【自作イラストをLoRA化】画像とキャプション(テキストタグ)の準備からフォルダ構成まで徹底解説

学習用データセットの作り方
LoRA(Low-Rank Adaptation)は、既存のAIモデルに対して、自分のイラストや作風を学習させられる技術です。
でもいざ始めようとすると──
「どの画像を選べばいいのか?」
「タグの作り方は?」
「フォルダ構成って好きにしていいの??」
といった疑問が次々と出てきます。
この記事では、自分の作品をもとにLoRAを学習させたい方のための、画像選定・タグ設計・フォルダ構成といった“学習セットの作り方”を徹底解説します。
専門的には「データセット」と呼ばれるこの工程こそ、AIが個人の作風を正確に学ぶための“土台”になります。
 未来
未来「ただ学ばせる」だけでなく、自分らしさをしっかり活かすために何が必要なのか、順を追って見ていきましょう。
 SAKASA
SAKASAここが一番肝心だね!
目次
LoRA用 学習セット設計ガイド
1. 【画像選定】──LoRA学習の“核”になるステップ
まずは、AIに学ばせたい「自分らしい作品」を選びます。
選定のポイントは以下のような観点です。
- 作風の一貫性(色使いや線のタッチが似ている)
- スタイルの特異性(他と明確に違う、独自の個性がある)
- 表現の代表性(「これぞ自分の絵」と言える代表作)
- ジャンル別の整理(例:写実画/イラスト/動物、など)
目安としては、最低15〜30枚程度(キャラが複雑(服装や小物が多い)再現な程、再現率が下がる)から始めるとバランスが良く、学習効率も上がります。(多ければ多いほどいい)
ここでの POINT
同じキャラクターやモチーフが繰り返し登場する作品は特に強力で,
左右を反転させたり、口だけ、目だけ、変えて(差分)枚数を増やす(差分)のもアリです!
また、色数が多すぎず、ある程度パターンがある作品は、AIにとっても学びやすいようです。
SAKASA AI
【差分イラストの作り方】表情・ポーズを変える方法&LoRA学習素材 | SAKASA AI 「差分イラストの作り方」を徹底解説。Automatic1111やControlNetを使った表情・ポーズ差分の作り方から、LoRA学習用素材作成まで、初心者でもわかる制作フローを紹介。
2. 【画像前処理】──AIに「作品の本質」を伝える
選んだ画像はそのまま使うのではなく、AIが学習しやすい形に整える必要があります。
LoRA学習では、正確な特徴抽出と一貫性のある学習がとても重要。前処理を丁寧に行うことで、精度の高い再現が期待できます。
私はPhotoshopを使用していますが、主に以下の事が出来る写真編集用ソフトを使用して編集していきます。
- 解像度の統一
768px × 768px または 512px × 512px などサイズを統一します。モデルによって推奨解像度が異なることもありますが、迷ったら768pxでOK。(下で解説。) - リサイズ方法
アスペクト比を維持しながらのリサイズ、または中心を基準にトリミングして正方形に整えます。全体のバランスが崩れないように注意しましょう。 - 明るさや色味の調整
