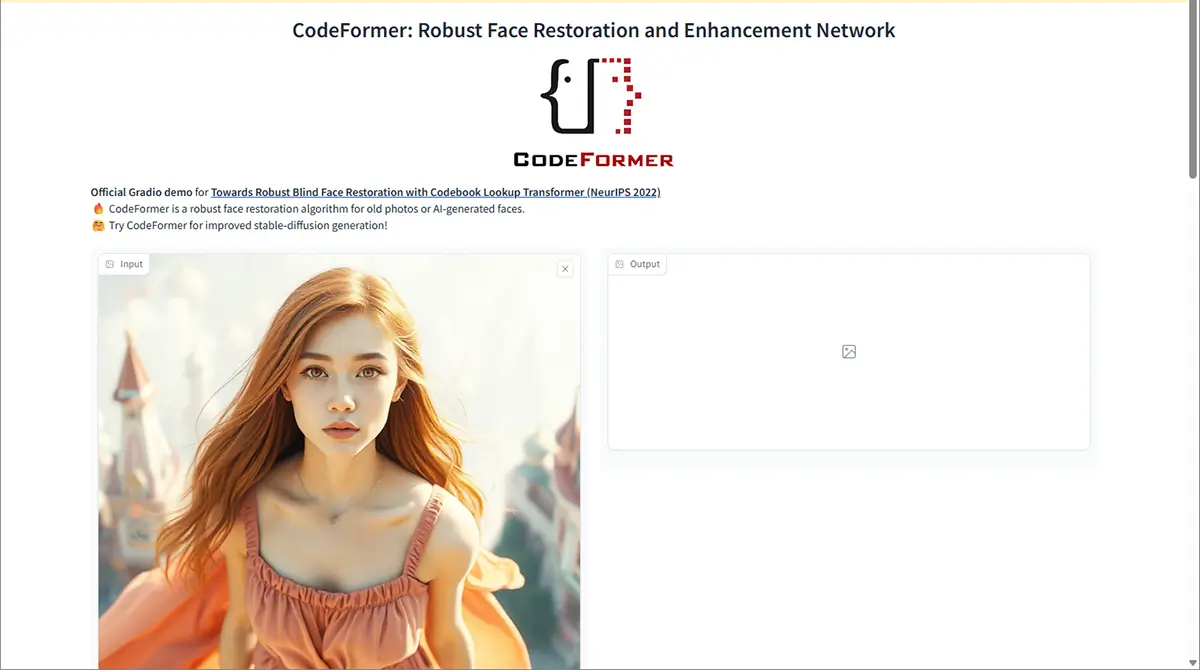
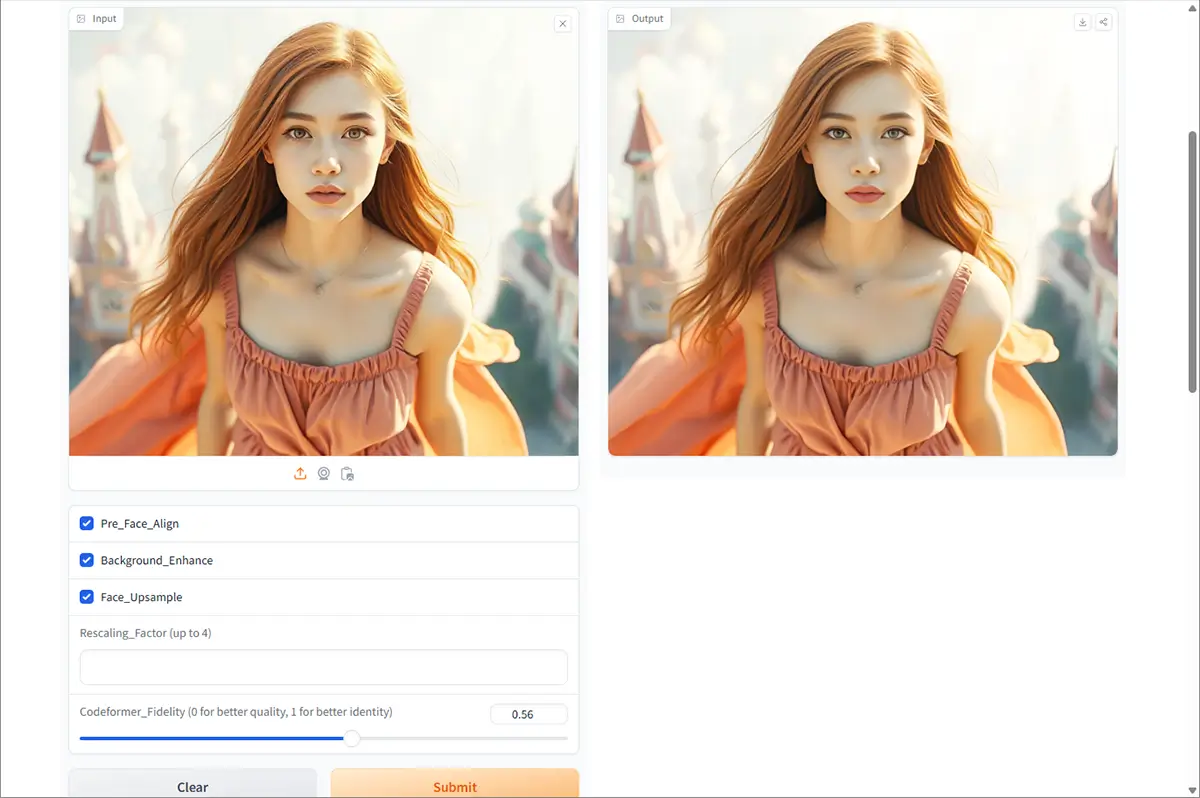
Hugging Faceのデモページ
Hugging Face CodeFormer ページはこちら
- ページを開くと、シンプルな操作画面が出てくる
- 画像をアップロードする(自分の写真や試したい画像)
- 「Submit(送信)」ボタンを押す
- 数秒〜1分くらい待つと、修復された顔画像が出てくる!
- 完了したらダウンロード!
