【ControlNetの使い方】完全ガイド|線画・ポーズ・輪郭で思い通りに画像生成する方法


ControlNetは、「拡張機能・追加機能」です。
ControlNet自体はStable Diffusionに、条件(姿勢・線画・輪郭など)を与えて画像生成をコントロールするためのモデルや技術群で、単体で動かすことはできません。
そのため、Stable Diffusion本体や対応するUI(例:WebUI、ComfyUI、Diffusersなど)と組み合わせて初めて利用可能になります。
導入や操作にはある程度の知識が求められますが、上手く活用すれば、線画やポーズ、深度情報などからより狙い通りの画像生成ができるようになります。
 未来
未来この記事では、ControlNetの基本と、各UI環境での使い方の違い、代表的なモデル(例:線画用、ポーズ用など)の特徴について紹介しています。
目次
ControlNetでできる主なこと
ControlNet は、元画像から骨格や構図、線画などの構造情報を抽出し、それをもとに Stable Diffusion などの生成モデルで二次制作や加工を行うための補助ツールです。
生成のスタイルやディテールは元のモデル(SDなど)が担当し、ControlNet はあくまで「構造の制御」を行います。
ポーズ指定
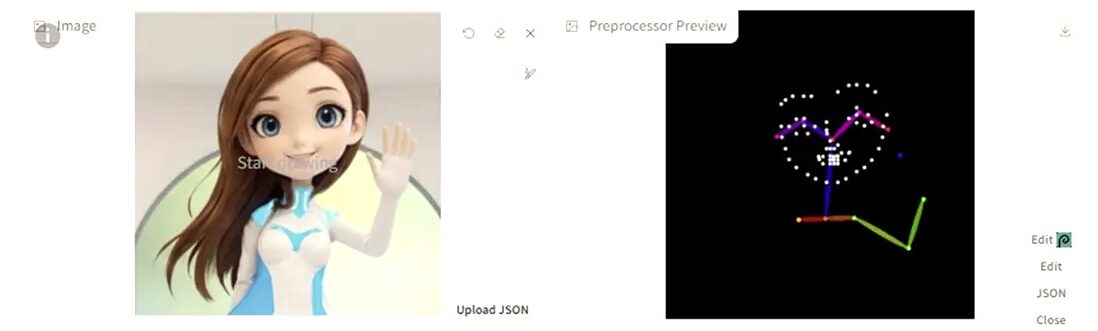
- OpenPose モジュールを使って、人やキャラクターのポーズを指定できます。
- 写真やイラストから骨格を抽出して、そのまま別のキャラや衣装で再現可能。
- 例:自分で撮った立ちポーズ写真を使って、アニメキャラ化。
構図や輪郭の保持
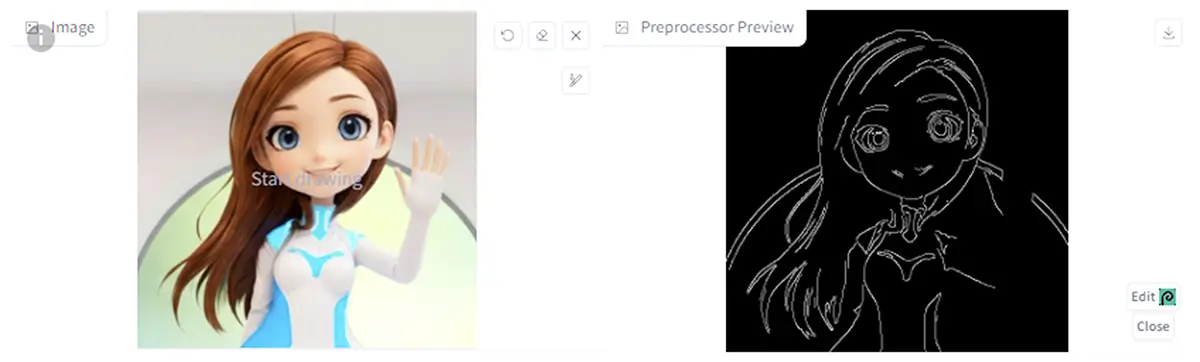
- Canny や MLSD(直線検出) を使い、建物や背景の線構造を保ちながら別の雰囲気に描き直す。
- 例:街並みの写真をファンタジー背景に変換。
深度情報による立体感の保持

- Depth モジュールで距離感・奥行きを推定し、それを生成に反映。
- 例:普通の風景写真を、光の演出や別の世界観に差し替えても立体感が残る。
セグメンテーションによる領域別変換

- Segmentation モジュールで画像を色分けマスク化し、部分ごとに違う質感や色を適用できます。
- 例:人物はそのまま、背景だけ別のテイストに変更。
スケッチや落書きからの清書

- Scribble モジュールを使ってラフな手描き線画から完成イラスト化。
- 例:マウスで簡単に描いたキャラを、アニメ風の全身イラストにする。
写真の構図トレース
- 元写真を下敷きにして、新しい被写体で同じカメラアングル・構図を再現。
- 例:自分の机の写真を元に、アニメの部屋シーンに置き換え。
衣装や髪型の差し替え
- OpenPoseやDepthと組み合わせ、ポーズやシルエットを変えずに衣装だけ変える。
- 例:同じ人物に季節ごとの服装を着せる。
背景の生成統一
- DepthやSegmentationで背景の構造を固定して、複数カットを同じ雰囲気で生成。
- 例:同じ街並みを昼・夜・雨バージョンで生成。
モーションやアニメ生成の下準備
- 動画の各フレームに対してポーズやDepthを適用し、統一感のある動きのある絵を作成。
- 例:短いアニメやGIF用のフレーム生成。
各環境でのControlNetの使い方
ControlNetを使える環境は大きく以下の3通りあります。
- Hugging Face Spacesは、単純にControlNetの機能を試したい場合に使えます。
- ローカル(自身のPC)での使用方法は、ご自身のA1111や、ComfyUIに組み込んで使用する方法です。
- クラウドGPU(*Colab, **RunPodなど)での使用は、自身のPCが重たい場合やGPUが無い場合などに、クラウドGPU内の、A1111や、ComfyUIのテンプレートを用いて使用する方法です。
1. Hugging Face Spacesでの使用
最も、手軽に使用できる方法です。ControlNetを使用出来るモデルは多く存在します。

こちらの、lllyasviel/control_v11p_sd15s2_lineart_animeは、ControlNet 用のチェックポイントモデルの一つで、Stable Diffusion 1.5 向けに調整された 「線画アニメ用」のControlNetモデルです。
あわせて読みたい
ControlNet V1.1 – a Hugging Face Space by hysts This app lets you upload a picture and a guide such as an edge map, sketch, depth map, or pose, then creates a new image that follows that guide. Choose the typ…