作品ごとの見た目にバラつきが出ないように、明るさや色調を可能な範囲で調整します。
→ たとえば「夜の作品」と「昼の作品」を混ぜる場合も、光量や色温度を揃えると統一感が出ます。 - 歪み補正
カメラで撮影した場合などにありがちな「傾き」や「パースの歪み」は、可能な範囲で修正しておきましょう。 - ノイズ除去(軽くでもOK)
デジタル画像のザラつきやゴミは、AIの学習ノイズになることも。気になる場合は、軽くノイズ除去をしておくとより効果的です。
ここでのPOINT
前処理の目的は「AIに余計な情報を与えず、本質だけを学ばせること
手間はかかりますが、後の学習精度に直結する重要な工程です。
画質や色味を一括で揃える方法はこちらの記事で書いています
大量画像の一括処理の方法
大量画像も一瞬で統一!Photoshopバッチ処理でキャラクターの色味を揃える方法 Photoshopを使用して、画像の色味を一括で揃える方法4選 Photoshopで「アクション+バッチ処理」を行い、数十枚~数百枚程度の画像の色味を一括変換する方法。用途:(A…
一般的なLoRA学習サイズ(正方形系)
| 解像度 | 用途・特徴 |
|---|---|
| 512×512 | 最も標準的。SD 1.5系で推奨される基本サイズ。 多くの既存モデルがこのサイズで訓練されている。 |
| 640×640 | SDXL系や高解像度LoRAの作成に使われる。ディティール保持に有利。 |
| 768×768 | SDXLベースのLoRAでよく使われる。高性能GPU環境向け。 |
| 1024×1024 | SDXLに最適なサイズのひとつ。ただしVRAMを大きく消費する。 |
SD 1.5系(ベースモデルが512×512) では、入力画像も512×512の方が学習精度が安定します。
SDXL系(ベースが1024×1024) では、それに合わせて768や1024サイズの画像が推奨されます。
長方形タイプのLoRAサイズ(非正方形)
| 解像度 | 用途・注意点 |
|---|---|
| 512×640 | 縦長のキャラ画像向け。画像生成にも合わせやすい。 |
| 640×512 | 横長構図向け。背景や構図重視LoRAなどで利用される。 |
| 768×512 | 横長構図でも高解像度を意識した学習に有効。 |
| 768×1024 | 高品質な縦長画像のLoRAを作る際に使用。VRAM負荷大。 |
例外的にPNGにしておくと良い場合
- 透過背景のあるデータ(後で使う予定がある)
- グラデーションや線が非常に細かく、画質を絶対に落としたくない
- 後で動画化や編集(切り抜き)に使うつもりがある
VRAMについて
VRAMを多く消費する LoRA学習 ではGPUのスペックが足りないと途中で止まってしまいます。
VRAMが12GB以下の場合は、クラウドGPUの使用がおすすめです。
▶ GPUの VRAM容量の確認方法(Windows)は、こちらをクリックして下さい。
⚠️ 注意
VRAM(GPUメモリ)とは、画像生成やAI処理で使用される
GPU専用のメモリ容量のことです。
※ PCのメモリ(RAM)とは別物です。

Windowsの場合:
スタートボタンを左クリックタスクマネージャー → パフォーマンス → GPU → 専用GPUメモリ
”専用GPUメモリ”に記載されている容量がGPUのVRAMです。
LoRA学習やStable Diffusionでは、GPUのVRAM容量(例:8GB / 12GB)が重要になります。
クラウドGPURunpodの使い方
【RunPodの料金と使い方】Stable Diffusionなどで画像生成やLoRA学習をする方法【②実践編】 RunpodでStable Diffusion系画像生成やLoRA学習をする方法 Stable DiffusionやLoRA学習では、長時間GPUをフル稼働させるため、発熱や電源の安定性が大きな課題になりま…
次のステップで使用できるツール
| ツール | 特徴 |
|---|---|
| Adobe After Effects | モーショングラフィック・パペットツールに最適 |
| Blender | 3D・2Dモーション、リギングも可能 |
| EbSynth | キーフレームからの動き生成に最適(画像→動画) |
| AnimateDiff + ControlNet | AIを使ったイラスト→動画化の手法 |
| Live2D Cubism | パーツ分けイラストを動かすのに特化(顔・髪・体) |
3. 【caption(タグ付け)】
キャプショニングはLoRA学習における最大の難関の一つで、感覚的な判断が入りやすいため、人によって精度や傾向が大きく分かれます。
LoRAは「特定の画像とテキストの対応関係」を学習する仕組みです。“視覚的な意味づけ”を補完する言語(タグ)で個性を際立たせることがLoRA成功の鍵となります。
例:
画像:赤い帽子をかぶった少女 → テキスト:red hat, girlこの関係性を数百回繰り返して学習し、「red hat」とプロンプトに打てば赤い帽子を出せるようにします。
つまり、正確なタグ付けがLoRAの効果に直結します。
多くの人がツールを使う理由
- 一貫性を保てる:人力だと同じモチーフでも表現がブレやすい。ツールならAI目線の一定のロジックで出力される。
- 時短になる:大量の画像に手作業でタグ付けするのは現実的でない。
- ベースとして便利:自動タグ付け結果を「土台」として手動で修正していく使い方。
SAKASA AI
【最新版】LoRA学習用画像に自動キャプション(タグ)付けする方法|kohya_ssのWD14 TaggerとBLIP2 | SAKAS… kohya_ssのCaptioning機能まとめとWD14 TaggerとBLIP2の違いと使い分け これまで、 画像タグ生成のために外部ツールとして個別で使用されることが一般的だった WD14 tagger…
※画像の枚数が少ない場合などは手動の方が良い場合もあります。ある程度の枚数がある場合は、ハイブリッドがおすすめです。
自動タグ付けツールの例(Kohya_ss対応)
| ツール名 | 概要 | 備考 |
|---|---|---|
| BLIP / BLIP2 | 画像の内容を自然文で説明する | caption by BLIP ボタンで実行可能 |
