【Kohya_ss×SDXL 】SDXLでLoRAをつくる人が最初に知っておくべきこと

Kohya_ssでLoRA学習をする際に使用するbaseとなるモデルに、SDXLを用いて学習する際の特筆すべき特徴と、
従来の SD1.5/2.1用のLoRAモデルとの違いや注意点についてまとめました。
Stable Diffusion公式モデル(Stability AI公式リリース)は、現時点で以下の種類があります。
目次
【1】Stable Diffusion 1系(SD 1.x)
- Stable Diffusion 1.4
- 最初の一般公開モデル(2022年8月)
- Stable Diffusion 1.5
- より安定した結果を出すための改良版(学習データ追加)
- 512×512画像用に最適化
- 軽量でローカルでも動作しやすい
- 多くのLoRAやCheckpointがこのバージョンに対応
【2】Stable Diffusion 2系(SD 2.x)
- Stable Diffusion 2.0
- 新たなOpenCLIP学習、768×768に対応
- Stable Diffusion 2.1
- 2.0の改良版で、プロンプト精度などが向上
- 2.x系はCLIPエンコーダーがOpenCLIPに変更
- SD1.xとの互換性はほぼ無し
- モデルファイルサイズは大きめ
【3】Stable Diffusion XL(SDXL) ←今回はこれ!
- SDXL Base 1.0
- SDXL Refiner 1.0
- 主に高解像度・高品質用(1024×1024)
- デフォルトで1024pxに対応
- 自然な写真やリアルなイラストに強い
- LoRAやControlNetも進化中
【補足】SDXL用のVAE付きモデル
sd_xl_base_1.0_0.9vae.safetensors
「軽量なVAE(0.9VAE)」を使ったバージョンです。
sd_xl_base_1.0_0.9vae:色味を少し落ち着かせたり、暗部のノイズを減らす調整済みVAE付きモデル。- 色合いが安定しやすくなるため、アニメ系や一部用途で人気です。
本記事では、LoRA学習における【3】Stable Diffusion XL(SDXL)の使用について、
使用環境に関しては、
ローカル環境(自分のPC)で使用する方法と、クラウド環境(レンタルGPU)で使用する方法について書いています。
前半では、それぞれの設定方法について。
後半では、ローカル環境とクラウド環境共通の、SDXLの使用に関する使用方法の特徴と注意点について書いています。
SDXLを使うための前提条件
Hugging Face(StabilityAI公式) … sd_xl_base_1.0.safetensorsを用意する(この後に解説。)--sdxl フラグ … コマンドかGUIでONにする(この後に解説。)
1024pxの学習用画像(この後に解説。)
Kohya_ssが用意してある事。
※まだの場合は、以下のそれぞれの記事にて、Kohya_ssのダウンロード方法について解説しています。
ローカル環境(自分のPC)で使用したい方 ※SDXLを使用する場合は、16GB以上のVRAMが必要です。
あわせて読みたい
【初心者向け】自作LoRAの作り方|Kohya_ssで学習する方法|Anaconda + CUDA【Windows】 ローカル環境構築から学習までを解説 この記事では、LoRAをKohya_ssで学習する為の環境構築からKohya_ssを開くまでの手順を解説しています。 LoRAモデルの概要、モデル…
クラウド環境(レンタルGPU)で使用したい方
