【InvokeAIの使い方】最新版InvokeAI|Stable Diffusion 使い方完全ガイド・2026年版


目次
InvokeAI の特徴
「InvokeAI(インヴォーク・エーアイ)」は、Stable Diffusionをベースとした画像生成ツールの一つで、特に以下のような特徴。があります。
| 項目 | 内容 |
|---|---|
| モデル | Stable Diffusion 1.5 / 2.1 / SDXL 1.0 に加え Flux と SD 3.5 なども使用可能になった |
| UI | WebベースのUIとコマンドラインUIの両方に対応(いわゆるスクリプト型UIも併設) |
| 特徴 | 安定志向、高機能、業務用途にも向く設計 |
| 拡張性 | ControlNet, LoRA, T2I-Adapter などの機能も対応(バージョンによる) |
| カスタマイズ性 | Pythonスクリプトや設定ファイルによる細かい制御が可能 |
| バッチ処理 | 複数プロンプトや構成での自動生成が得意(スクリプト実行型) |
| ローカル実行 | 画像生成・保存などすべてローカルで完結。商用にも使いやすい |
| 対象ユーザー | 中〜上級者、もしくは「スクリプト制御が好きな方」 |
【1】ControlNetやInpaintingといった高度な生成制御機能が使える
→ 単なる画像生成だけでなく、「構図の保持・ポーズ指定・画像の一部修正」など、商用クオリティが求められる制作にも使える。
- ControlNet:ポーズや輪郭などを活かした生成が可能 → キャラの一貫性や構図指示が必要な案件で便利
- Inpainting:画像の一部を修正(背景差し替え・表情変更など)→ 修正対応の多い商業案件向き
拡張機能完全ガイド
Stable Diffusion拡張機能まとめ【2026年最新版】拡張性ランキングとツール比較 拡張性ランク(2026最新版) Stable Diffusionの拡張機能は、現在では単なる「プラグイン追加」ではなく、生成AIワークフロー全体を設計するための構造要素へと進化して…
【2】スクリプトやバッチ処理によって一括生成・自動化がしやすい
→ 例えば「10個の構図 × 5つのキャラ × 色違い」など、パターン展開をしたい場合に非常に便利です。
- プロンプトや構成をスクリプトで定義 → 大量の画像を一括生成可能
- 自動保存や命名ルールも設定可能
- 定型業務(例:LINEスタンプ、広告バナー、商品画像)などに向いている
【3】安定性と再現性が高い → 商用利用に安心
- InvokeAIはUIや仕様が比較的落ち着いており、「バージョン依存の不具合が少ない」点が好評です。
- ローカル完結であり、生成内容も自分で完全管理できるため、商用利用時のリスク管理(個人情報・著作権など)もしやすい。
UIのスタイル
- Web UI(InvokeAI Web)
→ AUTOMATIC1111のような直感的GUIに近いけれど、よりシンプルで安定重視。 - コマンドライン&ノードスクリプト型 UI(InvokeAI CLI)
→invoke.pyにプロンプトや設定を記述して一括実行できる、スクリプト感のある操作性。
他ツールとの違い
| ツール名 | 操作性 | 安定性 | 機能性 | 拡張性 | 備考 |
|---|---|---|---|---|---|
| AUTOMATIC1111 | ★★★★★ | ★★★☆☆ | ★★★★★ | ★★★★☆ | 拡張機能豊富、開発スピード速い |
| ComfyUI | ★★★☆☆ | ★★★★☆ | ★★★★★ | ★★★★★ | ノード型で柔軟、慣れが必要 |
| InvokeAI | ★★★★☆ | ★★★★★ | ★★★★☆ | ★★★★☆ | 安定志向、業務利用に向く |
一方で、より直感的な操作や多機能な拡張性を求めるユーザーは、ComfyUIも検討する価値があります。
対応しているモデル
InvokeAI 対応モデル一覧(2025年版)
| モデル名 | 対応状況 | 特徴・用途 | 備考 |
|---|---|---|---|
| Stable Diffusion 1.5 | 公式対応 | 最も広く使われているSDクラシックモデル。LoRA・ControlNetなど拡張互換性が高い。 | .ckpt / .safetensors 形式可。軽量で動作安定。 |
| Stable Diffusion 2.1 / 2.0 | 公式対応 | 解像度向上モデル。1.5とアーキテクチャがやや異なる。 | 一部LoRA互換性なし。 |
| Stable Diffusion XL (SDXL 1.0 / 1.5) | 公式対応 | 高解像度・高品質モデル。InvokeAI推奨の標準。 | .safetensors 推奨。512〜1024px対応。 |
| Stable Diffusion 3 / 3.5 | 対応(実験的) | 最新のSDシリーズ。文章理解力・構図安定性が向上。 | HuggingFace版 diffusers 形式対応。モデル認識が必要。 |