| Caption Anything | 自然言語のキャプション向き | ChatGPT APIなどを活用し、柔軟な説明文生成が可能。 |
| DeepDanbooru | 主にアニメ画像向けのタグ抽出 ※中級者〜上級者向け | 「tagファイル」形式で出力される(例:girl, long hair, smileなど) |
| WD 14 Tagger(DeepDanbooruベース) | DeepDanbooruベースの自動タグ付け拡張機能 | anime-style系に強い。AUTOMATIC1111拡張機能として利用可能。 |
手動でのコツ
| やること | 例 |
|---|---|
| 見たままを丁寧に表現 | abstract, surreal, humanoid, faceless, glowing eyes |
| 自分の表現世界を言語化 | ethereal being, dreamlike space, floating shapes |
| 構図や色も含める | soft pastel colors, centered composition, minimal background |
英語での記述推奨(Stable Diffusionは英語ベース)」
タグ(caption)の作成
LoRA学習スクリプト(例:Kohya_ss)は基本的に テキストファイルからタグを読み込む 仕様になっていることが多い為、
テキストタグの作成は、LoRA学習ファイルの管理に最適な、VSCodeなどを使用して、使用する方法がおすすめです。
VSCodeについては、こちらの記事で、書いています。
【AI生成・LoRA制作向け】メモ管理とタグ編集を【VS Code】で効率化する方法 VS Codeで快適作業環境 タグ付けには、Windowsのメモ帳を使用していましたが、ふと、思い立ってVScodeを使い始めました。 メモ帳でも問題なかったのですが・・・やはり…
もちろん、メモ帳などのテキストエディタで作成しても、テキストタグ.txtファイル自体の作成方法は同じです。
メモ帳などのテキストエディタで手動でタグ.txtファイルを作る手順
例:メモ帳の場合
- メモ帳を開く
- スタートメニューで「メモ帳」と検索
- タグを入力する
例:abstract humanoid, glowing eyes, faceless being, surreal, dreamlike, soft colors
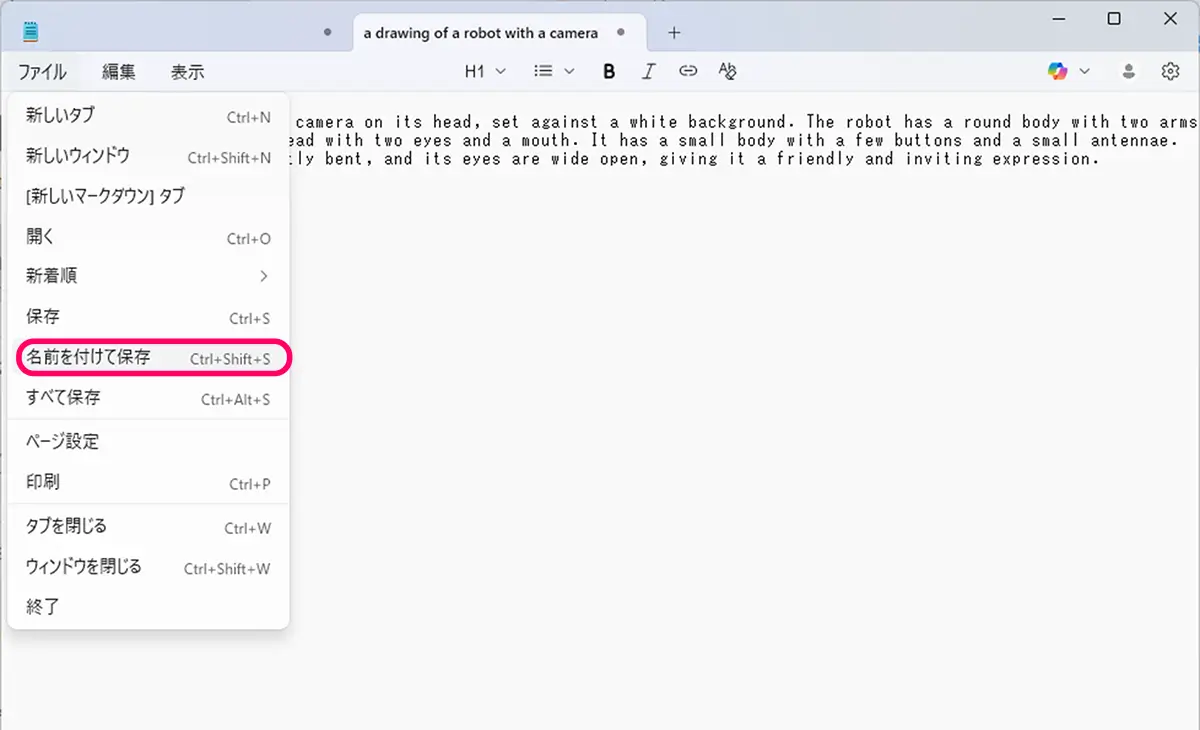
- 名前を付けて保存
- 保存時に「ファイルの種類」を「すべてのファイル」に変更
- ファイル名を「001.txt」のように入力(画像ファイル名と揃える)
- 文字コードはそのままでOK(UTF-8)
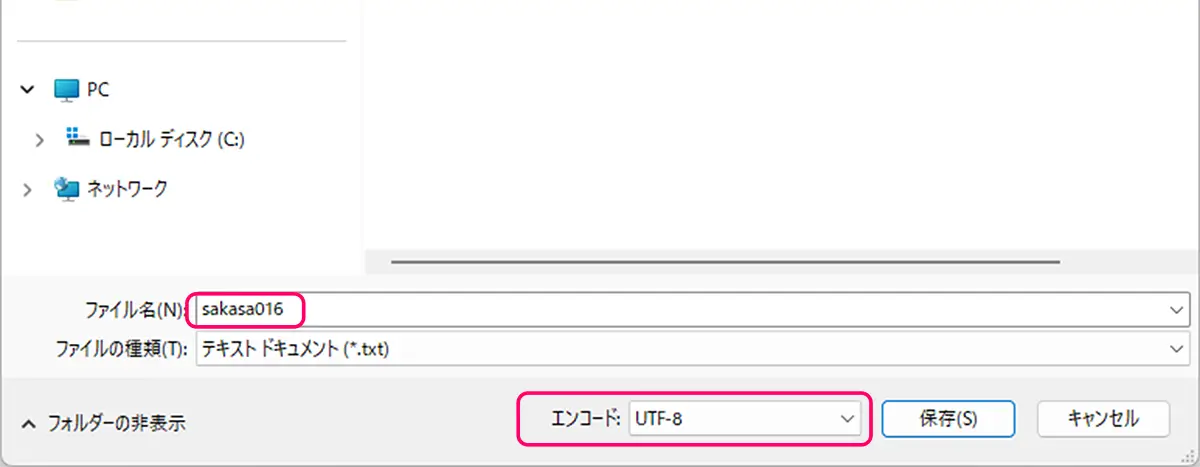
.txtファイルの中身例
(例)abstract humanoid, glowing eyes, faceless being, surreal, dreamlike, soft colorsこのタグ情報が、AIに「どういう絵なのか」を伝える言葉になります。英語で、簡潔かつ視覚的に意味のある言葉を使用して、多くても10〜15ワード以内にまとめます。