あわせて読みたい
【RunPodの料金と使い方】Stable Diffusionなどで画像生成やLoRA学習をする方法【②実践編】 RunpodでStable Diffusion系画像生成やLoRA学習をする方法 Stable DiffusionやLoRA学習では、長時間GPUをフル稼働させるため、発熱や電源の安定性が大きな課題になりま…
LoRAについて
あわせて読みたい
LoRAとは?仕組み・学習・使い方・学習パラメータまで【LoRA完全ガイド】 LoRAとは何か? LoRAとは、Low-Rank Adaptation(低ランク適応)の略で、大規模なモデル(例:Stable Diffusion)の重みをすべて再学習するのではなく、一部だけを効率…
SDXL対応LoRAテンプレートとSD1.5/2.1用のLoRAテンプレートとの主な違い
SDXL対応LoRAテンプレートは、従来の SD1.5/2.1用のLoRAテンプレートとはいくつかの点で明確に違いがあります。
「SDXL対応LoRAテンプレート」と「SD1.5/2.1用LoRAテンプレート」の違い
| 比較項目 | SDXL対応LoRAテンプレート | SD1.5/2.1用LoRAテンプレート |
|---|---|---|
| 対応モデル | Stable Diffusion XL(1.0 or 1.0-refiner) | Stable Diffusion 1.5、2.1 |
| 必須ファイル構成 | base + refiner の両方に対応させるなら2つ学習 or 統合的に設計された構成が必要 | 単一モデル(1.5や2.1)用で軽量・シンプル |
| モデル構造 | より複雑(2段階処理、解像度向上、パイプライン構成) | シンプルなUNet構造 |
| 学習データ | より高解像度が必要(768px~) | 512pxが基本(~640px程度) |
| スクリプトや設定の違い | network_args に conv_alpha や block_dim を追加設定する場合あり | 基本的な rank, alpha, dim のみ |
| 学習時間・VRAM負荷 | 非常に重い(16GB以上推奨) | 軽量(8GBでも可能) |
| Kohya_ss対応 | 最新バージョンでの対応必須(v25.1以降) | v21以降で安定使用可 |
Kohya_ss で SDXLのLoRA学習を行う場合、使用すべきベースモデルは以下の ひとつのみ です。
sd_xl_base_1.0.safetensorsこのモデルが 唯一の正式な学習対象 です。
SDXLには以下の2つのモデルが存在します。
| モデル名 | 用途 | Kohyaでの学習対象? |
|---|---|---|
sd_xl_base_1.0.safetensors | ベース画像を生成 | 学習に使用可能 |
sd_xl-refiner_1.0.safetensors | 細部の高精細化(refinement) | KohyaでのLoRA学習には使用不可 |
Refinerの使用方法
sdxl-refiner_1.0.safetensorsは、生成した画像に「あとから適用」してディテール強化を行うものです- LoRA学習には不向きで、そもそも構造が異なるためKohyaではトレーニング対象としてサポートされていません
他のSDXL派生モデル(例)
以下のようなモデルも存在しますが、LoRA学習のベースとして使うには注意が必要です
| モデル名 | 説明 | LoRA学習で使える? |
|---|---|---|