| FLUX.1 / FLUX.1 Schnell / FLUX.1 Dev | 対応(実験的) | SD3世代の新アーキテクチャ。精密な構図制御と自然光表現に強い。 | Invoke専用Fluxノードあり。T5テキストエンコーダー利用。 |
| Bria 2.3 | 対応 | 実写・広告用に最適化された商用モデル。 | 高精細リアル人物生成に特化。 |
| Imagen 3 / 4 | 対応(制限付き) | Google系モデル。Invokeで一部ロード可能。 | 非公式対応。変換済モデルが必要。 |
| Stable Cascade | 準対応 | 省VRAM構造のCascadeアーキテクチャモデル。 | 一部ユーザー導入成功報告あり。 |
| LDM Text-to-Image (汎用) | 対応 | Diffusers互換のLDM形式モデル全般。 | Invokeのモデルマネージャー経由で追加可能。 |
| LoRA / Textual Inversion | 完全対応 | 任意モデルに微調整追加。 | .safetensors 形式LoRA対応済み。 |
| ControlNet | 対応 | 画像構図制御に使用。 | OpenPose・Canny・Depthなど利用可。 |
注意事項・現時点での留意点
- 公式リストには “Currently supported base model types are …” として SD3.5 や FLUX.1 が明記されていますが、実際に導入・運用する際にはモデルの互換性・フォーマット・トークナイザー/テキストエンコーダーの整合性などを確認する必要があります。 GitHub+1
- 例えば GitHub Issue では「SD3.5 と Flux T5 モデルを組み合わせたときにエラーになる/互換性が完全ではない」という報告があります。 GitHub
- FLUX モデル(特に “Flux” と記されるモデル)は、一般的な Stable Diffusion フレームワークとは少し構造が異なるため、Invoke 内の“Flux用ノード”や“専用処理”があるという記述もあります。 Facebook
InvokeAI 導入ガイド
まずは以下の表で、必要要件を確認して下さい。要件に満たない場合は、Google Colabや、RunPodなどのクラウド環境がおすすめです。
ハードウェア要件(最低~推奨)
| 項目 | 最低要件(SD1.5前提) | 推奨要件(SDXL使用含む) |
|---|---|---|
| GPU | CPUでも使える(との記載あり) | NVIDIA製(VRAM 6GB以上) サクサク動かしたい場合はRTX2060VRAM12GB以上 |
| CPU | Intel / AMD(4コア以上) | 高速化のために6コア以上推奨 |
| メモリ(RAM) | 8GB以上 | 16GB以上 |
| ストレージ | 10GB以上の空き容量(モデル含む) | 50GB以上推奨(複数モデル対応) |
| OS | Windows / macOS / Linux | Linuxは安定性高め |
※NVIDIA製GPUを使用する場合は、必ず最新のGeForceドライバ(またはStudioドライバ)をインストールしておきましょう。
InvokeAIでは、GPUドライバとPyTorch・CUDAの整合性が必要で、古いドライバでは正しく動作しないことがあります。
画像生成に最適なGPU
【2026年】AI画像生成GPU おすすめ比較|RTX4060〜5090・5060Ti【Stable Diffusion・ComfyUI・LoRA対応】 画像・動画生成AIを使いたい!GPUは何を選べばいい? Stable DiffusionやComfyUIで画像生成に挑戦したい――そう思ったとき、最初に立ちはだかる壁が「GPU選び」ではない…
PunpodならInvokeAIも数クリックでお試しできる
【Runpodの料金と使い方と注意点】ComfyUI・Stable Diffusion・LoRA学習|2026年最新版【②実践編】 Runpodの料金と画像生成や動画生成、LoRA学習をする方法(2026年6月時点) 最近の生成AIは、VRAMやGPU性能を大きく要求するため、ローカル環境だけでは限界を感じやすく…
クラウドGPU選び
【2026年版】クラウドGPU比較|Runpod・Colab・Paperspace・Lambda Labsの特徴と選び方 クラウドGPUのニーズと記事の目的 近年、AI生成や3Dモデル作成、機械学習の学習用途などで、高性能GPUの需要が急速に高まっています。個人のPCでは対応が難しい処理も、…
推奨環境例(快適に使える構成)
| パーツ | 推奨例 |
|---|---|
| RAM | 16GB以上 |
| ストレージ | SSD(NVMe推奨) |
| OS | Windows 10/11、Ubuntu 22.04 など |
InvokeAIにおすすめのGPU(用途別・VRAM別)
画像生成AIにおすすめのGPU一覧(2025年版)
| GPU名 | VRAM容量 | 特徴・用途 | おすすめ度 | 価格目安(2025年10月時点) |
|---|---|---|---|---|
