【RunPodの料金と使い方】Stable Diffusionなどで画像生成やLoRA学習をする方法【②実践編】

RunpodでStable Diffusion系画像生成やLoRA学習をする方法
Stable DiffusionやLoRA学習では、長時間GPUをフル稼働させるため、発熱や電源の安定性が大きな課題になります。
そこで便利なのが RunPod のようなGPUのクラウドサービスです。
ハイスペックGPUを冷却や電源を気にせず、必要な時間だけ利用可能で、初期投資と環境構築の手間が無く、自身のPCをモデルファイルに圧迫されない点が魅力です。
※本記事では、 RunPodの料金システムの仕組みとアカウント開設から、Web UI(例:AUTOMATIC1111やKohyaなど)で、
画像生成やLoRA学習をする為の設定方法について、解説しています。

右は、Runpodの
Public Endpoints内のWan 2.2 I2V 720pで
左の画像を使用してワンクリック生成した8秒動画。
この、画像からの動画生成では、プロンプトのみを指定した。
生成時間は4分20秒
RunPod公式サイト |お友達紹介特典付きリンク
こちらのリンクからサインアップすると、 5~500ドルの1回限りのクレジットが付与され、初回入金時に10ドルが追加されます。
こちらのリンクからサインアップすると、 5~500ドルの1回限りのクレジットが付与され、初回入金時に10ドルが追加されます。
Runpod
AI and Cloud Infrastructure Provider | Runpod AI infrastructure with on-demand GPUs and serverless compute. Run training, inference, and batch workloads on the cloud with Runpod.
目次
RunPodの使い方
使用方法はいくつかありますが、最初は以下の二通りの方法がおすすめです。
- PublicEndpointを使用して生成をおこなう方法
画面左側のPublicEndpointタブ➡ツール選択➡APIエンドポイント(外部アプリやコード)で即時生成可能です。 - Pod Templateを使用して生成をおこなう方法
画面左側のPod Templateタブ➡ツール選択➡Deploy➡Podを起動- RunPodでは、アカウントを作成し、ログインしただけではPod(仮想マシン)は作成されません。
