文章用LoRAを最短で作る方法|Windowsでの環境構築&学習手順まとめ
今回は、文章用LoRAを最短で作りたい方向けのガイドです。
Windows環境で、Python・Transformers・LoRAを使った軽量学習をステップごとに解説しています。
「どこから手をつければいいか分からない」という方でも、仮想環境の準備からデータ作成、学習、テスト、Web公開まで一気に理解できる内容になっています。
本記事を読み進めれば、キャラクターや文章の個性を生かしたLoRAモデルを、自分のPCで簡単に作成・確認・公開することが可能です。
本記事で分かること
- WindowsでLoRA学習環境を最短で構築する方法
- キャラクターテキストの整理とLoRA学習用データ準備
- PythonスクリプトでのLoRA学習の実行手順
- 複数LoRAファイルの統合(マージ)方法
- LoRA適用後の動作確認とテスト方法
- Gradioを使ったWebUIでのLoRAモデル公開手順
目次
AI学習環境
※ローカルファイルの場所C:AI(今回は、こちらで行っていきます。コピペしてご利用の場合は、ファイル場所の置き換え、確認をお願いします。)
環境確認
(Windows + Python 3.10 + Transformers 4.56.0)で文章用LoRAを最短で作成する
- PythonでTransformers確認

python -m pip show transformersバージョンやインストール先が表示されればOK
2.Pythonからの利用確認
仮想環境をアクティベートしてPythonを起動
python
そして、
import transformers
print(transformers.__version__)エラーが出なければローカルで文章用LoRA作成に使用可能
GPU確認(ある場合)
import torch
print(torch.cuda.is_available())3.Pythonインタプリタを抜ける
exit()ステップ0:準備
CMD(コマンドプロンプト)の画面に戻る
C:\AI>今の表示が
C:\Users\Owner>になっている場合は、仮想環境をアクティベートしていない状態の通常のコマンドプロンプトです。
仮想環境 (venv_lora)に入る。 既存の仮想環境に入る場合
cd C:\AI
.\venv_lora\Scripts\activate1. 仮想環境(推奨)※新規に仮想環境を作る場合(既存の仮想環境がある場合はスルー)
- グローバル環境に入れず、独立環境で管理するのが安全です。
cd C:\AI
python -m venv venv_lora
.\venv_lora\Scripts\activatepython -m venv venv_lora # 仮想環境を作る
.\venv_lora\Scripts\activate # 仮想環境に入る
2. ライブラリインストール
① GPU環境で使う場合(CUDA 12.1対応GPUドライバがある前提)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121これで GPU版PyTorch が入ります。
(インストール後に import torch; print(torch.cuda.is_available()) で True になれば成功)