| RTX 4090 | 24GB | 最高性能。SDXL・SD3.5・FLUXでも快適。LoRA学習・動画生成にも余裕。 | ★★★★★ | 約35〜 |
| RTX 4080 SUPER/5070Ti/5080 | 16GB | 高速かつ省電力。プロ向け・長期使用にも最適。 | ★★★★☆ | 約25〜 |
| RTX 4070 Ti / Ti SUPER | 12〜16GB | ミドルハイクラス。InvokeAI・SDXL用途なら十分。 | ★★★★☆ | 約18〜 |
| RTX 4070 | 12GB | コスパ良好。個人制作者・ブロガーにもおすすめ。 | ★★★★☆ | 約12〜 |
| RTX 4060 Ti (16GB版) | 16GB | 価格を抑えつつもVRAM容量を確保できる軽作業向け。 | ★★★☆☆ | 約9〜 |
| RTX 3060 (12GB版) | 12GB | 旧世代ながらコスパ◎。SD1.5やLoRA学習には十分。 | ★★★☆☆ | 約5〜 |
GPUスペック比較
【2026年】AI画像生成GPU おすすめ比較|RTX4060〜5090・5060Ti【Stable Diffusion・ComfyUI・LoRA対応】 画像・動画生成AIを使いたい!GPUは何を選べばいい? Stable DiffusionやComfyUIで画像生成に挑戦したい――そう思ったとき、最初に立ちはだかる壁が「GPU選び」ではない…
あわせて読みたい
【ノートPCでStableDiffusion】VRAM不足を解決する方法|クラウドGPU活用術 生成向けPCはもういらない?クラウド化が進むんでいる ノートPCでAI画像生成(Stable Diffusion など)を動かしたいけど、VRAM不足で諦めていませんか?実は、クラウドG…
InvokeAI のインストール手順(Windows/macOS/Linux 共通ベース)
STEP
Python環境の準備
Windows / Linux / Mac 共通
STEP
Python 3.10 をインストール
「Add Python to PATH」に✅を入れてインストールしてください。
Python 3.10 のインストール方法はこちらの記事をご覧ください
Python 3.10.6 の”インストール手順”と”トラブル時の対処法” AI 系ツールとPython 3.10.6 AUTOMATIC1111 のような AI 系ツールは、Pythonのバージョン依存が強いため、Python 3.11 や 3.12 では、エラー・動作不良・xformers非対応…
安定版 v3.0 以降対応(SDXLもサポート)
Python 仮想環境を利用してインストールします。
STEP
仮想環境の作成(例: venv)
Python 3.10のインストールがされている環境で、ターミナルで以下のコマンドを実行します。
※ Windows のターミナルの起動方法…
Windows Terminal起動方法
- スタートメニューで、左クリック➡
ターミナルもしくは、「Windows Terminal」と検索して起動
※ デフォルトでは PowerShell または WindowsPowerShell)が開きます
画像生成用途の場合は、コマンドプロンプト(CMD)と相性が良いです。
pip install や conda などのモダン開発向けコマンドは、PowerShellと相性が良いです。
(※コマンドプロンプト(cmd)をWindows Terminal から開く為の設定方法はこちらの記事をご覧ください。)
Windows Terminalは、タブを切り替えて複数のシェルを使う事が出来ます
- 上部の
+ボタンから新しいタブを開けます
※Microsoft 公式も「Windows Terminal」を推奨
※ Mac のターミナルの起動方法…
ターミナル起動方法
- **「Command ⌘ + Space」を押して、「Spotlight検索」**を開く
- 検索バーに「ターミナル」と入力してEnter
または、以下の手順でも開けます:
アプリケーション → ユーティリティ → ターミナル
※ Linux のターミナルの起動方法…
Linuxターミナル起動方法
- 1,:
Ctrl + Alt + Tを同時に押す(多くのLinuxディストリビューションで共通) - 2,:アプリケーション一覧から「ターミナル」または「Terminal」で検索して開く
Ubuntu、Fedora、Debianなど、ほとんどのLinux環境に標準で搭載されています。
※ PowerShell の起動方法…(Windows)
PowerShell(パワーシェル)**は、Windowsに標準搭載されている、より高度な操作ができるコマンドラインツールです。見た目はコマンドプロンプトと似ていますが、より多機能で、プログラミング的な処理も得意です。
PowerShell起動方法
1,スタートメニューで「PowerShell」と検索してクリック
※ コマンドプロンプト(cmd)の起動方法…(Windows)
Windowsキー + Rを押す
「cmd」と入力してEnterを押す
または、スタートメニューで「コマンドプロンプト」と検索してもOK!