以下の方法でPodを作成・起動する必要があります。
- RunPodでは、アカウントを作成し、ログインしただけではPod(仮想マシン)は作成されません。
Pod起動の流れ
 未来
未来Pod Templateを使用する場合の流れはこんな感じです!
STEP
ネットワークストレージを作成
使用したいテンプレートで、どのGPUが使えるか確認してボリュームを作成
※ネットワークストレージは、RunPod上で使える「自分専用のクラウド保存スペース」です。
パソコンでいうところの「ハードディスク」や「フォルダ」のようなもので、
ここにファイルやモデルを保存しておくと、RunPodを停止してもデータは消えません。
次回の作業時も、前回の続きからすぐに始められます。
STEP
テンプレートから「Kohya」「 LoRA」「Stable Diffusion UI」「Comfy」など、使用したいテンプレートを検索して選択する。
(任意のテンプレートをクリックすると、詳細:Readmeページが表示されます。)
STEP
Deploy
Deployボタンをクリック
STEP
Podの構成を選択
- Network Volumeを使用する場合は、Deploy a pods内の
Network Volumeでボリュームを選択 - 必要であれば、追加フィルターでGPUを機能で絞って検索
- GPUを選択
STEP
Deploy on Demand
「Deploy on Demand」(オンデマンドで展開)をクリックしてPodsを起動
Podを起動した後できること
- クラウドと同期が出来る様になる。
- 各ツール(ComfyUIやA1111など)のPortの起動
.safetensorsファイルなどを、/modelsなど任意のフォルダにアップロード(画像、.txt、モデルファイルなど)出来る。- 学習や画像生成の際に、アップロードしたモデルを指定出来るようになる。
RunPodのアカウント設定項目の詳細解説
公式ホームページは、Get startedから、Googleアカウントなどでログインします。
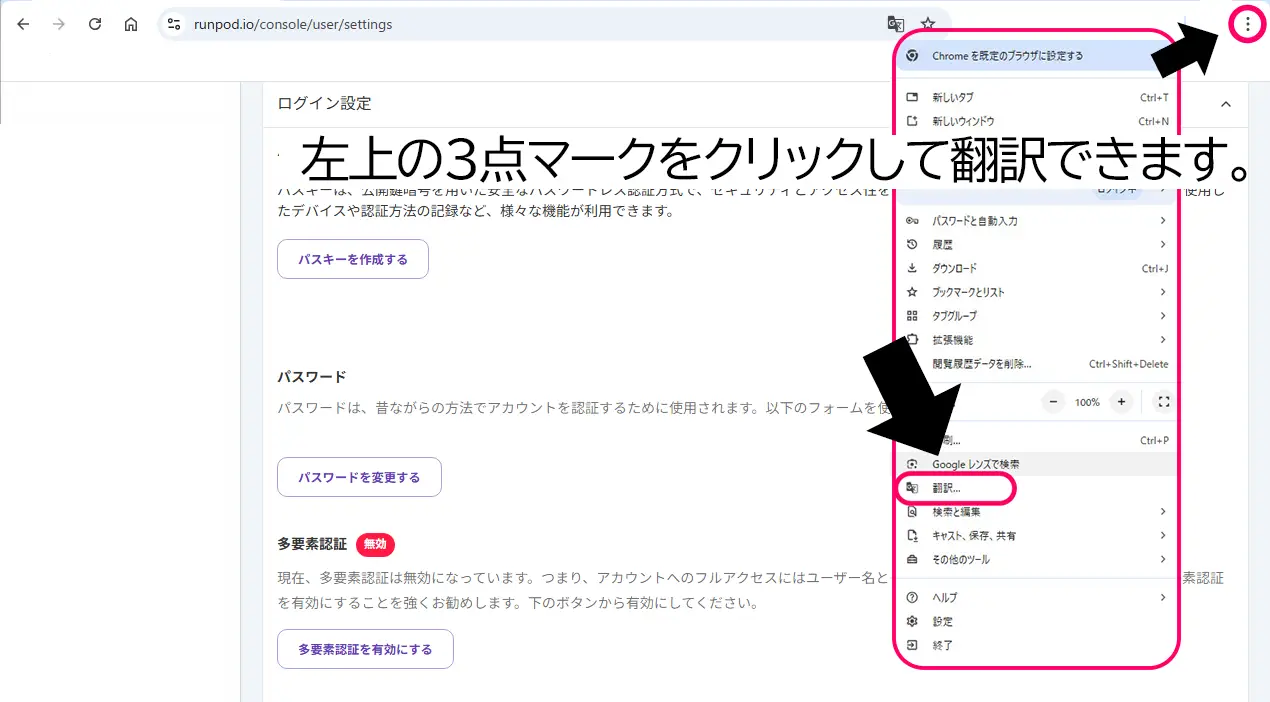
画像右上の三点マークをクリックして翻訳出来ます。(ただし、翻訳しない方が使いやすいです💦)
RunPodのアカウントを作成した直後は、すぐにPodを立ち上げることも可能ですが、以下の項目は最初に設定しておくのがおすすめです。
| 項目 | 説明 | 必要度 |