- Spaces(例:ControlNet on Diffusers)などでは、GUIで操作できる簡易なツールが提供されています。
- あらかじめControlNetが組み込まれており、タブで切り替えるだけで使えます。
- 単体アプリのように見えますが、裏側でDiffusers + ControlNetが動いています。
あわせて読みたい
Hugging Faceとは?AIモデルの探し方・認証モデルの使い方を初心者向けに解説【2026年版】 Hugging Faceとは? FLUX・WAN・Qwen・Stable Diffusionなど、現在の画像・動画生成AIの多くは、Hugging Face 上で公開・配布されています。 ComfyUIやRunPodを使い始め…
2. ローカル(自身のPC)での使用
ローカルで使用する場合は、あらかじめ Automatic1111やComfyUIなどをインストールしておく必要があります。(※後ほど解説しています。)
ControlNetをStable Diffusion WebUIで使う場合のVRAM最低条件は、「モデルの種類」「解像度」「ControlNetの数」によってかなり変わります。
※以下の条件に満たない場合は、3. クラウドGPU(*Colab, **RunPodなど)での使用で使用する方法があります。
1. ベース条件(Stable Diffusion本体のみ)
- SD1.5(512×512) … 最低 4GB(ただし実用は6GB以上)
- SDXL(1024×1024) … 最低 8GB(実用は12GB以上)
2. ControlNet追加時の目安
ControlNetは「ベースモデルとは別に追加で重いモデルを読み込む」ので、VRAMが一気に増えます。
| ベースモデル | **ControlNet数 | 最低VRAM | 実用VRAM(余裕あり) |
|---|---|---|---|
| SD1.5 | 1 | 6GB | 8GB以上 |
| SD1.5 | 2 | 8GB | 10GB以上 |
| SDXL | 1 | 10GB | 12GB以上 |
| SDXL | 2 | 12GB | 16GB以上 |
**ControlNet数…デフォルトのスロット数は3です。最大3本(スロット3つ) まで同時使用できます。
ControlNetは「ユニット(スロット)」ごとに別の補助モデルを読み込みます。
例:
1本(ユニット1つ)
- ControlNet 0:Lineartモデル
→ 線画だけを元に生成
2本(ユニット2つ)
- ControlNet 0:Lineartモデル(形を指定)
- ControlNet 1:OpenPoseモデル(ポーズを指定)
→ 形もポーズも固定して生成
3本以上
- ControlNet 0:OpenPose
- ControlNet 1:Canny(輪郭)
- ControlNet 2:Depth(奥行き)
→ 複数の構造情報を組み合わせて生成
⚠️ VRAMに与える影響
1本ごとに別のモデルをメモリに読み込むため、ControlNetの本数が増えるほどVRAM使用量も増えます。
特にSDXLは1本で約2GB〜4GBのVRAM追加消費があるので、複数本使うとすぐに限界に達します。
あわせて読みたい
【2026年】AI画像生成GPU おすすめ比較|RTX4060〜5090・5060Ti【Stable Diffusion・ComfyUI・LoRA対応】 画像・動画生成AIを使いたい!GPUは何を選べばいい? Stable DiffusionやComfyUIで画像生成に挑戦したい――そう思ったとき、最初に立ちはだかる壁が「GPU選び」ではない…
3. クラウドGPU(*Colab, **RunPodなど)での使用
クラウドGPU(*Colab, **RunPodなど)では、テンプレートを使用すれば簡単に、HuggingFaceと同じようなGUIを自分で立てられます。
Automatic1111やComfyUI内で使用します。
*Colab
Colabの無料版ではControlNetの使用はかなり制限されますControlNetは、追加の条件付きモデル(Canny, Pose, Depth など)と、エッジ検出などの前処理を行うため、VRAM(GPUメモリ)を大量に消費する拡張機能です。その為、Colab Pro(月額約1,300円〜)での使用となります。
| 項目 | Colab 無料版 | Colab Pro(有料) |
|---|---|---|
| VRAM容量 | 実質7〜10GB程度 | 最大24GB程度 |
| ControlNet使用 | ❌ 困難 | ✅ 制限付きで可能 |
| 複数ControlNet | ❌ 無理 | △ 状況により可 |
| SDXL + ControlNet | ❌ 起動不可が多い | △ 条件付きで可能 |
**RunPod
時間課金型のクラウドGPU。ControlNet対応テンプレートも充実しています。
未来クラウドならRunpodがおすすめ!