コマンドプロンプト(cmd)は、Windowsのターミナルからも開く事が出来ます
(※コマンドプロンプト(cmd)をWindows Terminal から開く為の設定方法はこちらの記事をご覧ください。)
python -m venv invokeai-envこれで、仮想環境が作成されます。
STEP
仮想環境を有効化(以下のコマンドを実行して仮想環境を有効化)
- Windows
invokeai-env\Scripts\activate- Mac/Linux
source invokeai-env/bin/activateSTEP
InvokeAI のインストール
※インストール方法は二通りあります。pip install … 開発者的な使い方(スクリプト・API連携・自作ツールへの組み込み)をしたい場合は、手動構築する方が向いています。
一方で、invokeai-installer… まずは使ってみたい・動かしたい人には こちらが圧倒的にラクです。
※pip installでのインストールの場合は、CUDA Toolkit(例:11.8)とPyTorch(CUDA対応)が必要です
CUDA Toolkitは、NVIDIAのGPUを使ってPyTorch(=画像生成)を高速化するために必要ですが、
CPUで使用される方や、クラウド利用時は CUDA 不要です。
InvokeAIは内部でPyTorchを使っており、そのPyTorchがGPUを使うためにCUDAが必要になります。
| インストール方法 | CUDA Toolkitの扱い |
|---|---|
invokeai-installer を使う場合 | 自動で最適なPyTorch+CUDA組み合わせを導入(別途CUDA ToolkitをインストールしなくてOK) |
pip install invokeai などで手動導入 | 自分でCUDA Toolkit(例:11.8)とPyTorch(CUDA対応)を入れる必要あり |
推奨バージョン(2025年時点)
| ソフト | 推奨バージョン |
|---|---|
| CUDA Toolkit | 11.8 |
| PyTorch | 2.1.0 以降(CUDA 11.8 対応版) |
注意:CUDA ToolkitとPyTorchのバージョンは一致していないと動作しないことがあります。
CUDA Toolkitが必要な人・不要な人
| 状況 | 必要性 |
|---|---|
| GPUなし(CPUのみで使う) | 不要(遅くなるが動く) |
| Google Colab、RunPodなどのクラウドで使う | 不要(サーバ側に入っている) |
| 自分のPCでGPUを使いたい | 必要(PyTorchが自動で使う) |
自分の環境にCUDAが入っているか確認する方法(Windows)
- コマンドプロンプトで以下を入力
nvcc --version- 出力されるバージョンで確認(例:
release 11.8)
または以下のフォルダで確認
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA- InvokeAIをGPUで使いたい場合は、CUDA Toolkitは必要です。
- 但し、 installer版を使えば自動でPyTorch+CUDA環境が整います。
- 手動で入れる場合は PyTorchとCUDAの対応バージョンに注意しましょう
直接 pip install で入れる場合
pip install --upgrade pip
pip install invokeaiinvokeai を pip で直接インストールする方法です。
これは Python パッケージとして InvokeAI を導入するだけで、モデルの準備や設定は自力で行う必要があります。
もしくは、
公式推奨の インストーラーinvokeai-installerを使う場合(最も安定)
pip install invokeai-installer
invokeai-configureinvokeai-installer は InvokeAI の導入を自動化してくれるツールです。
インストーラーを実行すると、以下が対話形式で設定されます
- モデル(SD1.5 / SDXL など)の自動ダウンロード
- Web UI / CLI の選択
- フォルダ構成の設定(例:models、outputs)
STEP
InvokeAI の起動
CLI(コマンドラインインターフェース)モードで起動する方法
invokeaiInvokeAI を Web モードで起動するように設定(invokeai.yaml の設定で Web モードが有効)されている場合は、invokeai だけでも http://localhost:9090 が立ち上がります。(通常は http://localhost:9090)
環境構築時に「Web モードをデフォルトにするか?」という質問に「Yes」と答えた場合に限ります。
明示的に Web UI モードで起動する方法
invokeai --webこのように --web オプションを付けて実行するのが確実です。
すると、必ずブラウザUIが開きます(http://localhost:9090)。
基本的な使い方
SDXL・LoRA・ControlNet などの導入
SDXL対応のためにはモデルの自動取得を選んでおく
SDXLをInvokeAIで使うための設定手順(v3.0以降)
InvokeAI v3.0 以降は SDXLに公式対応しており、比較的簡単に使えますが、以下のポイントを押さえておくと安心です。
1. モデルのダウンロード方法(公式推奨)
InvokeAIでは、セットアップ時に次のような画面が出ます
Which model(s) would you like to download?