② 学習に必要なライブラリ
pip install peft accelerate datasets safetensors transformers- peft → LoRA など軽量学習の仕組み
- accelerate → 学習を最適化(GPU / CPU 自動切替など)
- datasets → Hugging Face のデータセット読み込み
- safetensors → LoRA保存形式(高速・安全)
- transformers → モデル本体の利用
⚠️ 注意点
- CUDA版PyTorchは、自分のPCに入っている NVIDIAドライバのバージョン と一致している必要があります。
(例: CUDA 12.1 対応 → ドライバ 530 以降)
ステップ1:データ準備
- キャラクター台詞をテキストファイルにまとめる
例:sakasa.txt - 行ごとに1文ずつ記載
- キャラごとに別ファイルでもOK
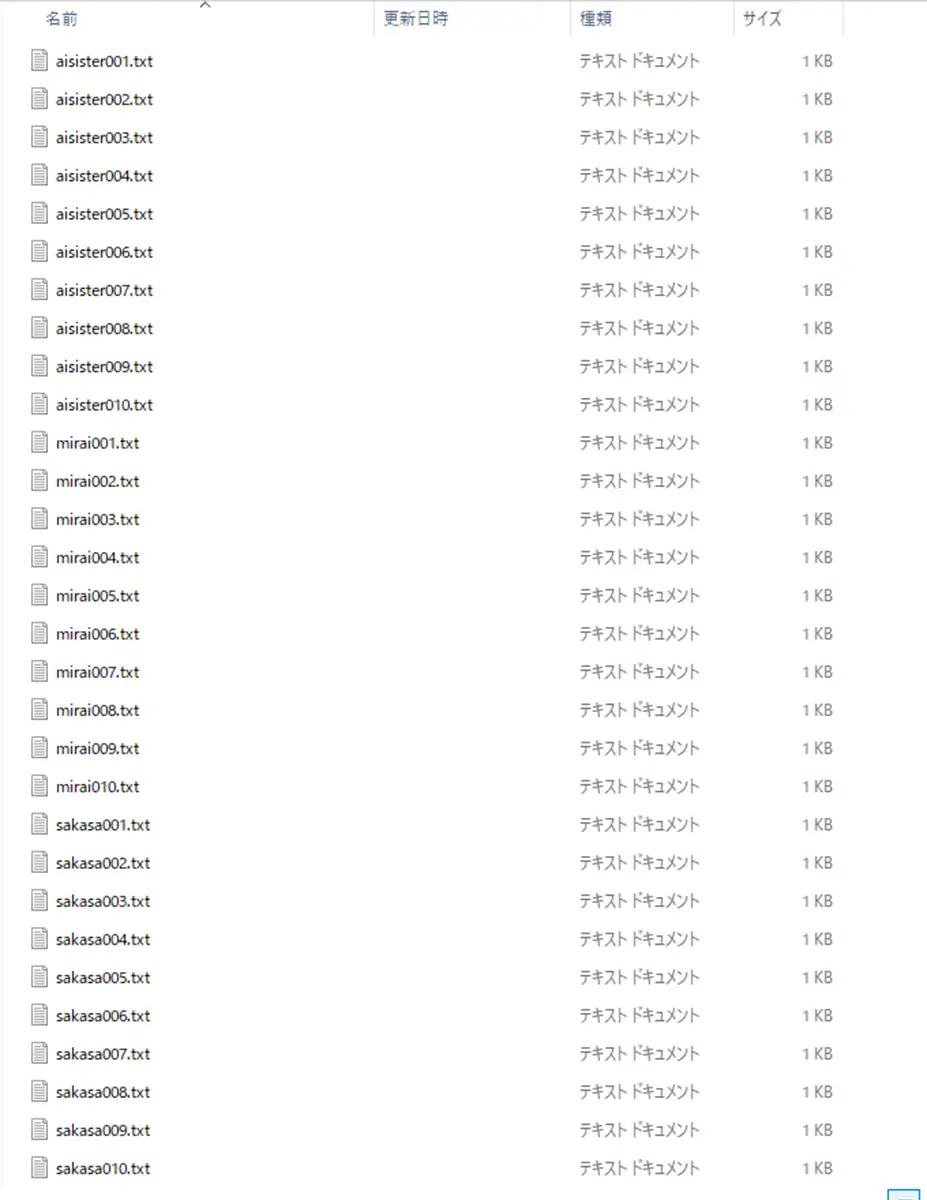
行ごとに1文ずつ書く
キャラごとに別ファイルにしておく。
aisister,mirai,sakasaキャラ毎にファイルに入れる
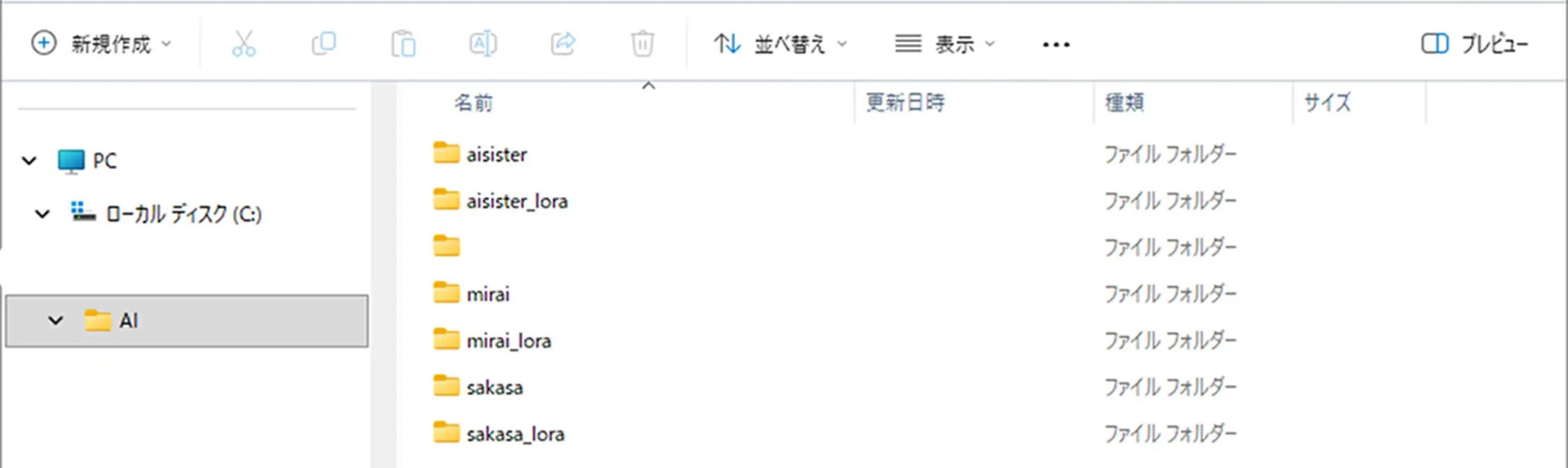
aisisterが、テキストファイルをまとめたフォルダaisister_loraは出力用フォルダ
ステップ2:学習スクリプトの準備
今回は、aisister_loraを作成するので、メモ帳などで、train_aisister_lora.pyファイルを書く
※aisister_loraこの名前の個所は、それぞれ、任意の名前で作成してください。
<strong>train_aisister_lora.py</strong>の基本構造
from transformers import AutoTokenizer, AutoModelForCausalLM, Trainer, TrainingArguments
from datasets import load_dataset
from peft import LoraConfig, get_peft_model
import torch
# ベースモデルとトークナイザー
base_model_name = "EleutherAI/gpt-neo-1.3B"
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
model = AutoModelForCausalLM.from_pretrained(base_model_name)
# LoRA設定
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj","v_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
# データセット
dataset = load_dataset("text", data_files={"train":"sakasa.txt"})
# トークナイズ関数
def tokenize(batch):
return tokenizer(batch["text"], padding="max_length", truncation=True, max_length=128)