|---|---|---|
| 支払い方法の登録 | クレジットカードを登録しないと、基本的にPodを起動できません。 | ★★★★(必須) |
| ネットワークストレージ(Volume)の作成 | 画像やモデル、学習データなどを保存するためのストレージ。途中から追加も可能ですが、最初に作っておくと自分のPCに様に使用できるので便利です。(Pod作成時に選択できます。) | ★★★☆ |
| SSH Keyの登録(必要な人のみ) | コマンドラインで直接接続する人向け。※ Web UIしか使わない場合は不要。 | ★☆☆☆(オプション) |
| rcloneで連携したいクラウドの準備 | Google Driveなどと連携したい場合は、rclone設定の前にDrive側の準備が必要です。 | ★★☆(便利) |
「とりあえず使ってみたい」「AUTOMATIC1111をWebで操作したいだけ」という方は、最低限のクレカ登録だけでPodを起動して使い始めることが出来ます。
Settings(設定)アカウント情報
基本的に、RunPodの登録情報(First Name, Emailなど)は英語(アルファベット)入力推奨のようです。
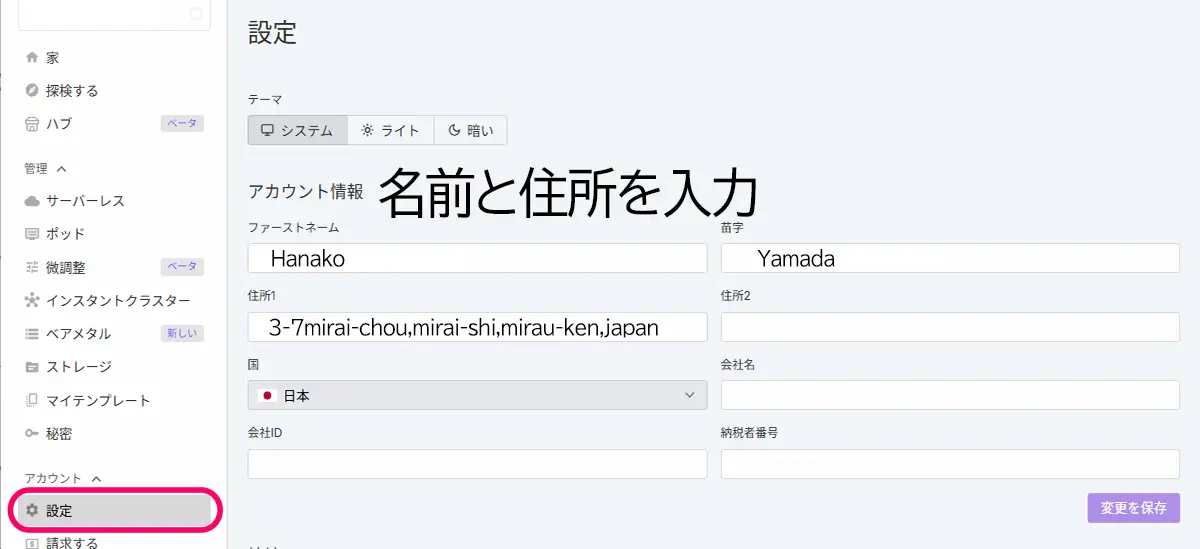
※請求書やサポート時の確認などにも英語表記が使われるため、統一しておいた方が安心かと思います。
【その他の設定】
パスワード アカウント作成時に登録。
メールアドレス認証 アカウント有効化のために必要(Googleでログインした場合は自動で追加されている)。
APIキー 任意(特定用途のみ)自動スクリプトや外部ツールからRunPodを操作したい合に必要。通常の手動利用では不要。
パスキー 任意 高度なセキュリティを求める場合。現時点では使わなくてもOK。
多要素認証(MFA) 推奨(任意)セキュリティ強化におすすめ。後から設定可能。
※(APIキー・MFA・Passkeyなど)は、後から必要に応じて設定可能です。とくにLoRA作成や画像生成など「手動でPodを立ち上げて作業する」場合は、APIキーは不要です。
【APIキーが必要になるケース】
PythonスクリプトなどでRunPod APIを使ってPodを自動で操作したい
Hugging Faceや自作ツールと連携して使いたい
外部サービスとRunPodを連携する開発をしている
Billing(請求する)設定
RunPodの「支払い方法」について、クラウドGPUサービスだと「使っていないのに月額費がかかる」パターンも多い中で、