1. SD 1.5
2. SDXL Base
3. SDXL Refiner2を選べば SDXL Base モデル(主に画像生成用)3を選べば SDXL Refiner モデル(仕上げ用) が自動でダウンロードされます。
または、後から以下コマンドで追加も可能
invokeai-model-install --model sd_xl_base_1.0
invokeai-model-install --model sd_xl_refiner_1.02. モデルの手動配置(※自分で持っている場合)
sd_xl_base_1.0.safetensorssd_xl_refiner_1.0.safetensors
これらのモデルファイルを以下のように配置
InvokeAI/
├── models/
│ └── stable-diffusion/
│ ├── sd_xl_base_1.0.safetensors
│ └── sd_xl_refiner_1.0.safetensors3. モデル設定ファイル(YAML)が必要!
InvokeAIは .yaml 設定ファイルがモデルごとに必要です。
自動取得の場合は勝手に作られますが、手動の場合は以下のように記述。
例:sd_xl_base_1.0.yaml
name: sd_xl_base_1.0
path: sd_xl_base_1.0.safetensors
model_format: safetensors
variant: fp16
description: Stable Diffusion XL Base
width: 1024
height: 1024→ この .yaml を同じフォルダに置けば認識されます。
4. SDXLの「2段階構成」に注意
SDXLは以下の流れで生成されます
- Baseモデルで粗い画像を生成(1024×1024)
- 必要に応じて Refiner で細部をブラッシュアップ
InvokeAIでは、**Refinerの自動適用タイミング(20~30ステップ目など)**を指定できます。
5. Web UIでの設定(起動後)
- モデル選択で「sd_xl_base_1.0」を選ぶ
- 下部オプションで「Refiner を使う(Use SDXL Refiner)」を有効化
- ステップ数や
refiner switch pointを調整(例:25)
- 左側でプロンプトとモデルを選択
- 必要に応じて ControlNet や Inpainting モードを有効化(別途有効化必要)
- スクリプトを使いたい場合は CLI から
.yaml設定ファイルを使ってバッチ生成が可能
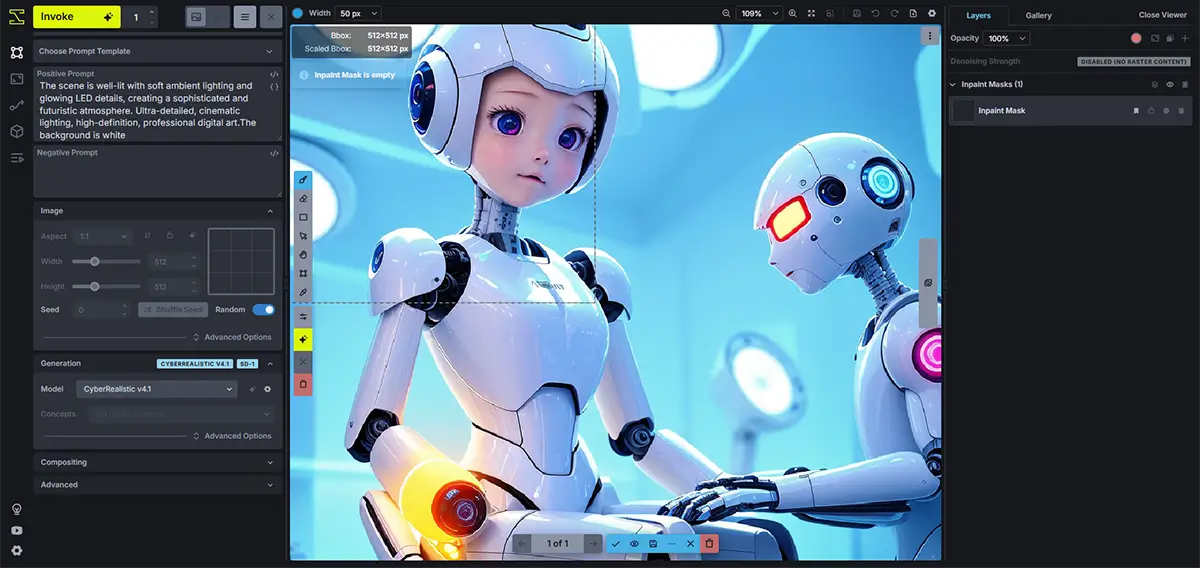
InvokeAIでControlNetを使用するための手順(Web UIベース)について
前提条件
| 要素 | 内容 |
|---|---|
| InvokeAI | バージョン3.0以降(ControlNet対応) |
| GPU VRAM | 最低でも12GB以上推奨(SDXL + ControlNet使用時) |
| モデル | SDXL or SD 1.5 に対応した本体モデルと、それに対応するControlNetモデル |
手順 ①:ControlNetの有効化
ターミナルで以下を実行します
invokeai-configure --enable-controlnet- 対話形式で「ControlNetを有効にしますか?」と聞かれる → 「Yes」
- 完了後、設定が
invokeai.yamlに保存されます - 次回起動時から ControlNetタブ が表示されるようになります
手順 ②:ControlNetモデルの準備
ControlNetモデル(.safetensors 形式)を Civitai や Hugging Face などからダウンロードします。
モデルの例(SDXL用)
| モデル名 | 用途 |
|---|---|
controlnet-sdxl-canny | エッジ制御 |
controlnet-sdxl-depth | 深度マップ |
controlnet-sdxl-openpose | ポーズ制御 |
controlnet-sdxl-scribble | 手書き線画制御 |
保存先
invokeai/ ディレクトリ内の以下に保存します。
models/controlnet/
└── controlnet-sdxl-canny.safetensors手順 ③:Web UIでControlNetを使う
1. InvokeAIを起動
invokeai-webブラウザが開いたら、以下の手順で進めます。
2. モデルの選択(SDXLまたはSD1.5)
- 右上の「モデルセレクター」で SDXLベースのモデルを選択
- 例:
sdxl_base_1.0.safetensorsやRealVisXL,DreamShaper XLなど
3. ControlNetタブを開く
- 画面左下 or 右下にある「ControlNet」パネルをクリックして展開
4. 画像とモデルの指定
- 画像入力:制御に使う画像(ポーズ、線画など)をアップロード
- ControlNetモデル選択:使用するモデルを選ぶ(例:
canny,openposeなど)