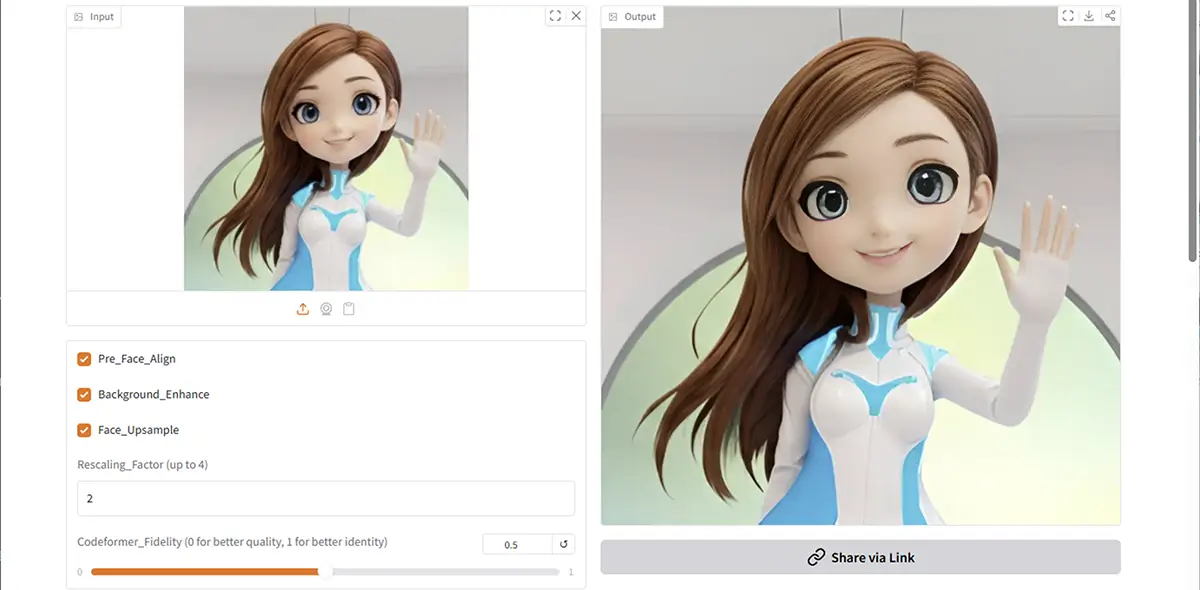
CodeFormer の各パラメータ解説
1. Pre Face Align(事前顔位置合わせ)
- 意味:顔画像を事前に「正面向き」に整える処理を行うかどうか。
- **有効(オン)**にすると:
- 歪んだ顔、斜め向きの顔なども正面向きに近づけて修復できる
- ただし、元の構図やアングルが崩れることもある
- オフにすると:
- 元画像の向きそのままに処理される
- おすすめ:顔が大きく傾いている場合はオン、それ以外はオフでも可。
2. Background Enhance(背景強調)
- 意味:顔の修復と一緒に背景も補正・改善するかどうか。
- オンにすると:
- 背景のボケやノイズも改善され、全体的に鮮明になることがある
- オフにすると:
- 顔だけ修復され、背景には手を加えない
- 注意:顔だけ修復したい場合はオフのほうが自然です。
3. Face Upsample(顔の超解像処理)
- 意味:修復後に顔部分をさらに高解像度にアップスケールする機能。
- オンにすると:
- 顔がよりシャープで詳細になる
- オフにすると:
- アップスケールされないため元の解像度のまま
- おすすめ:最終的に大きく表示・印刷したい画像ではオン推奨。
4. Rescaling Factor(リスケーリング倍率)
- 意味:画像全体をどの倍率でアップスケールするかを指定(最大4倍)。
- 例:
1.0→ 元の解像度のまま2.0→ 2倍サイズに拡大4.0→ 4倍サイズに拡大
- 注意:倍率を上げすぎると処理が重くなります。必要に応じて調整。
5. Codeformer Fidelity(忠実度)
- 意味:「元の顔にどれだけ似せるか」と「美化・修復」のバランスを指定。
- 数値の意味:
0.0→ 品質重視(高品質、美化されやすいが元顔とはやや異なる)1.0→ 忠実度重視(元の顔に近くなるが、ノイズも残りやすい)0.5→ 中間(ほどよいバランス)
- おすすめ:
- AIの美化を活かしたい →
0.0 ~ 0.3 - 元の顔の特徴を重視したい →
0.7 ~ 1.0
- AIの美化を活かしたい →
| パラメータ | 効果概要 | おすすめ設定例 |
|---|---|---|
| Pre Face Align | 顔の角度補正 | 斜め向きや歪んだ顔に有効 |
| Background Enhance | 背景も強調補正 | 風景や全体画像をキレイにしたい場合 |
| Face Upsample | 顔をさらに高解像度にする | 印刷・拡大用の画像で有効 |
| Rescaling Factor | アップスケール倍率(最大4倍) | 通常は 2.0〜4.0 まで |
| Codeformer Fidelity | 忠実度(0=美化、1=忠実) | 美化したいなら 0.2〜0.4、元顔重視なら0.8〜1.0 |
注意事項
- 待ち時間があるかも(人気なので並ぶことがある)
- アップロードする画像サイズは小さめ(できれば512px以内)がスムーズ
- あくまで「デモ版」だから、商用利用はNG(正式に使いたい場合は、クラウドGPUかローカルインストール)
もうちょっと高機能版を使いたい場合は、2⃣へ!
自分のPCでCodeFormer動かしたい場合は3⃣へ!
2⃣ 【やや中級者向け】クラウドで使う方法(ローカルGPU不要)
- Google Colabで使う方法
- Runpodで使う方法
➊ Google Colabで使う方法
Step.0必要なアカウントを用意します
CodeFormerをGoogle Colabで使うには、以下の2つの無料アカウントが必要です。
- Googleアカウント(Colab用)
- Hugging Faceアカウント(モデル取得用)
まだ作っていない方は、以下のリンクから登録を済ませましょう。
Step.1 Google Colabにアクセス
Googleアカウントがあれば誰でも使える「Google Colab」にアクセスします。
Google Colabはこちら
Googleアカウントでログイン
新しいノートブックを作成
Step.3 GPUを有効にする(これ超重要!)
CodeFormerは重いので、GPUを使う設定にしておきましょう!
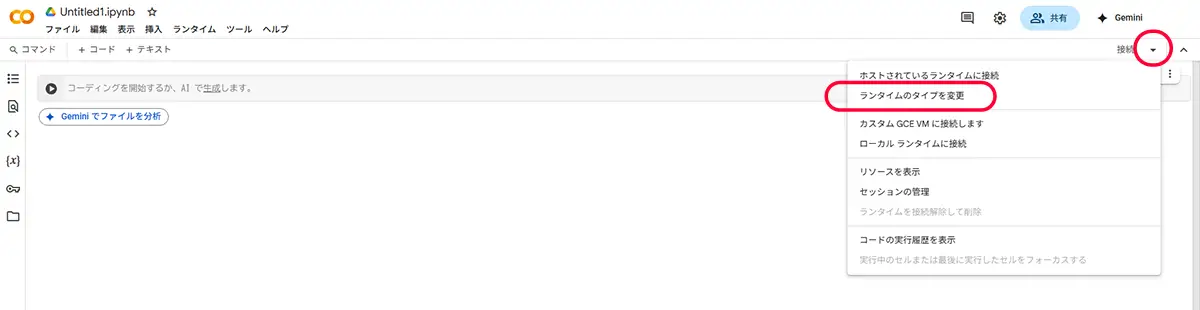
- メニューから「ランタイム」>「ランタイムのタイプを変更」を選択
- 「ハードウェアアクセラレータ」で「GPU」を選んで「保存」
これで、クラウド上のGPUが使える状態になりました!