Runpodについてはこちらの記事でご紹介しています
【Runpodの料金と使い方と注意点】ComfyUI・Stable Diffusion・LoRA学習|2026年最新版【②実践編】 Runpodの料金と画像生成や動画生成、LoRA学習をする方法(2026年6月時点) 最近の生成AIは、VRAMやGPU性能を大きく要求するため、ローカル環境だけでは限界を感じやすく…
RunPodでの4090以上クラスのGPU比較
| GPU | VRAM | 性能(SDXL生成速度) | ControlNet適性 | 備考 |
|---|---|---|---|---|
| RTX 4090 | 24GB | 約1.5〜2倍速(RTX 3090比) | ControlNet 3本まで余裕 | 最もコスパ良い最上位。電力効率◎ |
| RTX 5090 | 32GB | RTX 4090より約20〜35%高速 | ControlNet 5本まで可能 | 新しいので、使用不可なテンプレートあり |
| RTX 6000 Ada | 48GB | RTX 4090とほぼ同速 | ControlNet 5本以上も可能 | VRAMが倍、巨大モデルや超高解像度向け |
| A6000 (Ampere) | 48GB | 3090より少し速い | 大型モデル安定運用 | 値段高め、消費電力大きめ |
| A100 40GB/80GB | 40〜80GB | SD用では遅め | 巨大学習モデル特化 | 推論より学習向き |
| H100 | 80GB | 最速クラス | オーバースペック気味 | 価格が非常に高い |
- RTX 4090(24GB)
- SDXL + ControlNet 3本 + 高解像度(1024〜1536px)でも安定
- コスパ最強(RunPod時間単価も安い)
- 超高解像度(4K〜8K)やControlNet4本以上を常用 → RTX 6000 Ada(48GB)
- LoRA/大規模モデルの学習やバッチ生成 → A100 / H100
ローカル、クラウドとHugging Faceの違い
| 項目 | ローカル/クラウドでの使用 | Hugging Faceでの使用 |
|---|---|---|
| モデル選択 | 自由に選べる(SD1.5、SDXL、LoRAなど) | 多くは固定(例:SD1.5固定) |
| 追加LoRAなど | 自分で追加できる | 制限あり |
| Preprocessorの数 | 全部入りや拡張可能 | 制作者選定のみ |
| 再生成など | 自由に調整可能 | 制限あり(回数・サイズなど) |
ControlNetの主な機能(モデル名と特徴)
ControlNetベース*プリプロセッサの機能を簡潔に解説します。
それぞれ、画像の特徴を抽出して、それを元に画像を生成するタイプが異なります。
**プリプロセッサ(Preprocessor)は「前処理をするAIモデル」で、画像から 姿勢や輪郭などの特徴を取り出す 専用のツールです。
抽出された「姿勢情報」や「輪郭情報」を使って、Stable Diffusionで「ポーズを真似した新しい画像」や「輪郭に沿ったイラスト」を二次生成します。
- 「線画」から塗り絵のようにしたい → Lineart
- 「ポーズ」だけ再現して違うキャラにしたい → OpenPose
- 「絵っぽく」したいけど構図や遠近感を保ちたい → Depth + Guidance
| *プリプロセッサ(タブ名) | 内容 |
|---|---|
| Canny | エッジ検出(輪郭線)。比較的安定して使える基本タイプ |
| MLSD | 直線検出(建物や背景など直線が多い画像向け) |
| Scribble | 手描きのラフな線画(指示的落書き)をもとに生成 |
| Scribble interactive | Scribbleの対話型。ブラウザ上で落書きが可能 |
| SoftEdge | Cannyよりも柔らかくて滑らかな輪郭線抽出 |
| Openpose | 人物のポーズ(骨格)を抽出。キャラポーズ指定に最適 |