ControlNetモデルごとに入力画像の「前処理」が必要です。InvokeAIでは自動でやってくれます。
5. オプション設定(必要に応じて)
- Weight(重み):生成に対するControlNetの影響度(通常0.5〜1.0)
- Control Mode:
- Balanced(バランス)
- Prompt Only(ControlNet無効に近い)
- ControlNet Only(プロンプトより制御画像優先)
- Resize mode:Image resize 方式(通常は
Just Resize)
6. プロンプトを入力して画像生成!
- 通常通り「プロンプト」「ネガティブプロンプト」「ステップ数」「CFG」などを指定
- 「生成」ボタンを押すと、ControlNetの効果が適用された画像が出力されます
複数ControlNetの併用(Multi-Control)
InvokeAIでは、最大 3つまでのControlNetを同時に使用できます(UI上で追加可能)。
例えば:
- OpenPoseでポーズ指定
- Depthで奥行き指定
- Cannyでエッジ指定
→ 高度な構図・表現が可能です。
一括生成(スクリプト実行型)の例
invokeai --from_file your_prompts.txt※ your_prompts.txt に以下のような記述
a cyberpunk cat sitting on a rooftop at night
a wizard casting a fireball, fantasy style
a steampunk robot playing the violinアンインストール
pip uninstall invokeai仮想環境を削除すれば完全にクリーンに戻せます。
公式ドキュメント
公式ドキュメントで確認できる内容
- インストール方法(Windows/macOS/Linux、pip/manual/Docker)
- Web UI の使い方と設定
- CLI や API を使ったバッチ処理への組み込み方法
- ノードベースワークフローの解説
- モデル管理、LoRA、ControlNet 構成
- よくある質問(FAQ) とトラブルシューティング
※商用利用したい方は「モデルのライセンス(例:CreativeML Open RAIL-M)」を必ず確認しましょう。
SDXLで効果的なプロンプト構成
ここでは以下の構成で、用途別おすすめプロンプト例をご紹介します
基本構造:
[主題], [詳細な形容詞やスタイル], [カメラアングルやライティング], [背景や雰囲気], [アートスタイル]例:
A cyberpunk girl wearing glowing neon jacket, cinematic lighting, standing in rainy city at night, artstation concept art
1. キャラクターデザイン向け
a stylish female android, glowing cyberpunk outfit, silver hair, photorealistic, close-up portrait, ultra detailed, dramatic lighting, depth of field, studio background, concept artPOINT:構造と雰囲気を強調しつつ、写実感を出せる。
2. 風景・背景アート向け
a vast floating city in the sky, surrounded by clouds, futuristic buildings with neon lights, sunset light rays, epic scale, wide-angle view, cinematic concept art, trending on ArtStationPOINT:遠景や空気感(霞、霧)を非常に自然に描写できます。
3. ファンタジー・イラスト向け
a forest elf queen with glowing eyes, wearing elegant armor, standing in an enchanted forest, god rays through trees, mystical atmosphere, fantasy art, highly detailed, wlop stylePOINT:「雰囲気」や「光の演出(god rays)」などもSDXLは得意。
4. フォトリアル・ポートレート向け
a Japanese woman in a traditional kimono, standing in Kyoto street, shallow depth of field, natural lighting, photorealistic, captured with Canon EOS R5, 85mm lens, soft focus backgroundPOINT:カメラの種類やレンズまで指定するとよりリアルに。
5. プロダクト・デザイン系