tokenized_dataset = dataset.map(tokenize, batched=True)
# 学習設定
training_args = TrainingArguments(
output_dir="./aisister_lora_file1",
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
num_train_epochs=3,
logging_steps=10,
save_steps=50,
save_total_limit=2,
fp16=True,
push_to_hub=False
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"]
)
# 学習開始
trainer.train()
trainer.save_model("./aisister_lora_file1")ポイント
tokenizerはpadding=True, truncation=Trueを指定しておくと、「tensor作れない」エラーを防げる。- バッチサイズや
gradient_accumulation_stepsは調整。
train_aisister_lora.pyも、先程のaisisterや、aisister_loraフォルダと一緒のフォルダに入れておく
ステップ3:学習の実行
- 仮想環境をアクティベート
cd C:\AI
.\venv_lora\Scripts\activate2.学習スクリプトを実行
python train_aisister_lora.py
学習が進むと C:\AI\aisister_lora_file1\adapter_model.safetensors が作成されます
複数のテキストファイルで学習する場合は、順次フォルダを変えて学習し、最後に 統合 。
ステップ4:複数LoRAファイルの統合(マージ)
[00:00<00:00, 1.63it/s] LoRA 中間保存: ./sakasa_lora_file10 LoRA 最終保存: ./sakasa_lora上の様に、最終保存ファイルが出力されれば終了です。
最終保存ファイルが出力されなかった場合は、下のコマンドを実行してください。
# 例: peftのmerge_lora.py で統合
python merge_lora.py \
--lora_dirs "aisister_lora_file1" "aisister_lora_file2" "aisister_lora_file3" \
--output_dir "aisister_lora_merged"- 統合後は
aisister_lora_merged/adapter_model.safetensorsが完成 - 推論時はこのフォルダを指定してモデルに適用
ステップ5:動作確認(任意:Pythonインタプリタで)
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
base_model_name = "EleutherAI/gpt-neo-1.3B"
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