| Segmentation | 背景・人物・服などを色分けし領域抽出 |
| Depth | 被写体の奥行き情報をもとに立体感ある画像を生成 |
| Normal map | 表面の凹凸(3D的構造)を元にした変換 |
| Lineart | アニメ調の線画抽出。主線だけ抽出したいとき便利 |
| Content Shuffle | 内容をシャッフルして新しい構図に |
| Instruct Pix2Pix | テキスト指示(プロンプト)で画像を編集 |
ここでは、分かりやすい様にControlNet v1.1を使用してプリプロセッサ(Preprocessor)の各機能を比較していきます。
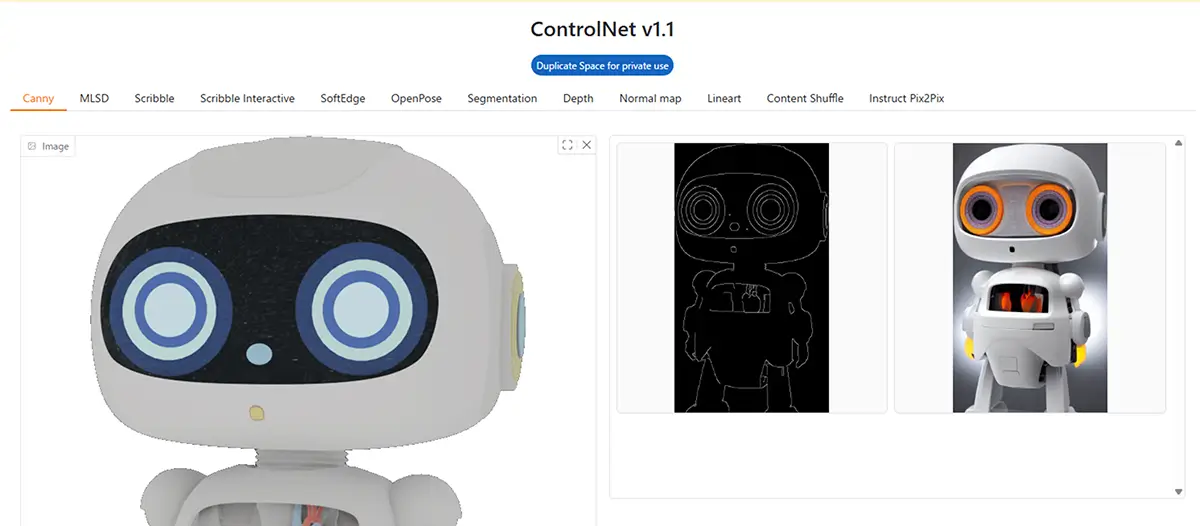
1. Canny
- 特徴: Canny法によるエッジ(輪郭線)抽出
- 用途: 写真や絵の輪郭を抽出して、それを元に絵を描かせたいとき
- 補足: 輪郭を強調した画像が得られる。細部がしっかり表現されやすい。
2. MLSD (Mobile Line Segment Detection)
- 特徴: 建築物や室内など、直線構造に強い輪郭抽出
- 用途: 建物、背景、部屋、都市風景などの線画生成に◎
- 補足: 自動的に水平・垂直の直線を取り出す
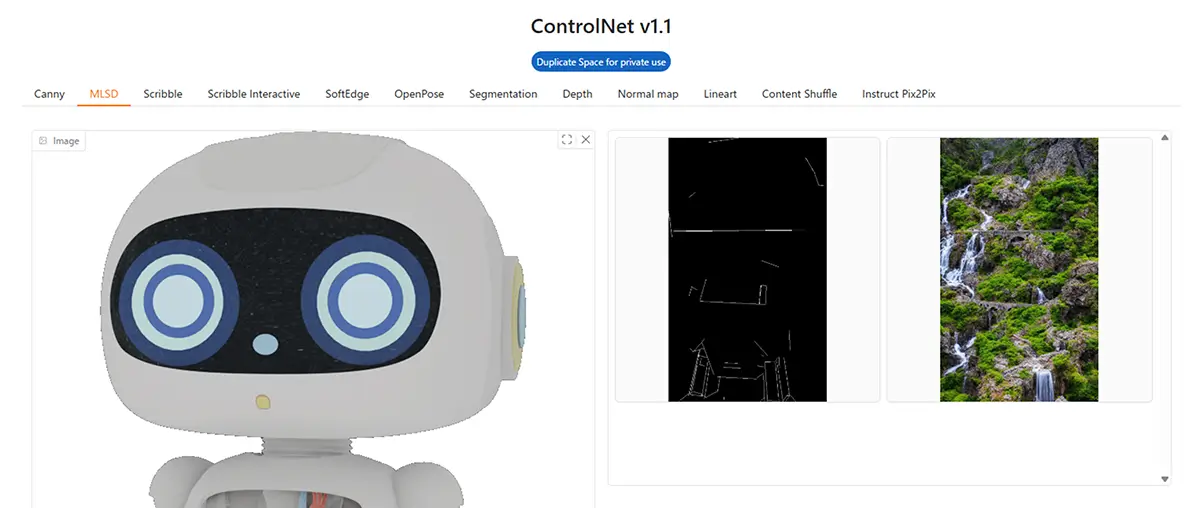
人物、キャラクターでは正常な抽出が行われない。
3. Scribble
- 特徴: 落書きのような画像から生成
- 用途: 簡単な構図・ポーズ・配置を決めて生成したいとき
- 補足: 線の意味(輪郭 or 塗り)は問わず、形だけをベースに生成する
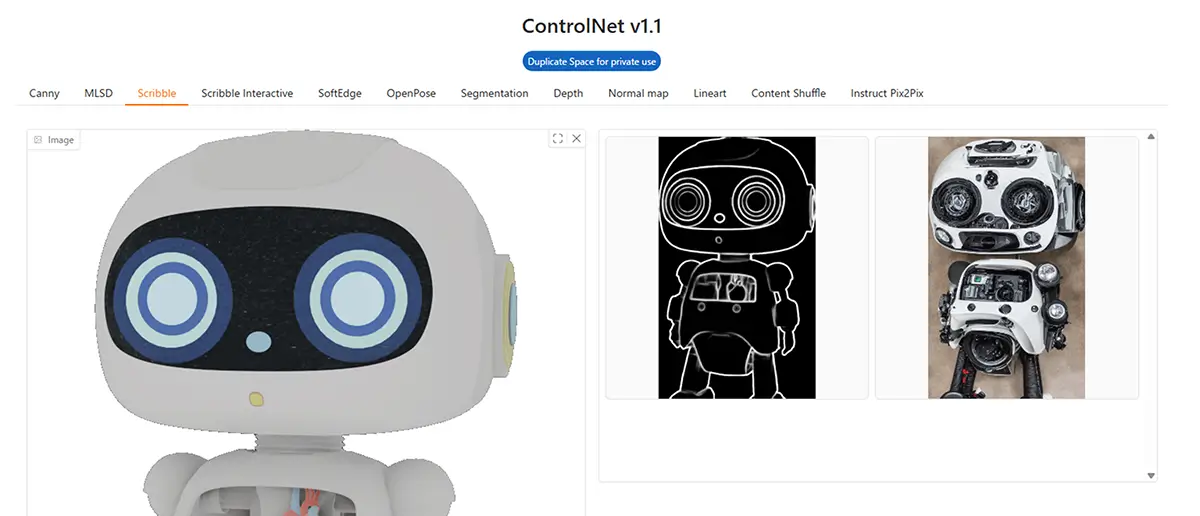
4. Scribble Interactive
- 特徴: 手動でScribble(落書き)を描ける
- 用途: 自分で線を引いてイラストを描かせたいとき
- 補足: マウスやペンで直接描くインターフェース
5. SoftEdge
- 特徴: 輪郭が滑らかで柔らかい、Cannyよりも自然
- 用途: 写真をベースに、線の少ない自然なアウトライン生成
- 補足: 人物写真などに適している
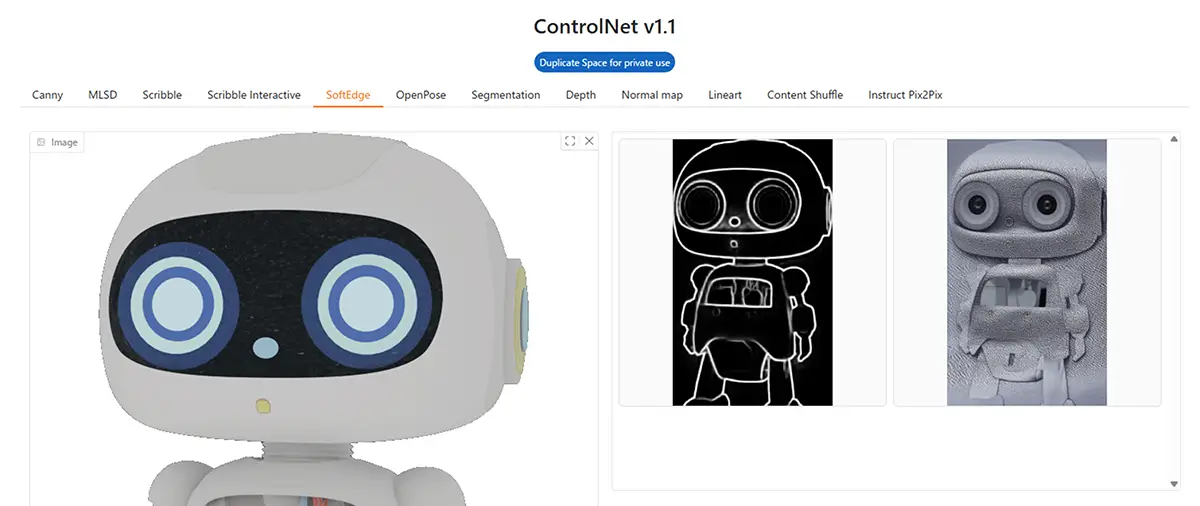
6. OpenPose
- 特徴: 人体のポーズ(骨格)を抽出
- 用途: キャラのポーズだけ再現したいときに◎
- 補足: 背景や顔は無視され、ポーズ情報のみ利用
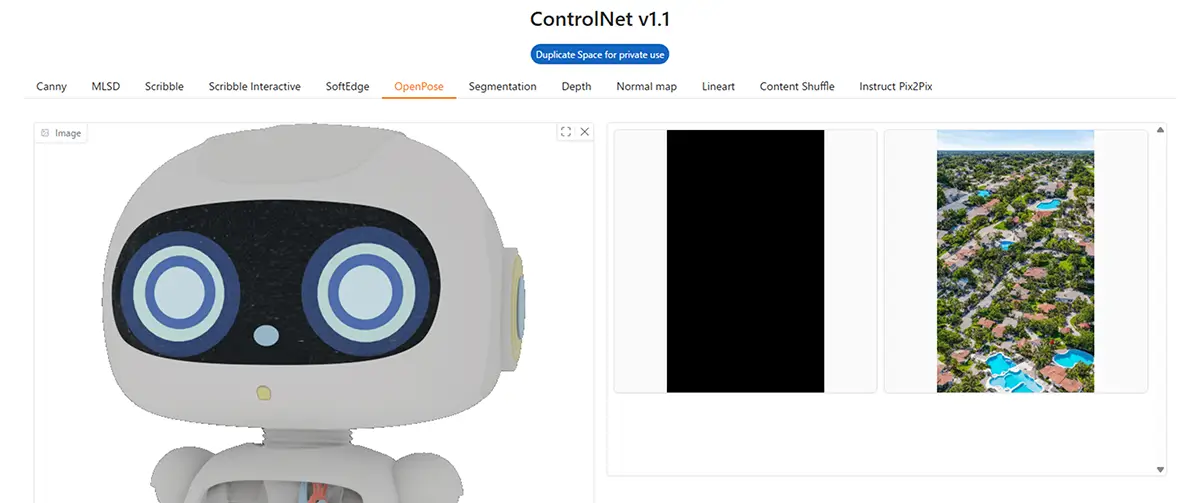
3Dからのロボットの画像では骨格が抽出されなかった。
7. Segmentation
- 特徴: 領域分割(人、空、草、服などを色分け)
- 用途: 色ごとに意味のある領域を持つ画像にしたいとき
- 補足: 色に意味を持たせた構図が作れる
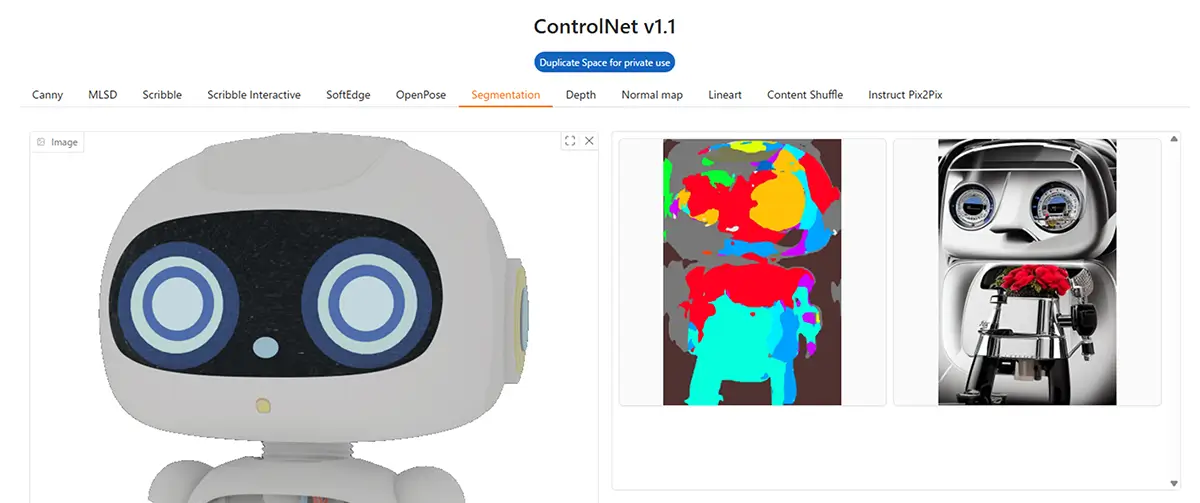
8. Depth
- 特徴: 被写体までの奥行き(深度)情報を抽出
- 用途: 遠近感を保った画像を作りたいとき
- 補足: 立体的な表現や風景に有用
9. Normal Map
- 特徴: 3D的な法線方向(面の向き)を抽出
- 用途: 光の当たり方や凹凸感を保って描き直したいとき
- 補足: SDXLなどの高精細モデルと相性が良い
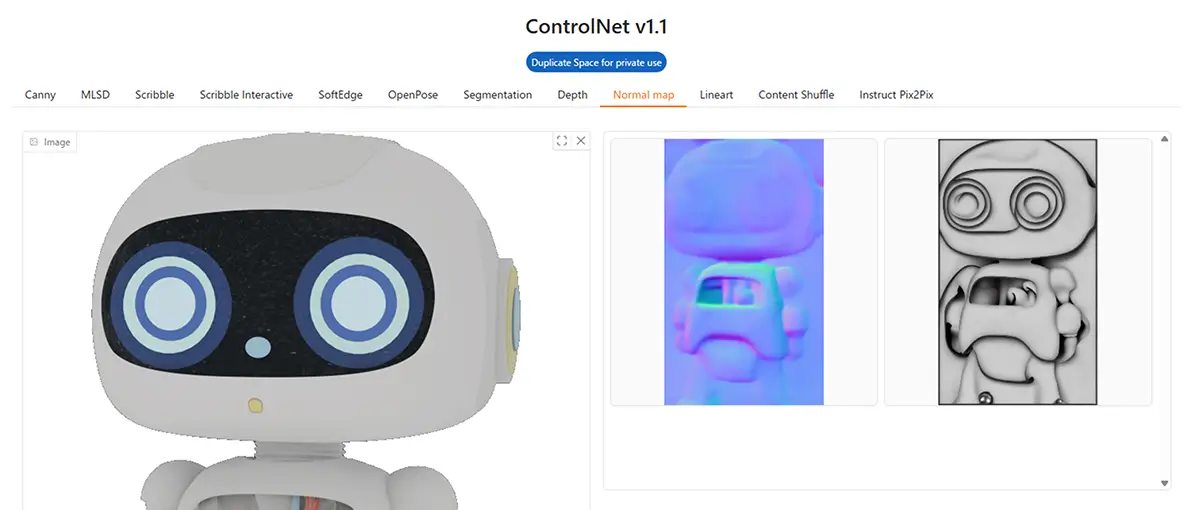
10. Lineart
- 特徴: アニメ線画風に輪郭を抽出(AnimeLineart系)
- 用途: アニメ風のキャラ線画を元に塗り直したいとき
- 補足: 濃淡は無視し、主要な輪郭線を抽出
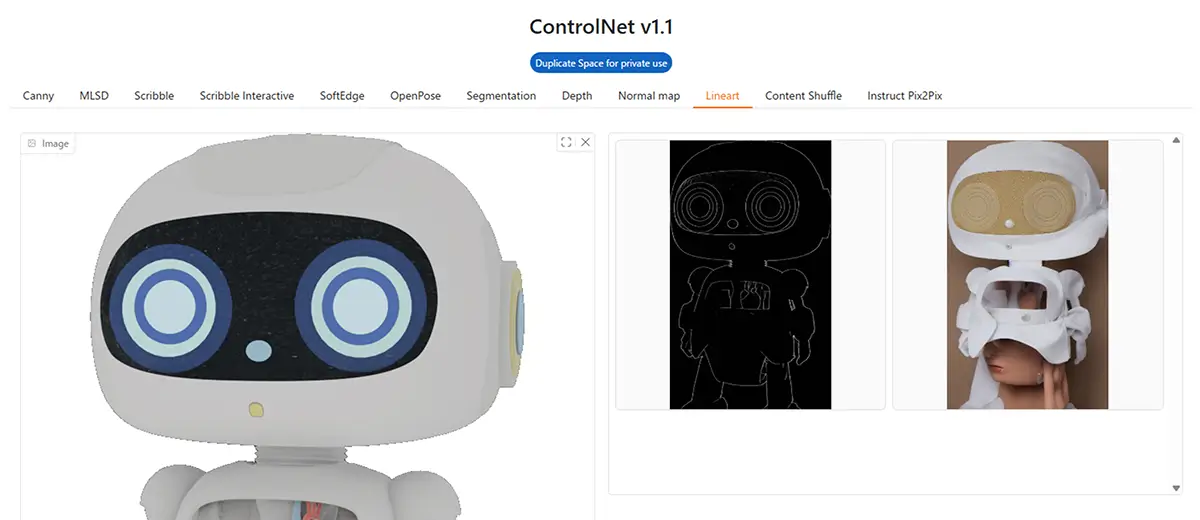
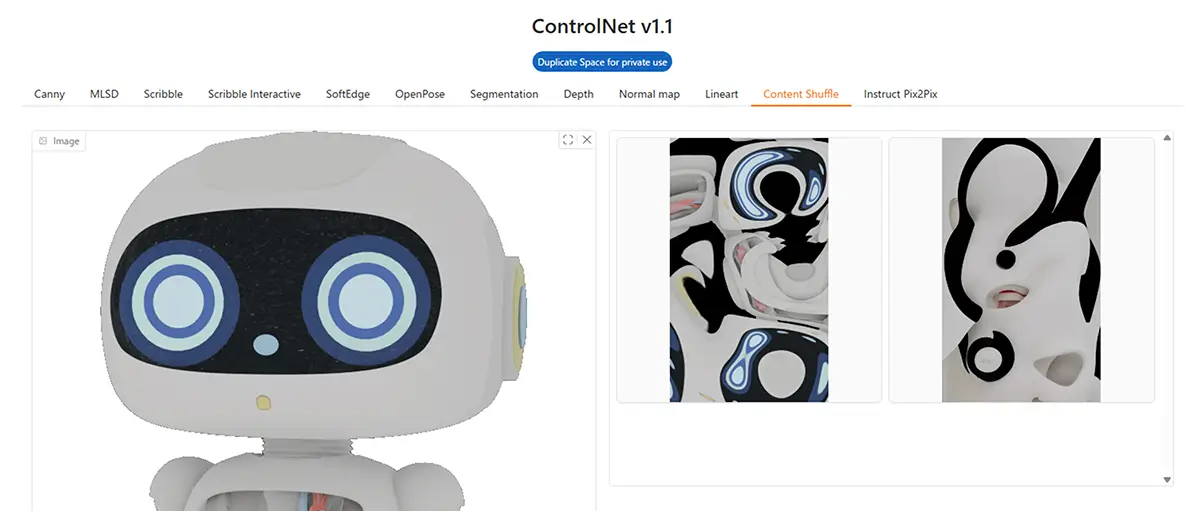
11. Content Shuffle
- 特徴: 色や形の情報をシャッフル(内容の構成だけ残す)
- 用途: 抽象画や構成ベースの画像生成
- 補足: 元の画像を完全に変えたい場合に◎