a futuristic ergonomic office chair with glowing blue edges, minimalistic white background, isometric view, highly detailed industrial design, concept rendeXPOINT: 製品イメージ・広告向けにも優秀です。
SDXL向け追加テクニック(プロンプト編)
| テクニック | 例 | 効果 |
|---|---|---|
| カメラ用語 | “bokeh”, “depth of field”, “50mm lens” | 写真のような演出 |
| 光の演出 | “cinematic lighting”, “rim light”, “volumetric fog” | 雰囲気を出す |
| 構図 | “close-up”, “isometric”, “top-down view” | 構図を明確に |
| トレンド用語 | “ArtStation”, “Pixiv”, “Unreal Engine render” | スタイリッシュな絵柄に |
| スタイル名 | “by Greg Rutkowski”, “wlop”, “Studio Ghibli style” | 特定の画風に寄せる |
ネガティブプロンプト(不要なものを排除)
low quality, blurry, distorted, extra limbs, bad anatomy, watermark, signature, jpeg artifacts※SDXLでは不要な要素の除去も効果的です。
SDXLとLoRAとの併用について
- SDXLに対応したControlNetやLoRAは少し対応が遅れています
- InvokeAIではLoRAとControlNetのSDXL対応も進行中(v3.3~3.4系で安定化予定)
SDXL(Stable Diffusion XL)は 言語理解力が高く、複雑な構図やライティングにも強いため、従来のSD1.5よりも自然な描写が得意です。
1. SDXL対応LoRAとは?
SDXLはベースモデルの構造がSD1.5と異なるため、対応するLoRAも別物です。
主に以下の条件を満たすLoRAを使用します
SDXL 1.0 Base モデルに対応(network_dim, base_model が明記されている).safetensors 形式(InvokeAIはこれに対応)
学習時に --network_alpha や --rank を明示したもの
※ Civitai などでは「SDXL」タグがついているLoRAを選ぶ。
2. InvokeAIでのLoRA導入手順(v3.2〜)
手順:
LoRAファイル(.safetensors)を以下に配置
InvokeAI/
├── models/
│ └── lora/
│ └── my_lora_model.safetensors
InvokeAI Web UIを起動し、LoRAセクションを展開モデルロード後、左メニュー → LoRA をクリック
一覧からLoRAを選択し、強度(Weight)を調整(例:0.6〜1.0)
SDXL用LoRAは、0.8〜1.0が推奨されるケースが多いです(SD1.5より強めでOK)
3. SDXL + LoRA のプロンプト活用例
A. キャラクターLoRA(例:「SDXL anime girl」LoRA)
a beautiful anime girl with silver hair, blue eyes, wearing a school uniform, standing in a field of flowers, soft lighting, 4K, SDXL anime style→ LoRA名:animeGirl_SDXL.safetensors を適用(Weight: 0.9)
B. ファッション・衣装LoRA(例:「Kimono」LoRA)
a Japanese woman in a detailed kimono, sitting by the river in Kyoto, cinematic lighting, photorealistic, bokeh→ LoRA名:kimono_SDXL.safetensors(Weight: 1.0)
C. アートスタイルLoRA(例:「WLOP SDXL」LoRA)
a female knight with glowing sword, standing on a cliff, epic lighting, misty background, dramatic fantasy painting→ LoRA名:wlop_SDXL.safetensors(Weight: 0.8〜0.9)
4. LoRAを複数組み合わせる
InvokeAIでは複数LoRAの同時使用も可能です
animeGirl_SDXL.safetensors → Weight: 0.8
kimono_SDXL.safetensors → Weight: 1.0
両方適用すれば、「和風衣装を着たアニメ風キャラ」が生成できます。
※互いに干渉しすぎる場合(例:絵柄とポーズLoRAの衝突)は崩れるので、組み合わせは少しずつテスト推奨。
SDXL用LoRAの探し方(Civitai例)
検索バーに「LoRA SDXL」または「SDXL 1.0」と入力
フィルターで「Base Model → SDXL 1.0」を選択