RunPodは「使った時間分だけ」課金され、しかもチャージ制で管理できるのが大きな魅力です。
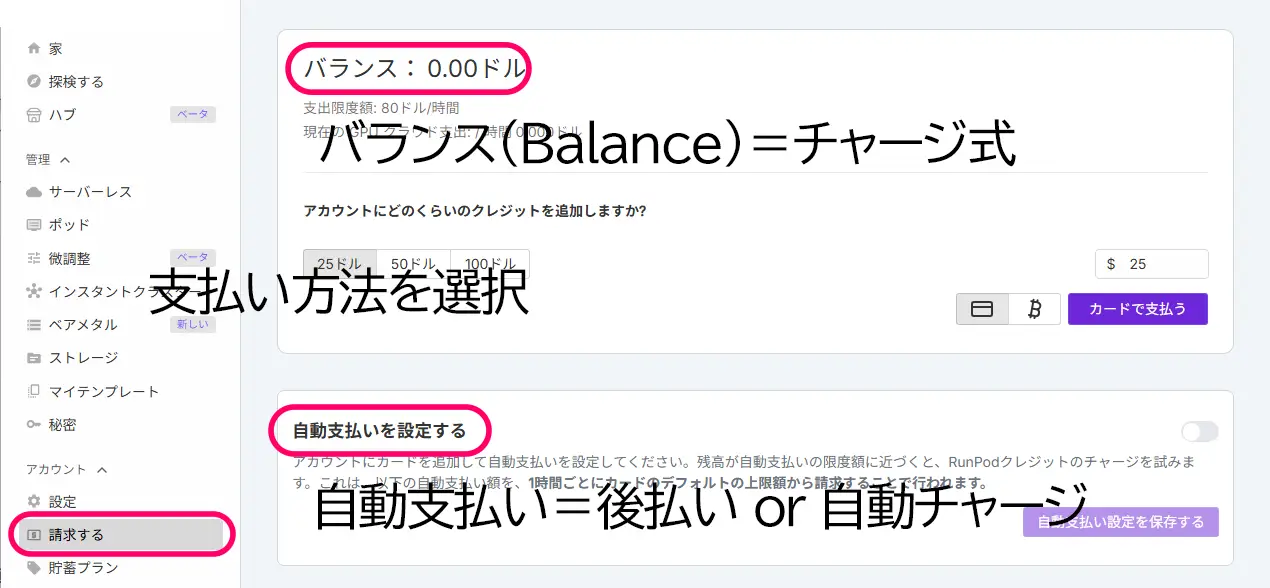
バランス(Balance)=チャージ式
これは前払い制です。
- クレジットカードなどで、一定の金額(たとえば$10や$20など)をチャージ(前払い)します。
- その残高から、Podを動かした時間に応じて使った分だけ引かれていく仕組みです。
- 残高がなくなるとPodが停止します(=課金されません)

自動支払い(Configure Auto-Pay)=後払い or 自動チャージ
これは「残高が一定額を下回ったら、自動でチャージする」設定です。
- たとえば、「残高が$2を切ったら、自動で$10をチャージ」といった設定ができます。
- 実質的にはクレカの自動引き落とし機能と似た仕組みになります
支払いが完了すると、残高が反映され、支払い方法が反映されます。
支払い設定が追加されると、永続ストレージを追加できるようになります。
RunPodの「操作体系」
RunPodは、AI開発や動画処理など幅広く使える中でも、Stable Diffusionなどの画像生成やLoRAのトレーニングには特に最適化されており、テンプレートやネットワークストレージなど、作業を効率化する機能が豊富に揃っています。
GUI(基本)
ブラウザで操作する直感的な画面。Podの起動、ファイルのアップロード、Web UI(例:AUTOMATIC1111やKohya)での作業が簡単。初心者でも扱いやすい。
CLI / Jupyter Notebook(オプション)
高度な自動化やPythonベースの処理に向いたコマンドライン操作。テンプレートによってはJupyter LabベースのUIもあります。
【①解説編】RunPodの概要についてはこちらの記事をご覧下さい。
クラウドGPU”RunPod”とは?画像生成・LoRA学習の最適解?!個人利用の効率よいクラウド環境【①解説編】 ComfyUI、Stable Diffusionなどの画像生成も使いやすい Stable Diffusionで「思う存分、画像,動画生成がしたい」「自分の作風を学習させたい」「LoRAやDreamBoothを試し…
RunPodの「料金体系」
 未来
未来うっかり高額請求が来たりしないかも心配・・・。
 SAKASA
SAKASARunPodは使った時間分だけ引かれる明朗会計だから安心だよ!