Step.4Hugging FaceでCodeFormerを開く
- CodeFormerのページ にアクセス
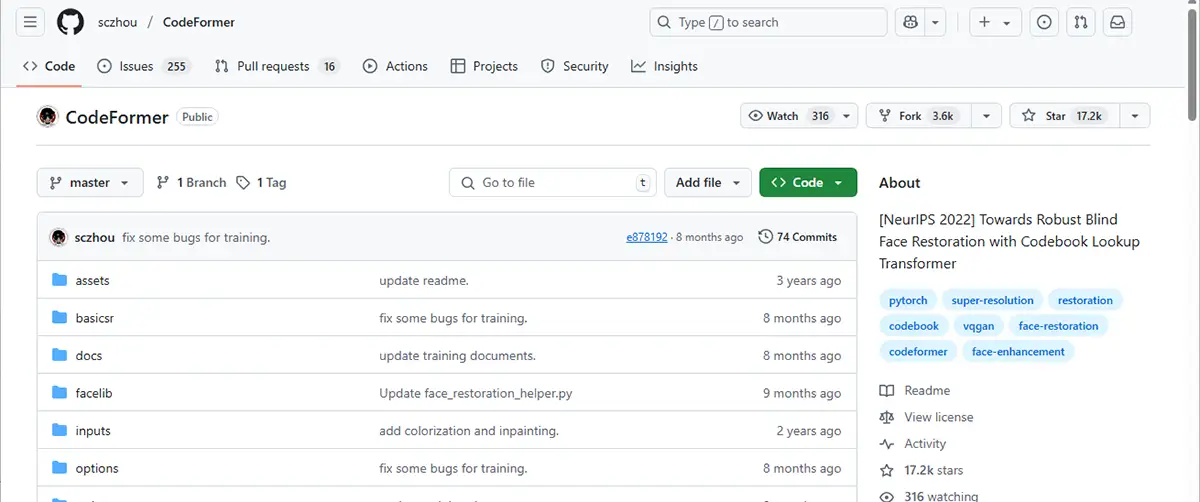
2. 「Open in Colab」をクリック(あるいはコードをコピーしてColabに貼り付け)
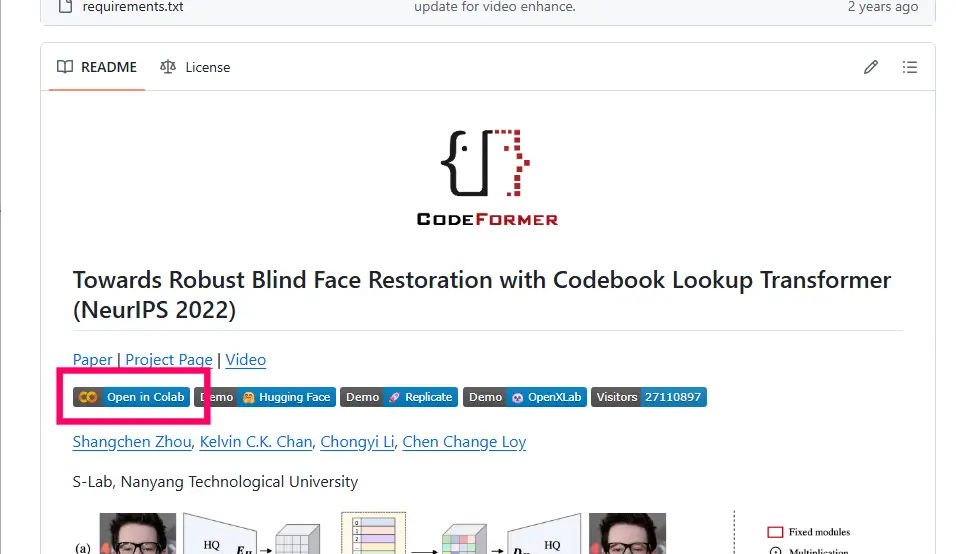
※このページはすでにインタラクティブなUIを提供しているので、Colab上での実行環境が構築されます。
ログインを求められた場合
from huggingface_hub import login
login()→ Hugging Faceのアクセストークンを入力(こちらから取得可能)
Step.5 画像をアップロードする
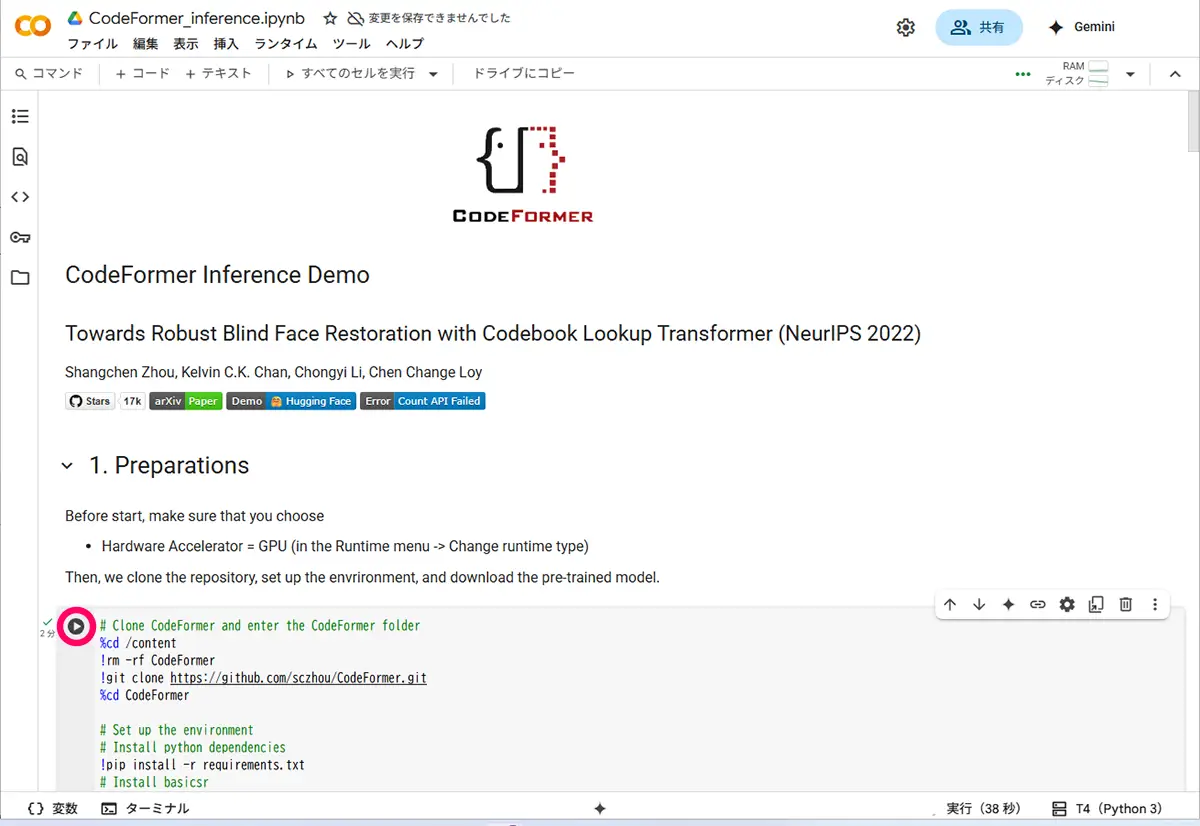
全て、▶ボタンを押して、実行していきます。
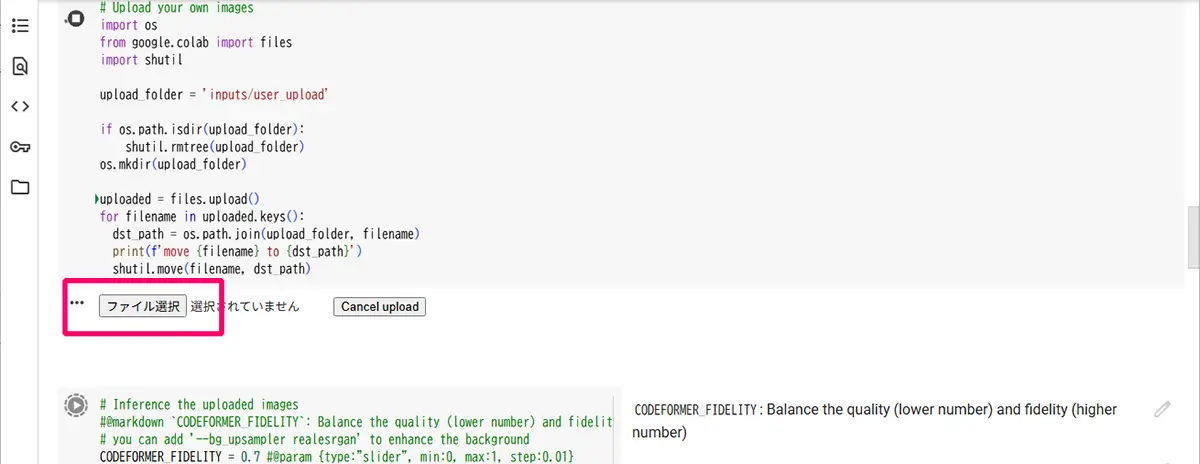
実行後、ファイル選択ダイアログが出るので、修復したい画像(顔写真など)を選んでください。
Step.6 画像をCodeFormerで修復(復元)する
次に、アップロードした画像を修復するコードです
# 復元実行(--w は復元の強さ、1.0=完全復元、0.7くらいが自然)
!python inference_codeformer.py --w 0.7 --input_path inputs/my_photo.jpg --bg_upsampler realesrgan⚠ my_photo.jpg は、アップロードしたファイル名に合わせて変更してください。
これで、アップロードした顔画像が補完・修復された状態で出てきます!