ファイル名に「.safetensors」が含まれていることを確認
SDXL対応LoRAおすすめ10選
- ComicXL_V1アメリカンコミック風ポップ。
- Crazy Portraitオシャレでポップな配色。
- Cute Animals優しい雰囲気の動物系。
- Dissolve Styleリアル系の絵柄。
- Fantastical Realismリアルファンタジー系SF要素も。
- Fractal Geometry Styleフラクタルの名の通りパターン化される造形美。
- Neon Style XLネオンカラーがオシャレなサイバー系。
- Paint Splash Styleペインティングアート。
- Pencil Drawingその名の通りドローイング。伝統と革新。
- Mosaic Texture SDXL懐かしい感じのタイルアート風。
選び方のポイント
- 用途に応じたアートスタイルで選定(例:キャラ向け / 風景 / 抽象アートなど)
- Weight調整:初期は0.8~1.0で試し、出力感が弱い・強すぎると感じたら0.6~1.2範囲で調整
- プロンプトとの併用:本体プロンプトにスタイル名や演出ワードを加えると相乗効果あり
SDXL × ControlNet を InvokeAI で使う際のポイント
1. invokeai-configure --enable-controlnet でControlNetを有効化
このコマンドでControlNet機能が有効になり、起動時にControlNetタブが表示されるようになります。
すでに invokeai-configure でセットアップ済みの場合でも、再実行すればControlNetを後から追加できます。
2. SDXLモデルを読み込んでおく
SDXLベースのモデル(例: sdxl_base_1.0.safetensors など)を使用するには、models/sdxl ディレクトリに入れておく必要があります。
InvokeAI では、自動でSDXLモデルを識別し、「SDXL」モードとして扱ってくれます。
3. SDXL用のControlNetモデルを用意する
SDXLは、1.5用ControlNetとは互換性がありません。必ず「SDXL用のControlNetモデル(~sdxl~.safetensors)」を使う必要があります。
モデルの配置場所
models/controlnet フォルダに以下のように格納します
models/controlnet/
├─ canny_sdxl.safetensors
├─ depth_sdxl.safetensors
└─ openpose_sdxl.safetensors4. Web UI または CLI で使用する
Web UIの場合:
- モデルとして SDXL を選択
- ControlNet タブを有効化
- 使用したいControlNetモデルを選択(例: canny、depth、poseなど)
CLIの場合:
生成コマンドで --control_net オプションを使い、ControlNetを有効にします(ただし詳細設定には注意が必要なのでGUIの方が扱いやすいかも)。
SDXL対応ControlNetの代表的なモデル例
以下は、SDXLに対応しているControlNetモデル(一部)です。
| モデル名 | 説明 |
|---|---|
controlnet-sdxl-canny | エッジ画像から形状を制御 |
controlnet-sdxl-depth | 深度マップから立体感を再現 |
controlnet-sdxl-openpose | ポーズ情報を元にポーズを再現 |
controlnet-sdxl-scribble | 手描き線画から元画像を生成 |
controlnet-sdxl-seg | セグメンテーション画像で領域制御 |
controlnet-sdxl-lineart | 線画風画像から制御 |
controlnet-sdxl-mlsd | 直線構造の特徴を使って建築物などに有効 |
Hugging FaceやCivitaiなどで「sdxl controlnet」で検索すると、対応モデルが見つかります。
SDXL ControlNetの活用例
① 手描きラフ → イラスト風画像に
controlnet-sdxl-scribbleを使えば、ざっくり描いたスケッチを元にイラスト化できます。
② ポーズ写真 → キャライラストに
controlnet-sdxl-openposeにポーズ画像を与えると、そのポーズを保ったまま生成可能。
③ 線画 → フルカラー画像に
controlnet-sdxl-lineartを使えば、線画に忠実なカラーイラストを生成。
④ 建物写真の輪郭 → アニメ背景に
controlnet-sdxl-mlsdを使うと、建築物などのパースを活かした絵作りが可能。
⚠️ 注意点
- SDXL用ControlNetはファイルサイズが大きく(2〜4GB)、VRAMを多く消費します(12GB以上推奨)。
- 通常のControlNetと同様に、**重ねがけ(Multiple ControlNet)**も可能ですが、計算コストは増えます。
- SDXLベースのモデル(例:Juggernaut XL, RealVisXL, DreamShaper XLなど)と相性が良いです。