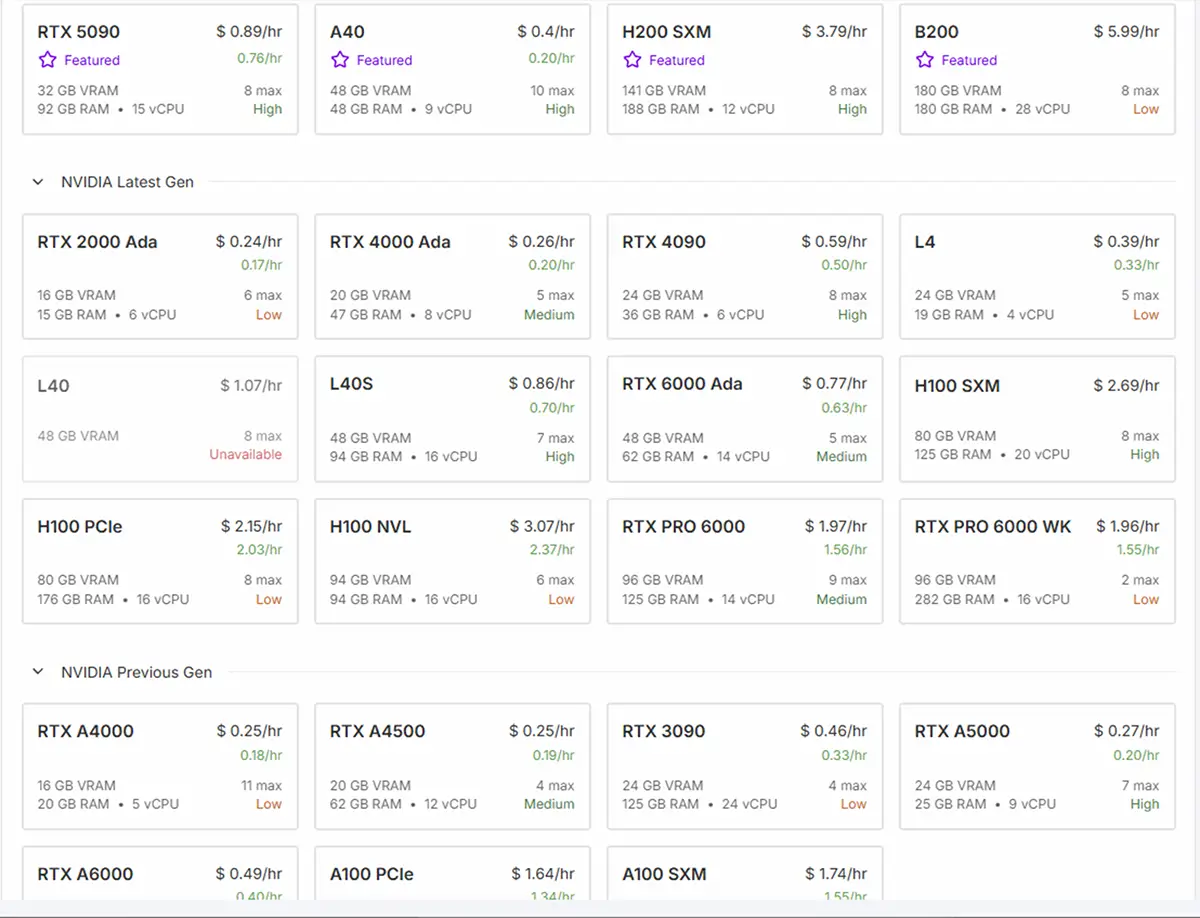
RunPodの料金は、ネットワークストレージのメモリ容量+(選ぶGPU×使用した時間)で決まります。
ネットワークストレージは、画像生成をして、すぐに生成画像をダウンロードするという様な使い方の場合は、使用する必要は無いかも知れません。
ですが、LoRAなどで学習をしたり、自分のファイルをアップロードして、自分のPCの様にして、クラウドGPUを使用したい場合には使用すると便利です。
ネットワークストレージに置いてあるデータはPodを停止しても、Podを削除しない限り消える事はありません。
※ネットワークストレージは、1GBあたり0.07ドル~/月です。