model = AutoModelForCausalLM.from_pretrained(base_model_name)
lora_path = r"C:\AI\aisister_lora\aisister_lora_merged\adapter_model.safetensors"
model = PeftModel.from_pretrained(model, lora_path)
model.eval()
prompt = "こんにちは、私は AI Sister です。今日の天気は"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- ここで自然な文章が生成されれば、LoRA学習は成功です
- 問題があれば
max_lengthやバッチサイズ、学習ステップ数を調整
ステップ6:【テスト】 Spaces でテストする
- フォルダ構成
(Spaceのルート)
├─ <span class="swl-bg-color has-swl-deep-03-background-color">app.py</span>
├─ adapter_model.safetensors <span style="--the-icon-svg: url(data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9IjFlbSIgd2lkdGg9IjFlbSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIiBhcmlhLWhpZGRlbj0idHJ1ZSIgdmlld0JveD0iMCAwIDQ0OCA1MTIiPjxwYXRoIGQ9Ik05LjQgMjMzLjRjLTEyLjUgMTIuNS0xMi41IDMyLjggMCA0NS4zbDE2MCAxNjBjMTIuNSAxMi41IDMyLjggMTIuNSA0NS4zIDBzMTIuNS0zMi44IDAtNDUuM0wxMDkuMiAyODggNDE2IDI4OGMxNy43IDAgMzItMTQuMyAzMi0zMnMtMTQuMy0zMi0zMi0zMmwtMzA2LjcgMEwyMTQuNiAxMTguNmMxMi41LTEyLjUgMTIuNS0zMi44IDAtNDUuM3MtMzIuOC0xMi41LTQ1LjMgMGwtMTYwIDE2MHoiPjwvcGF0aD48L3N2Zz4=)" data-icon="FasArrowLeft" data-id="58" aria-hidden="true" class="swl-inline-icon"> </span>先程の作成したLoRAファイル
├─ adapter_config.json
├─ requirements.txt
app.py(Gradio 簡易UI)
メモ帳などで、作作成しておく
import gradio as gr
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
import torch
# ベースモデル
base_model_name = "EleutherAI/gpt-neo-1.3B"