トリガーワード
キャプション(=タグ)内には LoRA の「トリガーワード」=フォルダ名(class名)を含めると、使用時にそのトリガーワードで呼び出す事が出来る様になります。
※上の例では、abstract humanoid が LoRA の「トリガーワード」(=フォルダ名)にあたります。
そのため、フォルダ名を 10_abstract humanoid のように設定しておくと、
プロンプトで abstract humanoid と入力したときにLoRAが正しく反映されます。
4. 【データ拡張(あれば)】
学習枚数が少ない場合は、以下の方法で同じ画像の別バージョンを作成
- クロップ(中心以外を切り取ったバージョン)
- 彩度・明度・角度の微調整版
→ あくまで「別画像」として使える程度に調整
5. LoRA学習時の設定
トリガーワード(Trigger Word)の設定
LoRAを作成したあと、プロンプトで特定の作風やキャラクターを呼び出すために使う「合言葉」のようなものが トリガーワード(trigger word) です。
たとえば、キャラ名や特徴を「sks_char」「mylora_style」「mycat」などの短い単語で設定します。
このトリガーワードは、学習時に「フォルダ名」や「テキストキャプション」に含めておくのが基本です。
そうしておくことで、LoRAを使用する際にプロンプトから簡単に呼び出せるようになります。
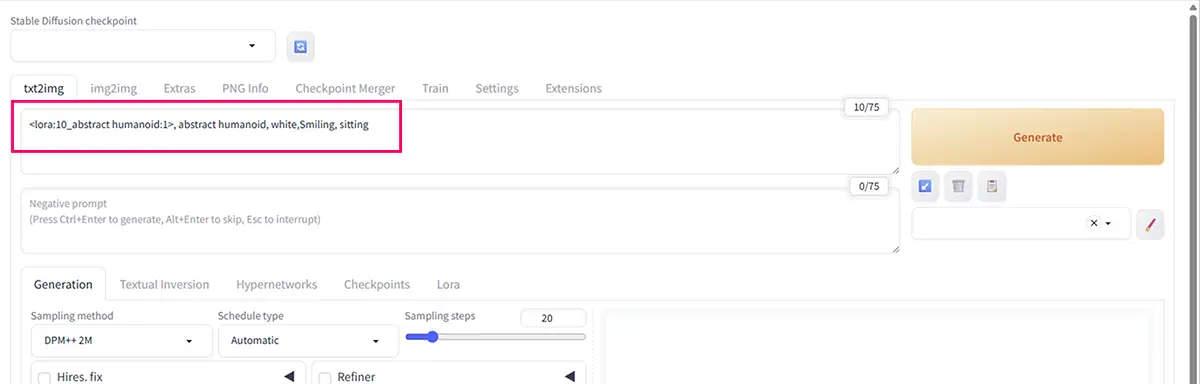
<lora:mylora:1>, mylora_style, girlたとえば、先ほどのタグ作成の項目で挙げた例を使うと、次のようになります。
(例)<lora:10_abstract humanoid:1>, abstract humanoid, white,Smiling, sittingこのように、プロンプトに LoRA名(フォルダ名)とトリガーワードを組み合わせて入力するだけで、
そのLoRAが学習した特徴(作風・キャラ・質感など)を反映させることができます。
ポイント:
- Kohya_ssでは「フォルダ名の class 部分」がトリガーワードとして自動的に使われる
例:10_mylora→ トリガーワードは「mylora」 - プロンプトで明示的に呼び出すと、LoRAがより安定して反映される
- キャラクター系LoRAでは「char」「name」「style」などの命名ルールを統一すると管理しやすい
各種設定項目
- base model:
Stable Diffusion 1.5など(最初はこれで試してみる) - resolution:学習モデルの多くが正方形対応(例:SD1.5=512×512, SDXL=1024×1024)です。
- learning rate:
0.0001〜0.0005 - dim/rank:
4~16(小さめスタート推奨) - epoch:2~10程度(枚数で調整 ※下に記載)
適切なepoch数は?