RunPodテンプレートの選択
それでは、早速テンプレートを見てみましょう。
未来使用したいツールは決まっていますか?決まっていない場合は、Stable Diffusion、Automatic1111、ComfyUI、WebUIなどと検索してみてください。
見方としては、WebUIや、UIなどと付くテンプレートには”UI画面”があります。WebUIや、UIなどの記述の無いものは、クリックして内容を確認します。
Pod Templates
Pod Templateを選択➡検索窓で絞り込み➡テンプレートの種類(Official or Communityなど)を選択できるようになりました。
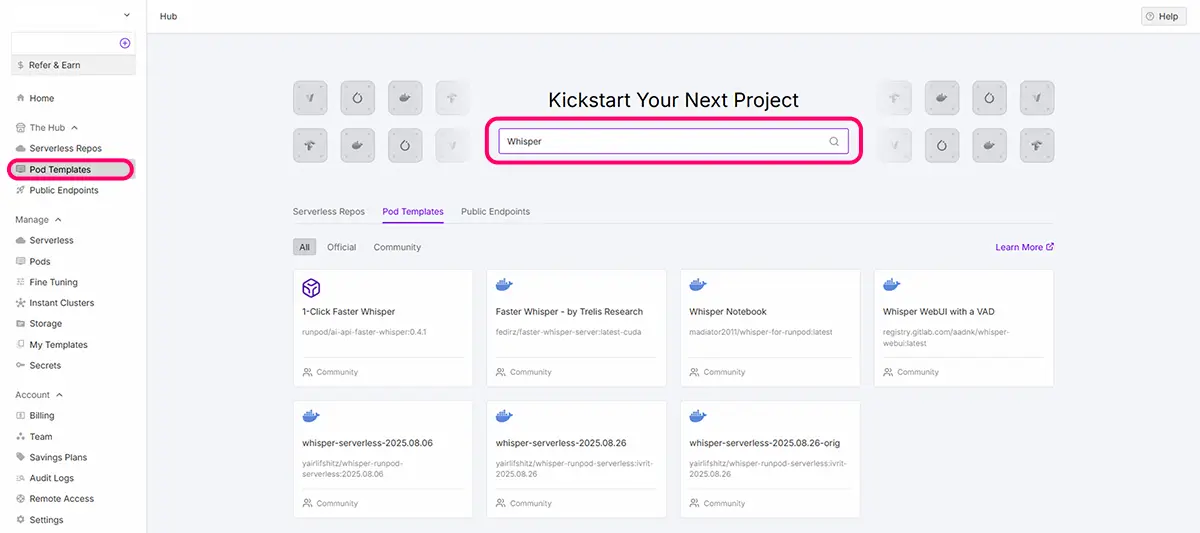
Pod Templatesを使用する場合は、ComfyUI,Automatic1111,LoRA、Kohya,など、目当てのツール名で絞り込み検索し、クリックして説明画面で内容を確認
例:
以下の二つのテンプレートをご覧下さい。
ここでは、CUDAのバージョンを確認しておきます。(一枚目の画像では、一番目の赤線部分。CUDA 12.5)
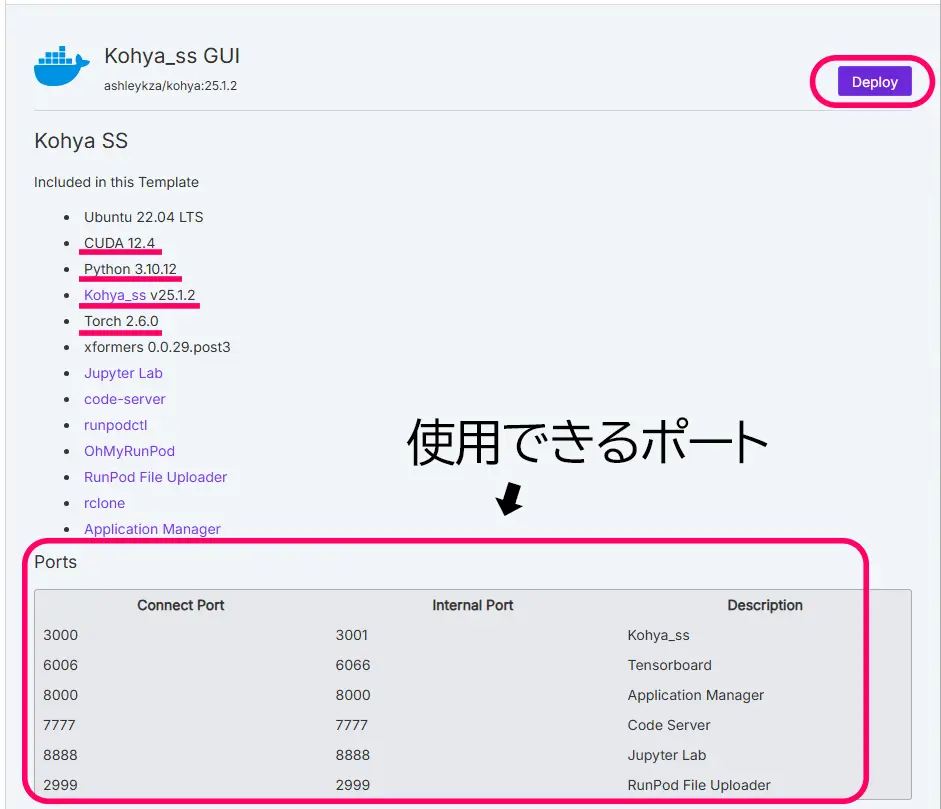
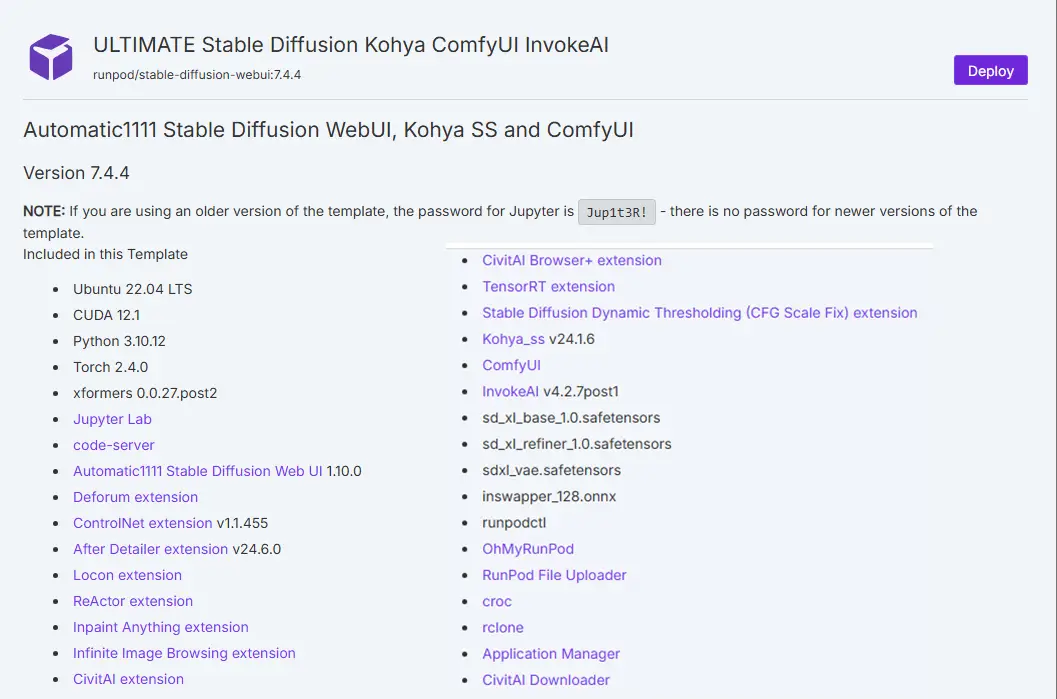