結果画像を表示するコード(オプション)
from IPython.display import Image, display
# 出力画像のパス(復元結果は results ディレクトリに保存される)
output_path = "results/final_results/my_photo.jpg"
# 表示
display(Image(output_path))この処理は、すでに以下が完了している前提です
- CodeFormerのクローンとインストール
- モデルファイル(
codeformer.pth)のダウンロード済み - Colabのカレントディレクトリが
CodeFormerにある
Step7 完成した画像をダウンロードする
最後に、出力画像(output.png)をダウンロードして保存できます!
files.download('output.png')Colabのセルのルール
1つのセルにまとめてもOK
ディレクトリ移動(%cd)をまたぐ場合は注意
セルを 2つに分けた方がミスが起きにくくておすすめ!
git clone GitHub から CodeFormer のコード一式を取得pip install -r依存ライブラリ(Pythonパッケージ)をインストールgit submodule updateCodeFormer内部で使っている別リポジトリも取得(face parsingなど)wget学習済みモデルファイル(.pth)を Hugging Face から取得inference_codeformer.py画像を読み込み、顔の復元処理を実行するメインスクリプト
※無料でGPUが使えるのが魅力!重い画像も快適処理。
google colabでエラーが出て使えない時と、Colab の無償枠で GPU 上限に達してしまったときの代替手段については、こちらの記事をご覧ください。
SAKASA AI
Google Colab エラー時の ランタイムリセット と ランタイム復旧【CodeFormerが使えない時】 | SAKASA AI Google Colabいくつかのエラーとランタイムの復旧 当記事は下記ページ【CodeFormerの使い方】のスポットライト記事として書いたものです。”Google Colab の使用方法”につい…
あわせて読みたい
Colab の無料枠制限で GPU 上限に達した場合の”回復までの時間”と”代替手段” 回復までの時間 Google Colab 無料枠の GPU 使用上限は時間が経つと回復します。ただし、その「回復までの時間」や「どれくらい使えるか」はユーザーごとに異なり、以下…
「CodeFormerを動かす為のまとめノートブック」を作る手順
同じ操作を繰り返したい場合は、まとめノートブックを作成しておくと実行ボタンのみを押すだけで、簡単に同じ操作を繰り返す事が出来ます。
作成方法は以下の通りです。
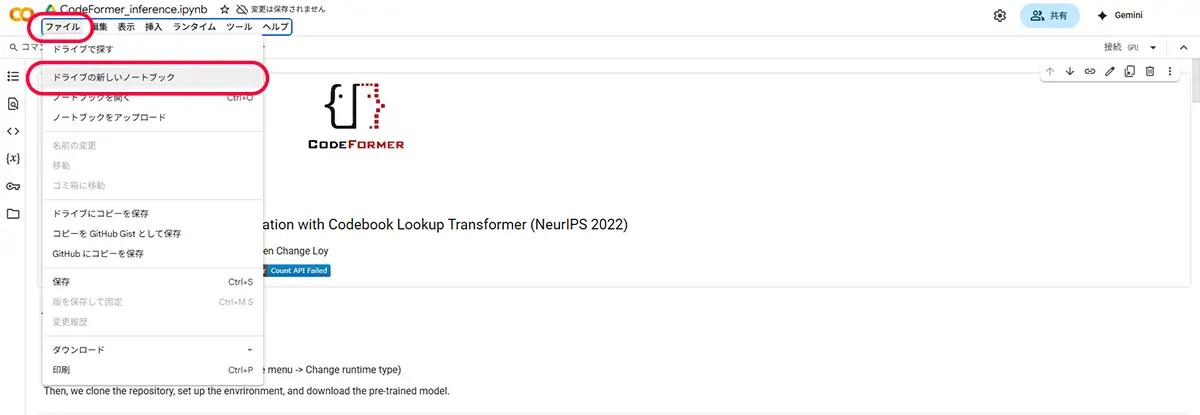
【STEP 1】新しいGoogle Colabノートブックを開こう!
まずは、
- Google Colab にアクセス
- 画面左上の「ファイル > 新しいノートブック」をクリック
すると、新しい空っぽのノートブックが開きます。
(名前は後でつければOKです)
順番にセルを作っていきましょう!
【STEP 2】最初のセルに書くコード
まずは「CodeFormerのソースコードをGitHubからダウンロード」してきます。
ノートブックの一番上のセルに、次のコードをコピペしてください
# CodeFormerをクローン
!git clone https://github.com/sczhou/CodeFormer.git
# CodeFormerフォルダに移動
%cd CodeFormer
# 必要なライブラリをインストール
!pip install -r requirements.txt
# さらに必要な依存ライブラリもインストール
!pip install -q basicsr facexlib gfpgan
!pip install -q -U openmim
!mim install -q mmcv-full左側の「▶️ボタン(セルを実行)」を押してください!