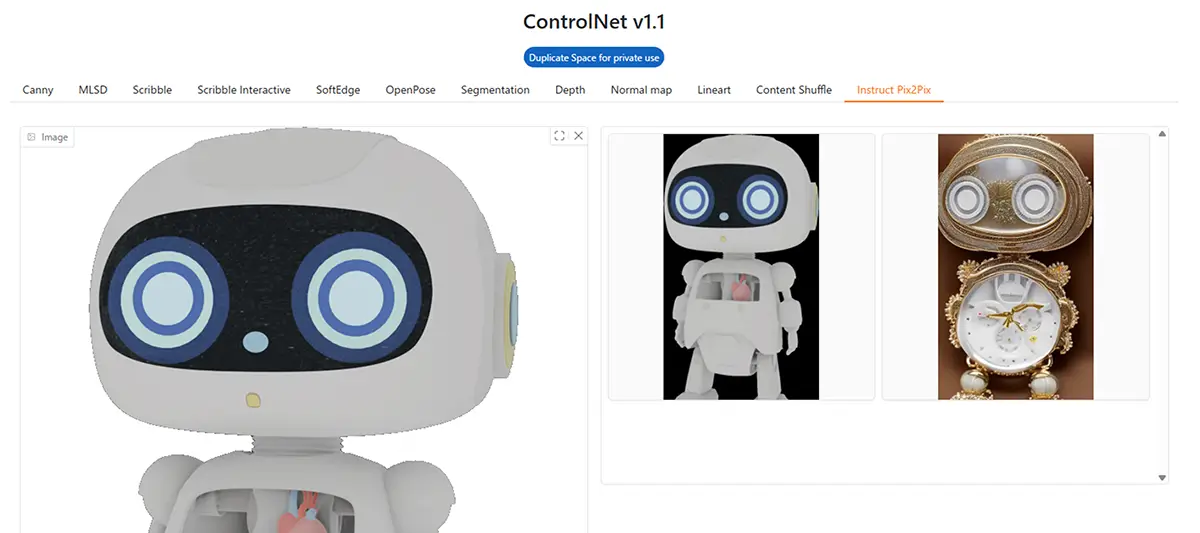
12. Instruct Pix2Pix
- 特徴: テキスト指示(例:「笑顔にして」)に従って画像を編集
- 用途: 修正や変化を加えたいとき
- 補足: Promptの指示が重要。「目を大きく」「髪をピンクに」なども可能
画像のみ、テキスト無しの場合の抽出画像
ControlNet導入方法(ローカル/RunPod共通)
AUTOMATIC1111での使用方法
Automatic1111のダウンロード方法
WebUI(AUTOMATIC1111)の【インストール方法】【拡張機能インストール】【エラー対処法】 WebUI(Webユーザーインターフェース)とは、ブラウザを通じて操作できるユーザーインターフェースのことです。特にStable Diffusionでは、WebUIを使うことで専門的なコ…
STEP
HuggingFaceから必要なモデルをダウンロード
STEP
モデルのダウンロード
ControlNetの公式リポジトリであるHugging Faceから、必要なモデルファイルをダウンロードできます。
公式リポジトリ:
https://huggingface.co/lllyasviel/ControlNet/tree/main/modelsモデルの選択:
主なモデルファイル(例)
control_sd15_canny.pth(Cannyエッジ検出用)control_sd15_hed.pth(HEDエッジ検出用)control_sd15_openpose.pth(OpenPose用)control_v11f1e_sd15_tile.pth(タイル分割用)control_v11p_sd15_depth.pth(深度マップ用)
Automatic1111 では原則「個別DLのみ」です。
ComfyUIは「ComfyUI-Manager」から“まとめて一括DL”でき、モデルの指定のフォルダに配置されます。
STEP
ダウンロードファイルの配置方法
.pthファイルは、以下のディレクトリに配置してくださいます。
例:AUTOMATIC1111
/stable-diffusion-webui\extensions\sd-webui-controlnet\models/配置後、再起動すると、ControlNetノードでこれらのモデルを選択できるようになります。
STEP
Stable Diffusion(チェックポイント)モデルを準備
- HuggingFaceなどから チェックポイント をダウンロード
\stable-diffusion-webui\models\Stable-diffusion\に配置
STEP
Automatic1111を起動
- txt2imgまたはimg2imgタブ内の「ControlNet」セクションを開く
- 使用する画像(例:線画、ポーズ画像)をアップロード
- モデル(例:canny, openpose など)を選択
- 各種オプション(有効化、推論強度など)を設定
- 通常通り画像生成を開始
ComfyUIでの使用方法
あわせて読みたい
ComfyUIとは?使い方・モデル・テンプレート・基本機能を解説【2026年版】 ComfyUI 使い方導入ガイド|モデル・テンプレート ComfyUIは、画像・動画・3D生成をノードベースのワークフロー形式で操作できる生成AIツールです。「モデルは何を使え…
STEP
ComfyManager を使って必要なモデルをダウンロード
ComfyUI を起動
- Manager タブ を開く
- 「Install Models」 → ControlNet で選択
- SDXL/SD1.5用の必要な ControlNet モデルをチェック
- 「Install」ボタンでまとめてダウンロード
- 自動で
ComfyUI/models/controlnet/に配置される
STEP
Stable Diffusion(チェックポイント)モデルを準備
- ComfyManager やHuggingFaceなどから チェックポイント をダウンロード