Juggernaut XL, RealVisXL, DreamShaper XL | SDXLベースの派生モデル | ⚠ 一部非推奨(改変済モデルで結果が不安定に) |
sdxl-turbo | 超高速推論用(tiny) | ❌ 非対応(LoRA不可) |
sdxl-lightning | 高速生成用(UNet圧縮) | ❌ 非対応(構造変更あり) |
SDXLモデルの使用方法
今回は、以下の2通りの方法について書きます。
① Hugging Faceから公式のSDXL baseを取得してローカルで配置して使用する方法
② SDXLが同梱されたRunPodテンプレートを使用する方法
① Hugging Faceから公式のSDXL baseを取得してローカルで配置して使用する方法
※Kohya_ss(GitHubから取得するGUI版やCLI版)をダウンロードしても、SDXL本体(sdxl-base-1.0.safetensorsなど)は付属していません。
SDXLモデルは StabilityAIのライセンスに基づいて Hugging Face で配布されています。
SDXLモデルをローカル環境で使いたい場合は、自分でダウンロードして配置する必要があります。
Hugging Face(StabilityAI公式)
ファイルとヴァージョン➡ sd_xl_base_1.0.safetensors(セーフテンソル)
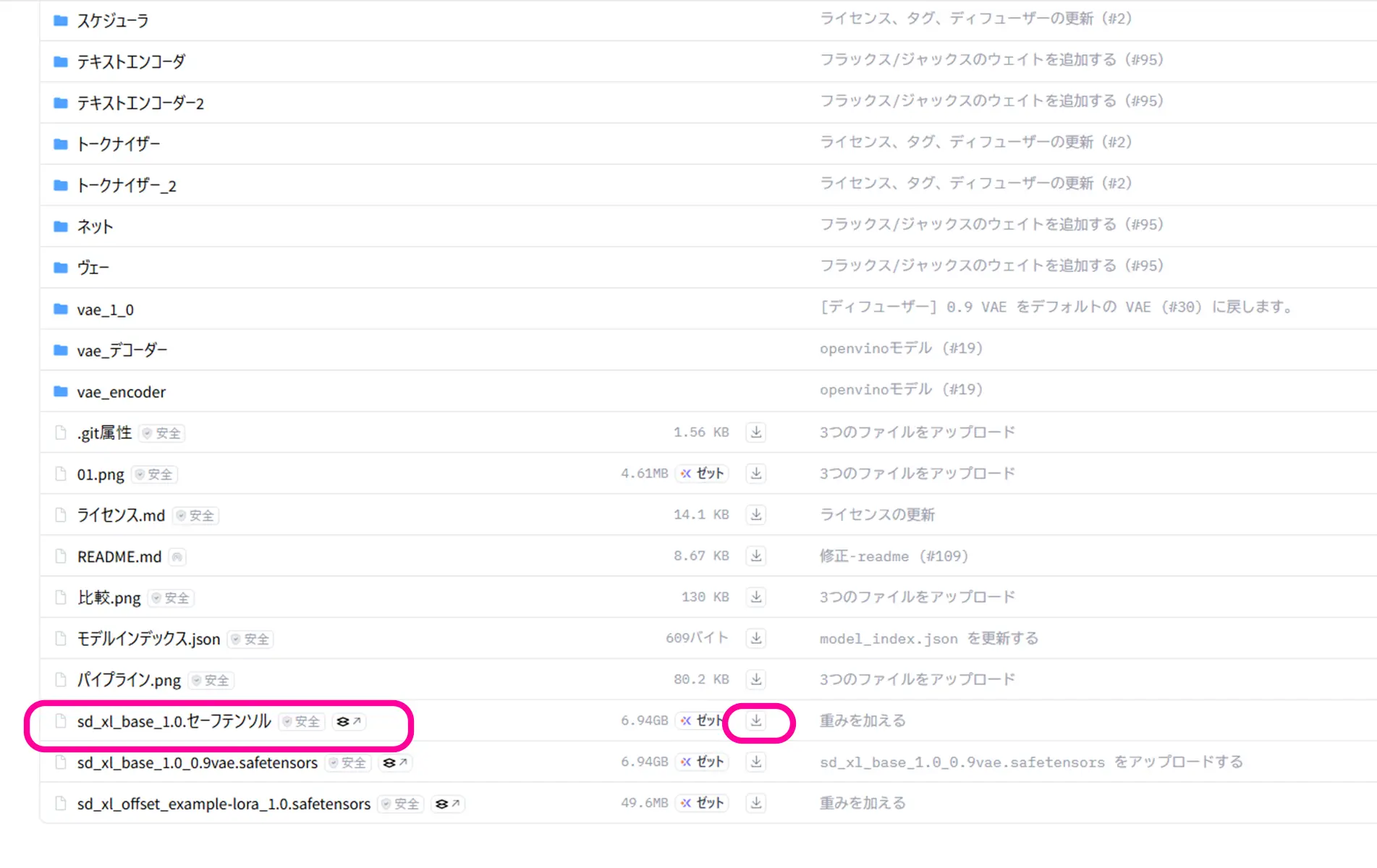
保存するファイル
sd_xl_base_1.0.safetensors… SDXL 1.0(標準)
※ sd_xl_base_1.0_0.9vae.safetensorsについて。sd_xl_base_1.0_0.9vae.safetensors...0.9バージョンのVAEが統合済み。画像の色味やコントラストにやや違いが出ることがある。
VAE(Variational Autoencoder)は、画像の色合いや滑らかさ、ディティール表現に関わる補助モデルです。
特にLoRA学習や生成結果に影響を与えるため、
「0.9のVAE」と「1.0のVAE」では、画像の発色や質感が微妙に異なります。
標準的な環境・安定性を重視: →sd_xl_base_1.0.safetensors(+別途VAE指定)
手軽にVAE統合済みを使いたい: →sd_xl_base_1.0_0.9vae.safetensors
※Kohya_ssでのLoRA学習には、明示的にVAEを別指定できるので、通常版(VAE無し)を使い、--vaeで指定する方式が無難です。
その他の補助ファイル
- Refinerモデル(必要であれば)
sdxl-refiner-1.0.safetensors
配置先例
Kohya_ss/models/に配置。
Kohya_ss/models/sd_xl_base_1.0.safetensors② SDXLが同梱されたRunPodテンプレートを使用する方法
使用すると思いの外、快適なのがRunpodです。
予め用意されたテンプレートの中から、使用したい機能がパッケージされたテンプレートを選ぶだけなので、インストールの手間が無く、自分のPCの容量も圧迫しません。
又、高性能のGPUを選ぶ事が出来るので(例:B200(180GB)←さすがにこれは必要ないけど・・・RTX6000Ada(48GB)や、RTX5090(32GB)なども好きな時間だけ使用可)
重いモデルなどを追加していっても作業がスムーズに進みます。
”Kohya_ss Training Studio”
ワンクリックアップローダーでSDXLモデルの自動リンク機能で自動モデル配置!