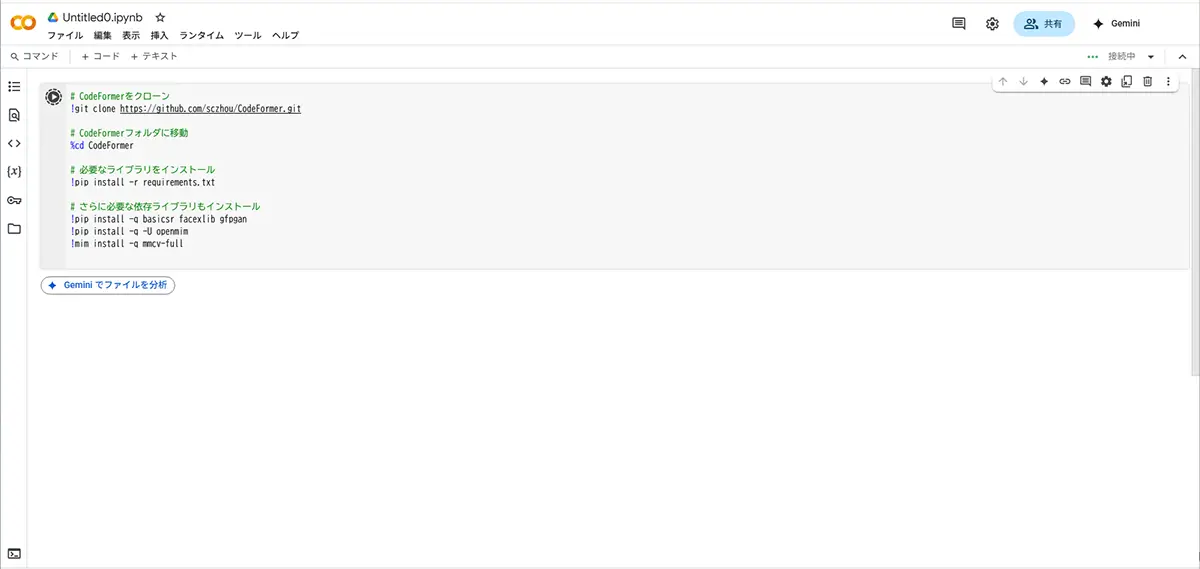
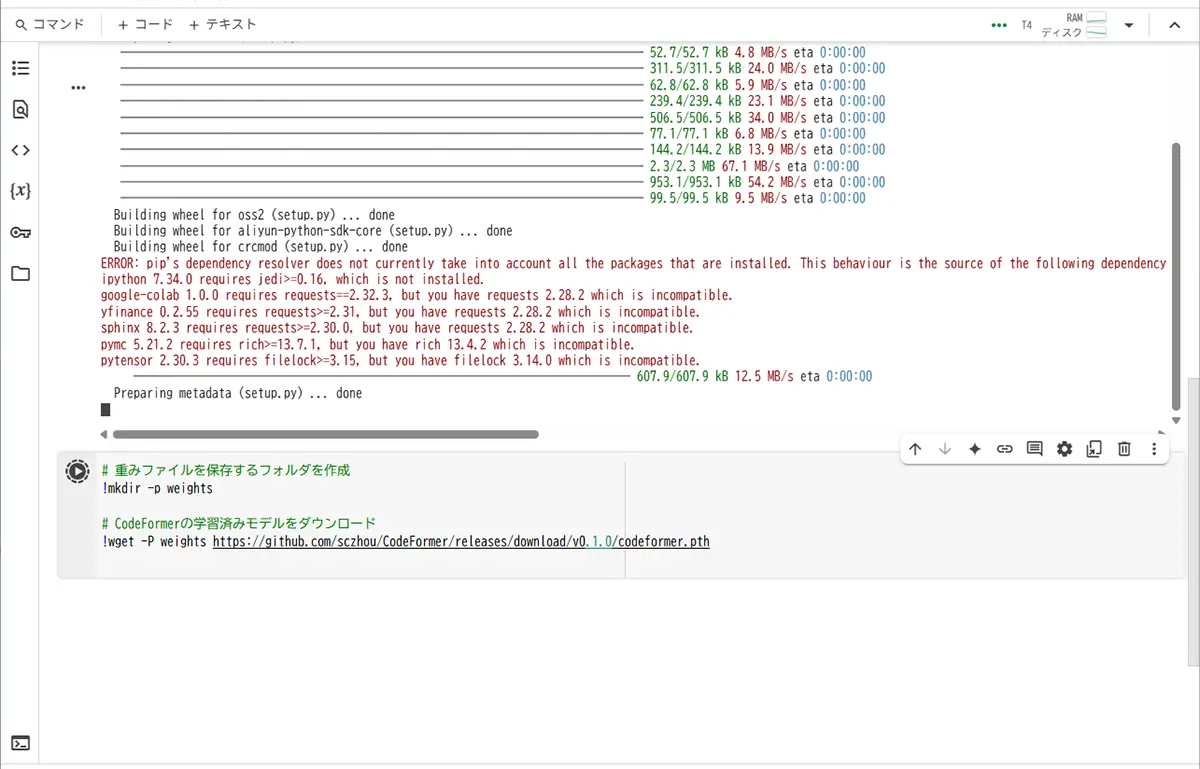
【STEP 3】事前学習モデル(重みファイル)をダウンロードするセル
次は、CodeFormerの学習済みモデル(codeformer.pth)をダウンロードするコードを書きます。
新しいセルを追加して、次をコピペしてください
# 重みファイルを保存するフォルダを作成
!mkdir -p weights
# CodeFormerの学習済みモデルをダウンロード
!wget -P weights https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/codeformer.pth【ポイント】
weightsというフォルダを作って、そこに保存します。- この「重み」がないと、顔修復ができないので必須です!
【やること】
- 新しいセルを追加して
- 上のコードを貼り付けて
- 「▶️」ボタンで実行!
ダウンロードする「学習済みモデル(codeformer.pth)」のサイズがけっこう大きい(数百MB以上ある)為、時間が掛かる場合があります。ColabのサーバーとGitHubの通信速度はそのときの回線状況に左右されます。
【目安時間】
- 早いとき ➔ 10秒〜30秒くらい
- 遅いとき ➔ 数分かかることもある
なので、のんびり待っていればOKです。
(途中でエラーが出なければ問題なし!)
【もし途中でエラーになったら?】
もし仮にダウンロード中にエラーが出ても、
もう一度「セルの▶️ボタンを押して再実行」すれば大丈夫です!
【STEP 4】画像をアップロードするセルを作ります!
Colab上に、CodeFormerで直したい自分の画像ファイルをアップロードする仕組みを作りましょう!
次のコードを新しいセルにコピペしてください
from google.colab import files
# ファイルアップロード
uploaded = files.upload()- 上のコードを貼り付けて
- ▶️ボタンを押します
すると、「ファイルを選んでください」というウィンドウが出るので、
手元にある顔画像ファイルを選んでアップロードしてみてください
【STEP 5】CodeFormerで画像補正を実行するセル
次のコードを、新しいセルに貼り付けてください
# 推論に必要なモジュールをインポート
import torch
from torchvision.utils import save_image
from basicsr.archs.codeformer_arch import CodeFormer
from torchvision import transforms
from PIL import Image
import os
# CodeFormerモデルの準備
net = CodeFormer(dim_embd=512, codebook_size=1024, n_heads=8, n_layers=9, connect_list=["32", "64", "128", "256"])
ckpt_path = 'weights/codeformer.pth'
net.load_state_dict(torch.load(ckpt_path)['params_ema'])
net = net.eval().cuda()
# アップロードしたファイル名を取得
filename = list(uploaded.keys())[0]
# 画像の読み込みと前処理
img = Image.open(filename).convert("RGB")
transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor()
])
img_input = transform(img).unsqueeze(0).cuda()
# 顔補正を実行
with torch.no_grad():
output = net(img_input, w=0.7, adain=True)[0]
output = (output.clamp(-1, 1) + 1) / 2
# 結果を保存
save_image(output, 'restored_image.png')
# 画像を表示
from IPython.display import Image as IPImage, display
display(IPImage('restored_image.png'))
CodeFormerモデルをロードしてアップロードした画像を読み込んで顔をきれいに復元(補正)して結果を表示&保存する
【注意点】
保存されたファイル名は restored_image.png になります!