# トークナイザーとモデルの読み込み
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
model = AutoModelForCausalLM.from_pretrained(base_model_name)
# LoRAの適用(フォルダ名だけでOK)
# LoRAファイルが同じSpace内にある場合、相対パスだけでOK
model = PeftModel.from_pretrained(model, "./") # app.py と同じディレクトリにある場合
model.eval()
# 推論関数
def generate_text(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=50)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Gradio UI
iface = gr.Interface(
fn=generate_text,
inputs=gr.Textbox(label="プロンプトを入力"),
outputs=gr.Textbox(label="生成結果"),
title="AI Sister LoRA テスト"
)
iface.launch()requirements.txt
文章LoRAのテスト用に必要なライブラリ。
# LoRA テスト用最小限 requirements.txt
# Transformers ライブラリ(Hugging Face モデル用)
transformers>=4.35
# PEFT(LoRA 適用用)
peft>=0.5.0
# TRL(必要に応じて)
trl>=0.8.0
# PyTorch(GPU対応)
torch>=2.1.0
# Safetensors(高速モデル読み込み用)
safetensors
# Gradio(WebUI用)
gradio>=3.53torch→ PyTorch本体(GPU対応版ならtorchのインストール時に自動で対応)transformers→ モデル読み込み用peft→ LoRAモデル読み込み用gradio→ WebUI作成用safetensors→ LoRAの安全高速なモデル保存形式用
Spaces での公開手順
HuggingFaceにログイン
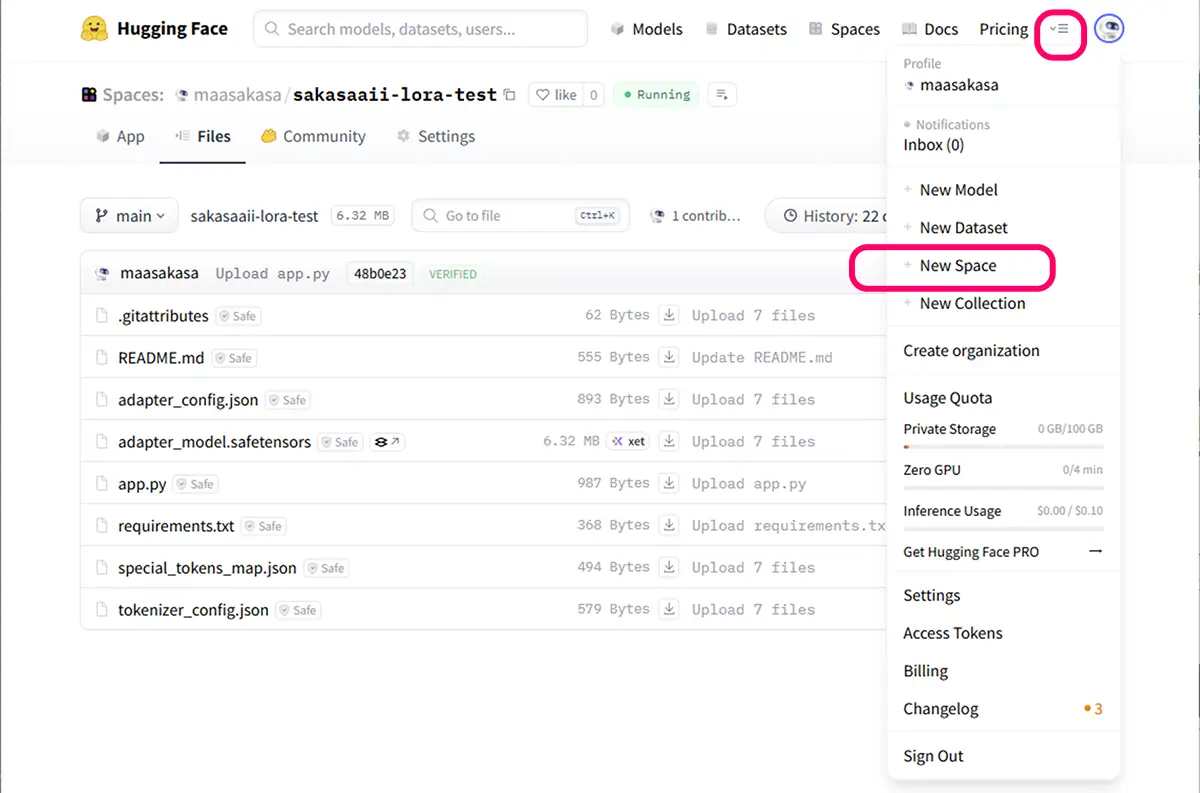
New Space を作成
- 名前例:
aisister-lora-test - SDK:
Gradio - Hardware:
GPUを選択
ローカルフォルダの内容を Git で pushまたは Upload files で app.py と aisister_lora_merged/adapter_model.safetensors をアップロード
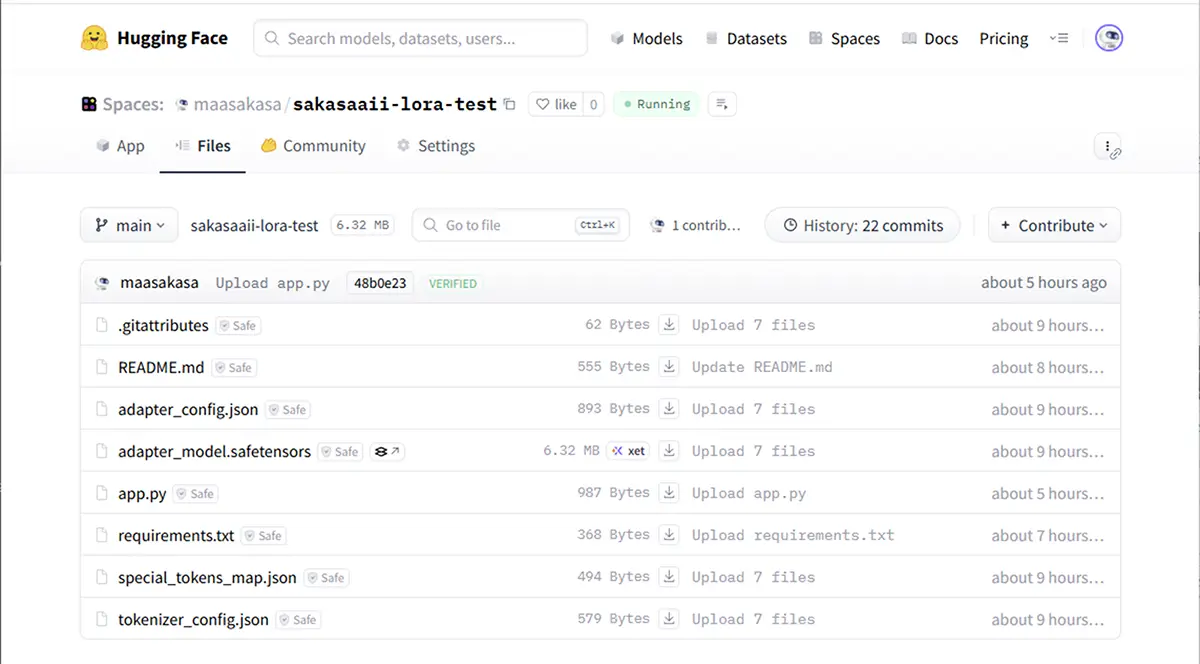
- 数分待つと自動でビルドされ、WebUI が起動
テスト
プロンプトを入力に文章を入れると LoRA を適用した生成結果が返る- Web から誰でも触れます(共有リンクを取得可能)
軽量化したい場合、max_new_tokens を 50 → 30 くらいにすると高速
LoRA のみ更新した場合は、adapter_model.safetensors を置き換えるだけで反映されます。