LoRAの学習では、以下のような基準がよく使われます
| データ量 | 推奨epoch | コメント |
|---|---|---|
| 画像 10〜20枚 | 6〜10 epoch | 少ない枚数なら多めに |
| 画像 30〜50枚 | 3〜8 epoch | 一般的な枚数なら中程度 |
| 画像 100枚以上 | 1〜4 epoch | 多すぎると過学習になりやすい |
フォルダの作成
たとえば「cat」というプロンプトで、データを繰り返さない(1回だけ)場合1_cat
たとえば「cat」というプロンプトで、データを10回繰り返す場合10_cat
たとえば「dog」というプロンプトで、データを15回繰り返す場合15_dog
繰り返し回数(repeats) → ステップ数に影響する
→ 1枚の画像を何回使うか(エポック内で何回繰り返すか)
class → プロンプトで使う「トリガーワード」やカテゴリ名
→ トリガーワードは、上の、10_catの場合catは、”cat”15_dogなら、”dog”です。
フォルダ名のルールとトリガーワードの関係
たとえば次のようにフォルダ名をつけた場合:
| フォルダ名 | 意味 | トリガーワード |
|---|---|---|
1_cat | 「cat」というプロンプトで、画像を1回だけ使う | cat |
10_cat | 「cat」というプロンプトで、画像を10回繰り返す | cat |
15_dog | 「dog」というプロンプトで、画像を15回繰り返す | dog |
【フォルダ名について】
フォルダ名は、<繰り返し回数>_<class>で構成する必要があります。
classとは、「この画像が何を表しているのか」をモデルに伝えるための“タグ(単語=トリガーワード)”です。Kohya_ssでは、画像ファイルのフォルダ名を自動的に使って、プロンプトとして学習に利用します。
データセットの構成イメージ
/10_train/
├── 001.jpg
├── 001.txt ← タグを書いたテキストファイル
├── 002.jpg
├── 002.txt
...10_trainというフォルダに画像と、タグのタイトルをそろえて入れた場合。
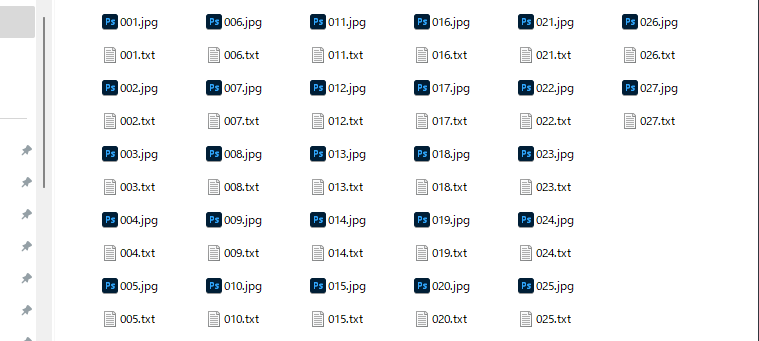
画像と同名のテキストファイル(.txt)を作成して、フォルダにまとめる。
例:
- image001.pngorimage001.jpg
- image001.txt →girl, pastel color, dreamlike, soft lightなど、テキストが書かれた.txtファイル。
LoRA学習時おすすめのフォルダ構成
C:\Users\Owner\kohya_ss\
├── kohya_dataset\ ← データ系(学習素材)
│ ├── 10_cat\
│ │ ├── img\
│ │ ├── txt\
│ │ └── reg\
│
├── outputs\ ← 出力ファイル(学習済LoRAなど)
│ ├── 10_cat\
│ └── 15_dog\
│
├── configs\ ← 設定ファイルの保存場所(任意)
│
├── venv\ ← 仮想環境(Anacondaなしで動かす場合)
├── GUI起動用のbatファイルやスクリプト
└── READMEなど
ここまで用意が出来たら、いよいよ実際にトレーニングをしていきましょう。続きはこちらのリンク記事で解説しています。
Kohya_ssの使い方
SAKASA AI
Kohya_ssとは?LoRA学習に特化したGUI版の使い方【完全ガイド2025年最新版】 | SAKASA AI Kohya_ssとは?LoRA学習に特化したGUIツールの概要と使い方を初心者向けに解説。Checkpointモデルの選び方、WD14・BLIP2によるキャプション生成、最小構成での学習フローま…
ローカルでKohya_ssを使用してLoRA学習をする方法
【初心者向け】自作LoRAの作り方|Kohya_ssで学習する方法|Anaconda + CUDA【Windows】 ローカル環境構築から学習までを解説 この記事では、LoRAをKohya_ssで学習する為の環境構築からKohya_ssを開くまでの手順を解説しています。 LoRAモデルの概要、モデル…
RunPodでKohya_ssを使用してLoRA学習する方法
【RunPodの料金と使い方】Stable Diffusionなどで画像生成やLoRA学習をする方法【②実践編】 RunpodでStable Diffusion系画像生成やLoRA学習をする方法 Stable DiffusionやLoRA学習では、長時間GPUをフル稼働させるため、発熱や電源の安定性が大きな課題になりま…