最初にアップロードした画像ファイル名が自動で使われます。
このようなエラーが出た場合
ModuleNotFoundError: No module named 'basicsr'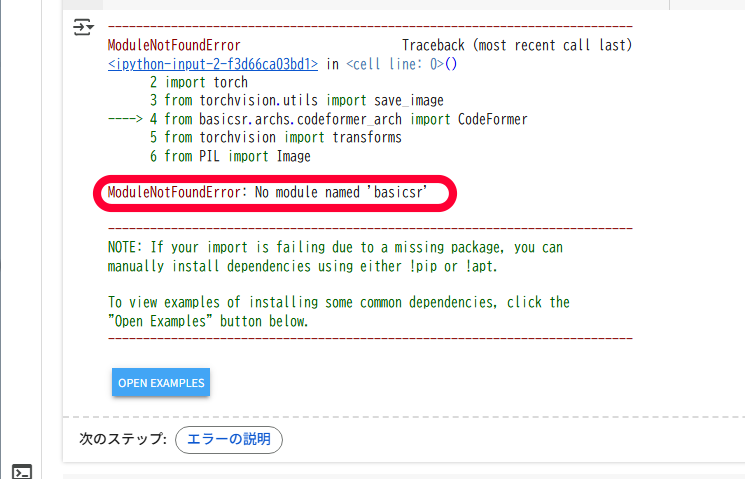
次のコマンドを新しいセルにコピペして、実行してください
!pip install basicsrこれでbasicsrがインストールされます!
(この作業は、Colabを新しく開いたときは毎回やる必要があります)インストールが終了したら、一度画面左上のランタイムのタブをクリックして、セッションを再起動をして下さい。
このようなエラーが出た場合
ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor'これは、今インストールされてる「torchvision」のバージョンが低すぎて、必要な機能がない場合のエラーです。
次のコマンドを新しいセルにコピペして、実行してください
!pip install torchvision --upgradeこれで、最新の torchvision にアップデートできます。
❷ Runpodで使う方法
安定利用出来てGPUが選べる、クラウドGPUレンタルの、RunPodで
- Stable Diffusionテンプレート(A1111など)を使用し、WebUI(ブラウザ)でCodeFormerを使用するという方法や、
- ComfyUIテンプレートに、CodeFormerを組み込んでワークフローを自動化する方法があります。
特に、Stable Diffusioテンプレート(A1111など)を使用する方法は、テンプレート選択後、数クリックで使用でき、
同時にReal-ESRGAN(顔だけでなく衣服や背景も補正したい場合)なども併用可能です。
これらは、「顔補正(Face Restoration)」機能の一部として搭載されています。
Stable Diffusion(A1111)では、「Extras」タブや「img2img」タブなどで、Restore faces にチェックを入れると、内部的に CodeFormer または GFPGAN が使われます。
又、CodeFormerで物足りない人向け、次世代の顔補正ツールの、FaceRestore や FaceFusionなどのテンプレートも使用できます。
RunPodについては、こちらの記事で解説しています。
あわせて読みたい
【RunPodの料金と使い方】Stable Diffusionなどで画像生成やLoRA学習をする方法【②実践編】 RunpodでStable Diffusion系画像生成やLoRA学習をする方法 Stable DiffusionやLoRA学習では、長時間GPUをフル稼働させるため、発熱や電源の安定性が大きな課題になりま…
3⃣【上級者向け】ローカルPCに導入して使う方法
使用方法は二通りあります。
- Automatic1111 や ComfyUI などの GUI ツールに組み込んで使う方法
- コマンドを使用してクローン、使用する方法
➊ Automatic1111 や ComfyUI などの GUI ツールに組み込んで使う方法
Automatic1111 や ComfyUI などの GUI ツールに組み込んで使う場合、CodeFormerだけを使用する分には、CPUだけでも動きはするという表現が正しいようです。
A1111もComfyUIもGPU前提で最適化されている為、推論がGPUの100〜300倍遅いようですので、ローカルPC(自分のPC)にGPUが無い(又は、スペックが低い)場合は、
2⃣ 【やや中級者向け】クラウドで使う方法(ローカルGPU不要)/ ❷ Runpodで使う方法で解説している方法でのご使用がおすすめです。
※ Automatic1111 や ComfyUI などの GUI ツールに組み込んで使う際には、Automatic1111 や ComfyUI などの GUI ツールは、別途必用です。
Automatic1111のインストールと使用方法
WebUI(AUTOMATIC1111)の【インストール方法】【拡張機能インストール】【エラー対処法】 WebUI(Webユーザーインターフェース)とは、ブラウザを通じて操作できるユーザーインターフェースのことです。特にStable Diffusionでは、WebUIを使うことで専門的なコ…
ComfyUIのインストールと使用方法
ComfyUIとは?Stable Diffusion 各モデルの特徴・用途・対応ツールのインストールと使い方 ComfyUIの使い方 Stable Diffusionの代表的WebUI「AUTOMATIC1111」に続き、InvokeAIやForgeも人気が急上昇。しかし、最も高機能なツールとして注目されるのは、自由自在…
CodeFormer の導入・利用手順
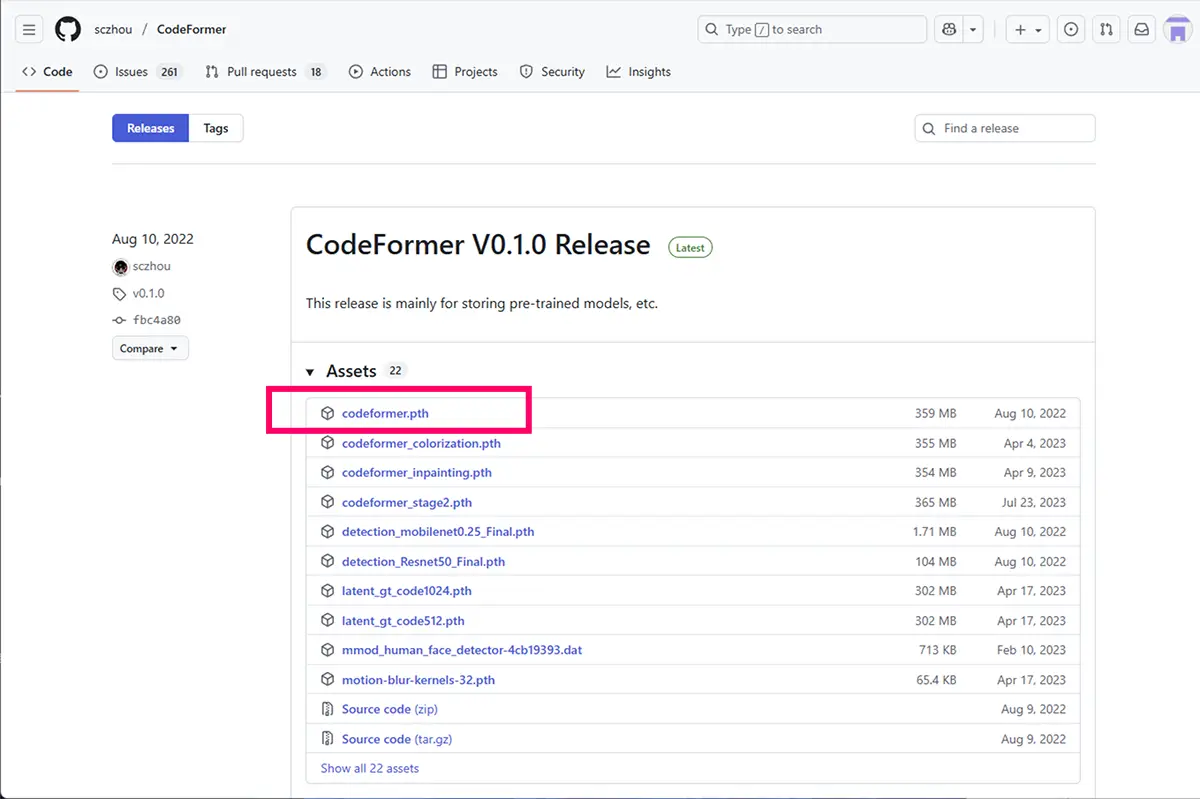