ComfyUI/models/checkpoints/に配置
STEP
プリプロセッサ(前処理)画像の準備
- 元画像やマスク画像を用意
- ノード内でプリプロセッサを選択
- 例:Canny / Depth / Lineart / Lineart_Anime / OpenPose など
STEP
ComfyUI ノードで ControlNet を設定
- ControlNet ノード をワークスペースに追加
- プリプロセッサ出力を ControlNet ノードに接続
- 使用する ControlNetモデルを選択(例:control_lineart-fp16)
- Weight(制御の強さ)を設定
- 0.5〜0.8が一般的(低めだと緩く、高めだと忠実に)
STEP
SD チェックポイントに接続して生成
- Stable Diffusion ノードにチェックポイントを設定
- ControlNet ノードの出力を SD ノードに接続
- 必要なら LoRA / VAE なども追加
- 生成ボタンで実行
InvokeAIで使う方法
本格的に線画から忠実な変換を行いたい場合は、Automatic1111やComfyUIの利用がおすすめですが、
プロンプト制御+ControlNet+SDXLの安定動作を求めるなら、InvokeAIを使用する方法もあります。
ただし、反映の精度や自由度は控えめで、用途としては「ざっくりした雰囲気付け」や「簡易的な補助」に向いています。
- SDXL & ControlNet両方対応
- 高速・軽量でGUIも使いやすい
注意点
- ControlNet 対応バージョンは 3.x以降の最新版が必要です(古い InvokeAI では非対応)。
- デフォルトで Diffusers ベースではないため、Diffusers ベースの Hugging Face モデル(例:
lllyasviel/control_v11p_sd15s2_lineart_anime)を使用するには、モデル変換が必要です。 - WebUI の柔軟性は A1111 ほどではないため、細かいマスクや複数 ControlNet の組み合わせは限定的です。
「InvokeAIを普段使っている」方であれば試してみる価値はあります。
あわせて読みたい
【InvokeAIの使い方】最新版InvokeAI|Stable Diffusion 使い方完全ガイド・2026年版 InvokeAI の特徴 「InvokeAI(インヴォーク・エーアイ)」は、Stable Diffusionをベースとした画像生成ツールの一つで、特に以下のような特徴。があります。 項目内容 …
ControlNetの基礎ポイント
1. 入力画像とプリプロセッサ
- ControlNetは「入力画像」を読み込ませ、それを「プリプロセッサ(Preprocessor)」で変換して特徴を抽出します。
- 例:Canny(輪郭抽出)、OpenPose(人体の骨格検出)、Depth(奥行き情報)、MLSD(直線抽出)など
- 大事なのは「入力画像」と「プリプロセッサの選択」が一致しているかです。
- 例えば人物のポーズを真似させたい → OpenPose
- 下絵や線画を元に塗らせたい → Canny / Scribble
2. Control Weight(制御の強さ)
- デフォルトは 1.0
- 高すぎると「ガチガチに縛られて自然さが消える」
- 低すぎると「ほとんど無視される」
- 目安:
- 0.5〜0.7 → 自然さを残しつつ制御
- 1.0以上 → 強制的にトレース
3. Starting / Ending Control Step
- 制御を「生成プロセスのどの段階まで効かせるか」設定するもの。
- Start: 0 〜 End: 1.0 → 全ステップに適用(最も強く効く)
- Start: 0.0 / End: 0.5 → 前半だけ効かせ、後半は自由に生成させる
- 「前半は構図固定、後半は仕上げ自由」にしたい時に便利です。
4. Guess Mode
- プロンプトが弱い時に「ControlNetの情報をかなり優先して生成する」モード。