拡張機能のWD14まで自動配置される”Runpodのワンクリックテンプレート”について、こちらの記事で書いています。
SAKASA AI
【RunPod×Kohya_ssテンプレート】LoRA学習とWD14・BLIP2キャプション生成解説|最新版 | SAKASA AI キャプション生成からLoRA学習まで1Podで完結させる 本記事では、クラウドGPUのRunPod内で、 WD14”と、モデルダウンローダーが組み込まれた”Kohya_ss”のテンプレートを使用…
※モデルダウンロード、モデル配置、WD14のダウンロードと配置とタグ付けがワンクリックで出来るRunpodテンプレートです。特に初心者の方におすすめです。
注意点
- モデルが**どのバージョンか(base/refiner)**確認する。
- SDXL LoRA学習にはrefinerは不要、baseのみでOK
- 一部テンプレートでは、最初の起動後に自動でDLされるため、初回起動に時間がかかることがある
よくあるトラブルと対処法
エラー1:AssertionError: clip_l.token_embedding...
→ SDXL用でないベースモデル(v1.5など)を使っている場合。
対処: 正しいSDXLベース(sd_xl_base_1.0.safetensors)を指定。
エラー2:高VRAM問題(16GB未満でOOM)
→ SDXLはVRAMを多く消費します。学習中にOut of Memoryになることも。
軽量化の工夫:
- 解像度を
512x512などに下げる batch sizeを1にするnetwork_dimを16や32に下げるgradient_checkpointingをONにするcache_latents = Trueを試す(負荷軽減)
エラー3:lossが極端に高い・下がらない
→ キャラがブレる、学習されない
対処: キャプションミス、画像サイズバラバラ、枚数不足などを見直します。
SDXL用LoRAテンプレートを使用する際の技術的な主な違い
1. --sdxl オプションの追加
SDXLモデルを対象にする場合、以下のオプションを必ず付けます。
sdxl --network_module=networks.loraこれにより、内部で
- SDXL用のCLIP(OpenCLIP-G)
- T5 tokenizer
- 1024px画像サイズのサポート
などが有効になります。
2. モデル指定が異なる
SD1.5では、以下のように指定することが多いです。
--pretrained_model_name_or_path="models/v1-5-pruned.safetensors"SDXLでは。
--pretrained_model_name_or_path="models/sd_xl_base_1.0.safetensors"また、Refinerを使いたい場合は refiner モデルも別途準備します。
3. 推奨解像度が1024px固定
SDXLでは、1024×1024が標準の解像度です。
学習画像が 768px や 512px のままだと、モデル特性を十分に活かせません。
--resolution=1024が強く推奨されます。
4. CLIPの代わりに**T5キャプションを使う構成もある
- SDXLではT5テキストエンコーダが使われているため、**自然文キャプションの方がより自然に学習される傾向がある。
- ただし、従来の「タグ式キャプション」でも動作します。
T5形式キャプション(**自然文キャプション)
➤ T5とは?