STEP
学習済みモデルをダウンロード
CodeFormer.pth ファイルをダウンロード
サイズ:約 359 MB
注意:他のオプション(colorization / inpainting 等)は必要に応じて追加でダウンロード可
STEP
ファイルを配置
A. Automatic1111 で使う場合
models/CodeFormer フォルダを作成
AUTOMATIC1111 フォルダ
└─ models
└─ CodeFormer
└─ CodeFormer.pthAutomatic1111 を起動
- 「Extras → CodeFormer」の設定で
CodeFormer.pthを選択すれば読み込み可能
B. ComfyUI で使う場合
ComfyUI フォルダ内に 任意のフォルダを作成
ComfyUI/
└─ models/
└─ CodeFormer/
└─ CodeFormer.pthComfyUI の「Face Restore」ノードで パスを指定
CodeFormer.pthを直接指定するだけで利用可能weights/フォルダを作る必要はなく、任意の場所から読み込み可能
ノードのパラメータ(Strength など)を調整して補正実行
STEP
UI画面を開く
A. Automatic1111 で使う場合
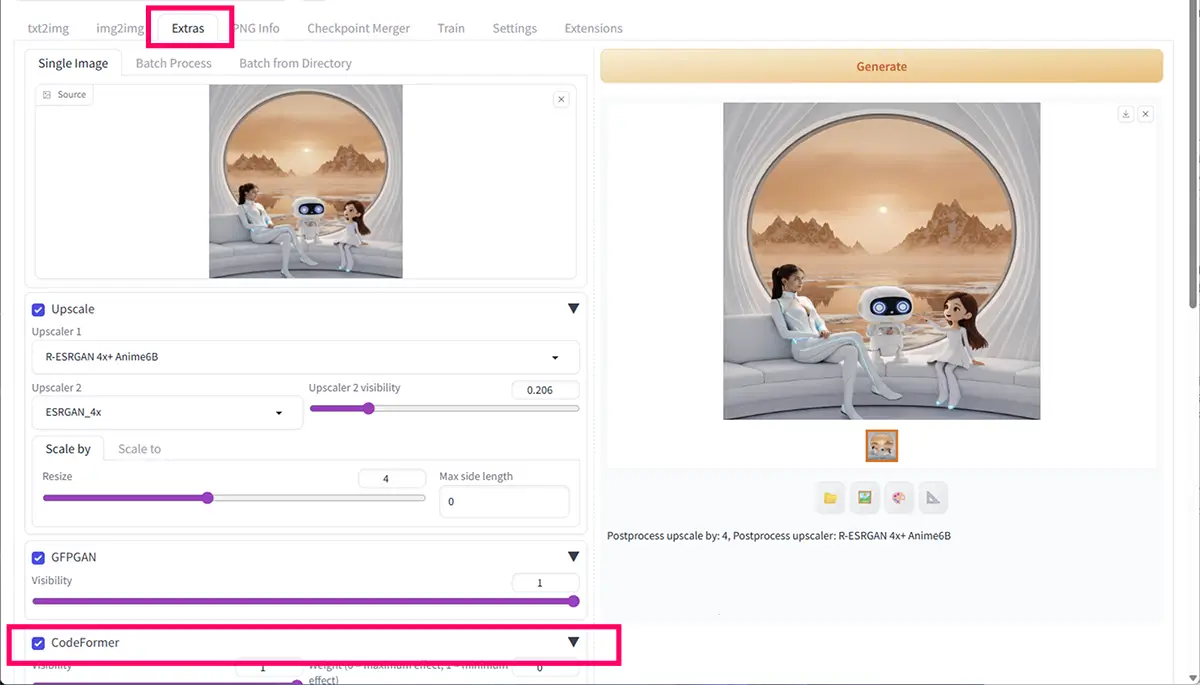
Extras内でモデルが認識されたら、顔補正(Face Restore)に使用可能
| 項目 | 現状 | 調整の目安 |
|---|---|---|
| Visibility | 1 | 1 が最大効果。強すぎると顔が固くなることがあるので 0.5〜0.7 くらいで自然な修正に |
| Weight | 0 | 0 が最大効果(=CodeFormer が顔を強く修正)。柔らかくしたい場合は 0.3〜0.5 がおすすめ |
B. ComfyUI で使う場合
ノードのパラメータ(Strength など)を調整して補正実行
A1111 / ComfyUI で使用する場合は、 以下の様に、Upscale や GFPGAN と組み合わせると
より自然な仕上がりになります。
Automatic1111で Upscale や GFPGAN と組み合わせる方法
SAKASA AI
Automatic1111での画像の修復とアップスケールをする方法 | SAKASA AI A1111での顔画像と画像全体の修復、アップスケールの方法 GFPGAN(顔修復・補正モデル) — GitHubリポジトリ: https://github.com/TencentARC/GFPGAN GitHub CodeFormer(…
❷ コマンドで使用する方法
【CodeFormerをローカルで使うためのPC環境】
- 対応OS
- Windows 11
- macOS(Intel or Apple Silicon)
- Linux(Ubuntu推奨)
※ただし、GPU処理(高速動作)したい場合はWindows or Linuxを強く推奨。
【Python・CUDA環境】
| 項目 | 内容 |
|---|---|
| Python | 3.8 〜 3.10(Python 3.11は非推奨)※手動で事前にインストールが必要ですPython のインストール手順はこちら |
| CUDA Toolkit | 11.3 〜 11.7(GPUを使う場合)※詳しくは、下の記事の中で書いています。 |
| PyTorch | CUDA対応版をインストール(後述)【PyTorch+CUDA】のインストール手順 |
| Git | GitHubからコードを取得するために必要※手動で事前にインストールが必要ですGitのインストール手順はこちら |
【PCスペック】
| スペック項目 | 最低要件 | 推奨要件 |
|---|---|---|
| CPU | Intel Core i5 / AMD Ryzen 5 以上 | Core i7 / Ryzen 7 以上 |
| メモリ(RAM) | 4GB | 6~8GB (入力画像の解像度が非常に大きい(4K〜8K)場合) |
| GPU(NVIDIA製) | GeForce GTX 1060 以上(VRAM 6GB〜) | RTX 3060 / 3070 / 4070(VRAM 8GB〜)以上 |
GPUはCUDA対応のNVIDIA製が必須です。無い場合は(2⃣ 【やや中級者向け】クラウドで使う方法(ローカルGPU不要)をお試しください。)
AIツールに適したGPUの選び方
【2026年】AI画像生成に最適なGPU比較:RTX4060~5090【SD/LoRA/ControlNet対応】 画像生成AIを使いたい!GPUは何を選べばいい? Stable DiffusionやComfyUIで画像生成に挑戦したい――そう思ったとき、最初に立ちはだかる壁が「GPU選び」ではないでしょ…
GPUがないとどうなる?