- 輪郭やポーズをほぼ忠実に再現させたい時に有効。
- ただし、他の制御(スタイルや細かい描写)が入りにくくなる。
5. 解像度との相性
- ControlNetは入力画像の情報をマップ化して制御するため、生成解像度が極端に違うと効きづらいです。
- 例:入力画像512×512 → 出力も512×512や768×768だと効きやすい
- 入力と出力が大きく異なる → 崩れる
ControlNetのスロット数(本数)を増やす方法
「ControlNet拡張の設定変更」(Settings)
※AUTOMATIC1111やWebUI Forgeの場合はやり方が少し違いますが、基本は同じです。
1. Settingsで増やす
- Stable Diffusion WebUIの
Settingsタブを開く - 左側メニューで
ControlNetを選択 Multi-ControlNet: Max models amountという項目を探す- デフォルトは
3になっているので、4や5に変更 - ページ下の
Apply settingsを押す - WebUIを再起動
これでControlNetタブにスロットが増えます。
注意
本数を増やすとVRAM使用量が直線的に増えます。
VRAM不足だと生成途中でCUDA Out of Memoryエラーになります。
顔と髪を保ちながらアングルを変える方法
① FaceID / IP-Adapter を使う
- IP-Adapter (FaceID版) は入力画像の「顔の特徴」を抽出して保持しつつ、ポーズやアングルを自由に変えられる拡張です。
- Automatic1111 Forge や ComfyUI で使えます。
- 使い方:
- 顔画像をIP-Adapterに入力
- Promptに「desired pose / angle」を書く
- 必要に応じて ControlNet(OpenPose など)で体のアングルを制御
顔はIP-Adapterで固定、アングルはControlNetで制御、という分業がベスト。
② ControlNet (OpenPose) + 顔の補強
- OpenPoseで「体の角度」を制御
- 顔や髪は LoRA / Textual Inversion でキャラの特徴を学習しておく
- そうすると「顔と髪型はLoRAで維持、ポーズはOpenPoseで制御」できる
③ After Detail Fix(生成後に顔を修正)
- 生成するとアングル変更で顔が崩れることが多い
- その場合は 「Face Restore」(GFPGAN, CodeFormer, ADetailer) を使って顔を後処理で直す
- 特に横顔や斜め角度で効果大
ControlNetのLoRAとの併用
- A1111は LoRA・ControlNetを同時に使えます。
- 例えば「構図はポーズ画像から取り、画風はLoRAで指定」などが可能です。
| 目的 | 使用機能 | 設定例 |
|---|---|---|
| アニメ調にしたい | LoRA | <lora:anime_style:0.8> |
| ポーズを再現したい | ControlNet | OpenPose + 画像アップロード |
| 線画を着色したい | ControlNet | Canny + 線画画像をアップロード |
| 両方使いたい | LoRA+ControlNet | LoRA指定+ControlNetに画像&モデル指定 |
※LoRAとControlNetは「モデル拡張」であり、複数のUIで使える共通技術です。導入しやすさ・操作感はUIにより異なるため、自分のスタイルに合ったUIを選ぶのがコツです。
実際の使い方例
- 線画や、AIなどで抽出したモノトーン線画を用意
- ControlNetで「lineart」や「scribble」モデルを選択
- プリプロセッサを「none(なし)」に設定(すでに線画なので)
- 生成したいイメージをプロンプトに入力
- 線画をガイドとして、AIがそれに沿った画像を生成
モノトーン線画の活用法・二次利用法・変換テクニック