「T5(Text-To-Text Transfer Transformer)」は、Googleが開発した自然言語処理モデルで、
人間が書いた自然文に近い文を理解するのが得意なエンコーダーです。
Stable Diffusion XL(SDXL)では、画像に対するテキスト入力の処理に
従来の CLIP(タグや単語)ではなく、T5ベースのテキストエンコーダを利用しています。
CLIPとの比較
| 項目 | CLIP形式 | T5形式 |
|---|---|---|
| 書き方 | girl, long hair, blue eyes のようなタグ羅列 | A girl with long hair and blue eyes, smiling in a sunny park. のような自然文 |
| 区切り | カンマ(,) | 文法通りの英語文章 |
| ターゲット | SD 1.5 / 2.1 | SDXL(T5エンコーダを搭載) |
| 柔軟性 | タグの組み合わせに強い | 文脈理解・表現力に強い |
SDXLは以下のような自然文に対して、構造やニュアンスをしっかりと学習に反映できます。
例:
A close-up portrait of a young woman with silver hair and glowing golden eyes, wearing a futuristic headset.同じ内容をCLIP形式にすると
young woman, silver hair, glowing golden eyes, portrait, futuristic headset→※ 両方使えますが、T5形式の方が意味を深く理解して、学習にも効果的とされています。
キャプションをT5形式に変換する方法
方法①:自分で英文を自然に書く(英語学習がてら◎)
- 英語が得意なら手書きでもOK
方法②:自動で変換するツールを使う
- **BLIP2(キャプション生成AI)**などを使えば、日本語画像からでも自然文を生成可能
- Kohya GUIにも「BLIP2自動キャプション生成機能」が統合されているテンプレがあります
T5形式のキャプション作成例
夕方の居心地の良いカフェの雰囲気の中で、コーヒーカップを持った、ピンクのツインテールの元気なアニメの女の子のイラスト。
An illustration of a cheerful anime girl with pink twin tails, holding a cup of coffee, in a cozy cafe setting during the evening.キーワード:
- 誰(誰の絵なのか)
- 何をしているか
- どこで、どんな雰囲気か
- 髪や目など、視覚的特徴
※CLIPタグも 使えます。が、T5形式の方が精度が出やすい。・・・Kohya_ss では、キャプションがタグでも文章でも動作します。
ただし、**T5を前提としたモデル(SDXL)は、自然文の方がその設計に合っている様に思います。
| 特徴 | T5形式キャプション |
|---|---|
| 書き方 | 英文の自然文(例:”A woman standing in the rain with a red umbrella.”) |
| SDXLでの推奨度 | 高(CLIPよりも意味の理解が深い) |
| 作成方法 | 手書き / BLIP2 / 自動変換ツール |
| Kohya GUIでの使い方 | caption_text にT5形式文を記載するだけでOK |
kohya_ssのキャプション機能
Kohya_ssは複数のキャプション方式を使用できますが、中でも定番なのが、
- WD14 tagger(タグ生成)
- BLIP / BLIP2(文章キャプション)
です。
| 用途 | 使うもの |
|---|---|
| タグ学習(danbooru系) | WD14 |
| 自然文キャプション | BLIP2 |
kohya_ss で標準搭載(内蔵機能)BLIP2 を使用する場合
キャプションタグ機能の具体的な使用方法に関して、詳しくはこちらの記事で解説しています。
SAKASA AI
【最新版】LoRA学習用画像に自動キャプション(タグ)付けする方法|kohya_ssのWD14 TaggerとBLIP2 | SAKAS… kohya_ssのCaptioning機能まとめとWD14 TaggerとBLIP2の違いと使い分け これまで、 画像タグ生成のために外部ツールとして個別で使用されることが一般的だった WD14 tagger…
BLIP2 が「あるのに効かない」場合
① WD14とBLIP2は別物
WD14とBLIP2は別物ですので、WD14を使っているときは BLIP2は一切使われません
② BLIP2は「Captioning」を選ばないと動かない
GUIの場合には、
- 「Captioning」系ツールを選択
- BLIP2 を明示的に指定
指定しない限り WD14やBLIPになる様です。
③ 環境によっては自動で BLIP にフォールバック
BLIP2は重いので、
- VRAM不足
- 依存関係が揃っていない
などの理由で、
- 表示は BLIP2
- 中身は BLIP(旧)
になることがあるようです。
BLIP2を使うか?WD14Taggerを使うか・・・
向いている
- 自然文キャプション(diffusers系)
- SDXL DreamBooth
- 写真寄りデータ
- 背景・状況説明重視
向いていない
- キャラLoRA(danbooruタグ)
- アニメ絵
- WD14前提の学習
 未来
未来キャラLoRAでは WD14が圧倒的に人気ですよ!