- CPUでも動作はしますが「1枚の画像処理に数分〜十数分かかる」こともあります。
- GPUがあると「数秒〜十数秒で処理完了」なので、作業効率が段違いです。
手順
- CodeFormerのソースコードをGitHubから取得Git公式サイト
まずは公式GitHubリポジトリをクローンします
git clone https://github.com/sczhou/CodeFormer.git
cd CodeFormer2.仮想環境(venv)を推奨
python -m venv codeformer-env
source codeformer-env/bin/activate # macOS/Linux
codeformer-env\Scripts\activate # WindowsmacOS/Linuxは、1,2段目を使用してください。
Windowsの方は、1,3段目のコマンドを使用してくださいね。
3、依存パッケージのインストール
以下で、必要なPythonライブラリをまとめてインストールします。
pip install -r requirements.txtこのコマンドは、requirements.txt に書かれている依存ライブラリ(例:torch, opencv-pythonなど)を一括でインストールします。
もし依存関係でエラーが出る場合は、torch を手動でインストールすることもあります
pip install torch torchvision torchaudio※ GPU を使うなら、PyTorch の公式サイト(https://pytorch.org/get-started/locally/)で適切なバージョンを選んでインストールしましょう。
について,
以下の記事で詳しく解説していますので、ご覧ください。
SAKASA AI
ローカルCLI(Pythonスクリプト)の為の【PyTorch+CUDA】のインストール手順 | SAKASA AI PyTorch + CUDA のインストール GPUとCUDAの互換性を確認する方法 PyTorch・Stable Diffusion・ComfyUI など、GPUを使うAIツールを動かすときは「GPUがCUDAに対応している…
4,事前学習済みモデル(CodeFormer.pth)を以下のURLから CodeFormer.pth をダウンロード
https://github.com/sczhou/CodeFormer/releases
以下のように配置します。
CodeFormer/
└── weights/
└── codeformer.pthcodeFormer/weights/codeFormer.pth というファイルパスになるように置きます。
ダウンロード後のファイル配置の仕方
ダウンロードした CodeFormer.pth を、現在の作業ディレクトリ(例:CodeFormer フォルダ内)に置いておく方法です。
例 Windows(PowerShellやコマンドプロンプト)の場合
mkdir weights\CodeFormer
move CodeFormer.pth weights\CodeFormer\例(Linux/macOSの場合)
mkdir -p weights/CodeFormer
mv CodeFormer.pth weights/CodeFormer/このコマンドによりweights/CodeFormer/CodeFormer.pth という必要なパスにモデルファイルが移動します。
なぜこの場所に配置する必要があるのか?inference_codeformer.py やその他のスクリプト内で
os.path.join('weights/CodeFormer', 'CodeFormer.pth')といったように、決められた場所からモデルを読み込む設計になっているからです。
テスト画像で動作確認
例として、画像 input.jpg を補正してみます。
python inference_codeformer.py -w 1.0 --input_path ./inputs/input.jpg --face_upsample解説
-w 1.0: 再構成の重み(0〜1。1は構造重視、0は画質重視)数値が大きいほど「顔の再構成を強めに」行う(=リアルさ重視)--input_path: 入力ファイルまたはフォルダのパス
画像1枚ならxxx.jpg、フォルダ指定も可能(複数処理)--face_upsample: 顔だけでなく背景も一緒に超解像したい場合に指定(任意)--bg_upsampler:Real-ESRGANなどの背景用アップサンプラー(オプション)--output_path:出力先のパス(省略可。デフォルトはresults/フォルダ)
例:画像1枚を処理する場合
画像構成(例)
CodeFormer/
├── inference_codeformer.py
├── inputs/
│ └── face.jpg
├── weights/
│ └── CodeFormer/
│ └── CodeFormer.pth実行コマンド:
python inference_codeformer.py -w 1.0 --input_path inputs/face.jpg --face_upsample --output_path outputs/この例では:
inputs/face.jpgを処理- 結果が
outputs/フォルダに保存される(自動で作成される)
フォルダごと一括処理する場合
python inference_codeformer.py -w 1.0 --input_path inputs/ --face_upsample --output_path outputs/inputs/ 内にある全画像(JPG, PNG)を一括処理して、outputs/ に出力します。
出力ファイルについて
実行後、指定した --output_path に以下のようなファイルが生成されます
final_results: 修復後の最終画像(背景込み)restored_faces: 修復された顔の部分(切り出し)
補足オプション(任意)
| オプション | 説明 |
|---|---|
--bg_upsampler realesrgan | 背景に Real-ESRGAN を使ってアップサンプリングする(別途インストール必要) |
--only_center_face | 中心の顔だけ処理(集合写真などで便利) |
--draw_box | 顔の検出領域を四角で描画(デバッグ用) |
注意点
ファイル名に日本語や全角文字があると処理に失敗する場合があります。
複数画像の一括処理では、画像形式は .jpg, .png などが対応(.webp などは注意)。
Web UIで試す方法
CodeFormer には簡易Web UI(gradio)も用意されています
python basicsr/tools/webcam_demo.py※ gradio を追加でインストールする必要があります
pip install gradio実行!画像を指定して処理を開始
例:
python inference_codeformer.py --w 0.7 --input_path inputs/test.jpg --output_path results/--w パラメータは「どれくらいAI補正するか(0〜1)」を指定します。0に近いと原画寄り、1に近いと修正が強くなります。
出力結果は results/ フォルダに保存されます。
GPU環境があれば高速ですが、CPUでも動作は可能です(ただし時間がかかります)。
おすすめ設定とコツ
| パラメータ | 説明 | おすすめ値 |
|---|---|---|
w | 補完の強さ(0〜1) | 0.5〜0.7くらいが自然 |
| 画像サイズ | 小さすぎると補完しきれない | 顔が100px以上推奨 |
どんな画像に向いてる?
イラストよりは「写真風」向き(リアル寄りの顔)
AI画像で顔が「崩れがち」なときの補修に最適
特に「顔だけ浮いてる画像」や「古い写真」が得意分野です!
顔だけなの?
CodeFormerは 全体の画像ではなく「顔部分のみ」に特化 しています。
顔以外の補完は別のツール(例:Real-ESRGANなど)と組み合わせるのがおすすめです。
あわせて読みたい
Real-ESRGAN と GFPGANを連携させる方法とGUIで使えるツール Real-ESRGAN と GFPGAN Real-ESRGAN(リアル・イーエスアールガン)と GFPGAN (ジーエフピーガン)は、インストール手順や使い方が、かなり似ています。両方とも Tence…
あわせて読みたい
【GFPGANのインストール方法と使い方】と【Automatic1111で使用する方法】 GFPGANとは? GFPGAN(Generative Facial Prior GAN)は、顔画像に特化した、顔復元のためのツールです。リアルな仕上がりで古い写真の再生に最適なツールです。顔以外の…
SAKASA AI
【Upscaylのダウンロードと使い方】アップスケーラーを使って画像を簡単に高画質化する方法 | SAKASA AI Upscayl/Real-ESRGANの使い方 本記事では、Upscaylを使って簡単に画像を高解像度化する方法についてて解説しています。 Upscaylとは Upscaylとは既存の高性能モデル(主に…