ControlNetで「背景が黒、線が白」のモノトーン線画(たとえばlineart, lineart_anime, scribbleなどのプリプロセッサから出力される画像)は、さまざまな方法で画像生成に活用できます。
基本活用:線画画像を使った画像生成
モノトーン線画をControlNetの入力としてそのまま使用し、元のポーズや構図を保ちつつ、絵柄や色、背景などを自由に変えて生成できます。
- 使用モデル例:
control_sd15_lineart,control_sd15_scribble - 応用例:
- キャラのデザインだけ変えたいとき
- 背景だけ変えたいとき
- アニメ風→リアル風への変換 など
ControlNetへの入力画像の読み込み方法(Stable Diffusion WebUIの場合)
STEP
ControlNetを有効にする
WebUIを開いて、プロンプト入力画面の下部にある「ControlNet」セクションを展開します。
STEP
線画画像を読み込ませる
- 「Enable」 にチェックを入れる
- 「画像入力欄(Drag and DropまたはSelect Image)」 に、白線+黒背景の線画画像をドラッグ&ドロップ、または選択で読み込ませる
STEP
適切なプリプロセッサとモデルを選択
線画画像を使う場合、以下のように設定することが多いです
| 項目 | 推奨設定 |
|---|---|
| Preprocessor(プリプロセッサ) | none(線画がすでに出来ているため) |
| Model(モデル) | control_sd15_lineart など(線画専用) |
※プリプロセッサを「none」にすることで、画像そのものを使って直接制御できます(すでに白黒で整っているなら、前処理不要)。
STEP
生成プロンプトと画像サイズを設定
- 通常通りプロンプト(テキスト)を入力
- 出力サイズや他のパラメータも設定
- 必要なら「Control Weight」(画像の反映度)を調整
STEP
画像を生成
「Generate」ボタンを押して生成開始。
二次生成に活かすテクニック
線画をInvert(反転)して利用
元の線画が「白線×黒背景」の場合、多くのモデルが期待するのは「黒線×白背景」なので、画像反転(色の反転)を行ってからControlNetに入力すると、精度が向上する場合があります。
- 使用ツール:Photoshop、GIMP、オンラインエディタ、またはControlNetの「invert」オプション
Photoshopで反転する方法に関しては、こちらの記事で解説しています。
あわせて読みたい
Photoshopで線画を加工する【小技5選】 AI補正・拡張ツールにも使える実践テクニック AI画像生成や3Dテクスチャ制作では、「線画をどう加工するか」が出力品質を大きく左右します。 この記事では、Photoshopで…
拡張活用(画像処理+ControlNet)
他のControlNetと組み合わせて使う
lineart+depth→ 線画と立体感の両方を指定lineart+pose→ 線画のキャラにポーズ制御を加える
ControlNetは最大3つまで同時に使えるので、複数の視点から画像をコントロールできます。
ControlNetで同じ画像が出てくる場合の対処法
考えられる原因
- Seedが固定されている: 同じSeed値だと同じ画像が生成されます
- ControlNetの影響が強すぎる: コントロール強度が高いと、入力画像に引っ張られすぎて変化が出にくい
- プロンプトの影響が弱い: CFG ScaleやDenoising Strengthの設定によっては、プロンプト変更の効果が出にくい
- キャッシュの問題: まれにソフトウェア側で前の結果がキャッシュされることも
対処法
- Seedを「-1」(ランダム)に設定
- ControlNetの強度を下げる(0.7→0.5など)
- CFG Scaleを調整(7→10など)
- Denoising Strengthを上げる(ControlNet使用時)