Read me内のDeproyボタンをクリックするとストレージや、GPUを設定する画面の移ります。
CUDAバージョンから使用可能なGPUを選ぶ方法
CUDAのバージョンフィルター機能Additional Filtersを使用出来ますが、
最近のGPU(RTX 4090など)は、CUDA 11.8イメージも12.1イメージも動きます(下位互換)
その為、フィルターは無視して、利用可能なGPUをそのまま使えば良いようです。
STEP
「Additional Filters」ボタンをクリック
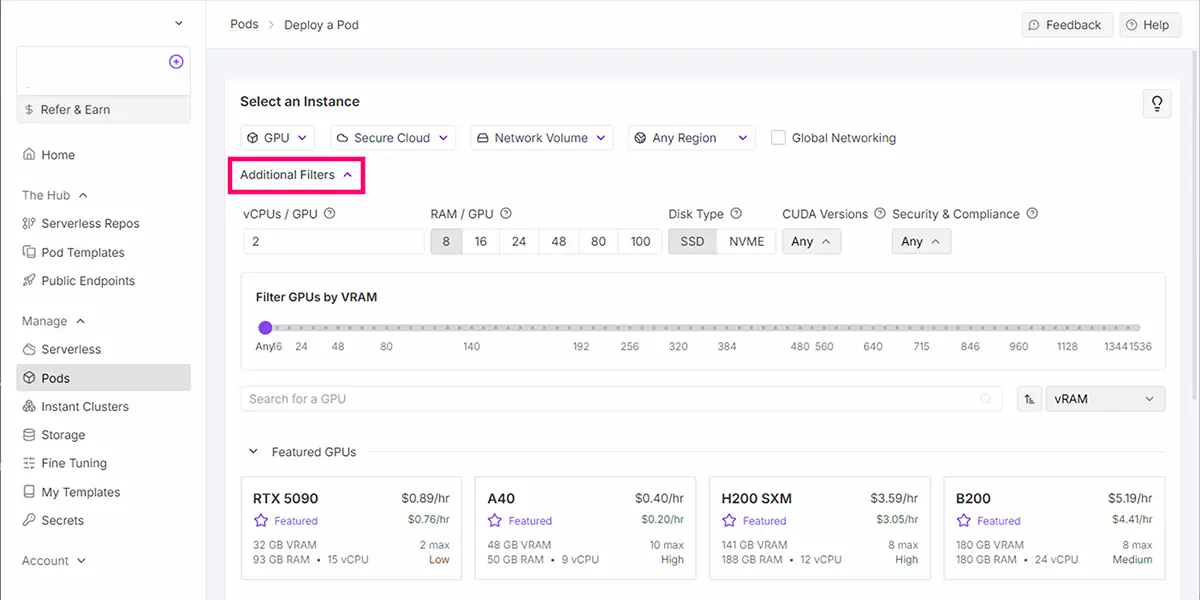
STEP
「CUDA Versions」ドロップダウンを選択
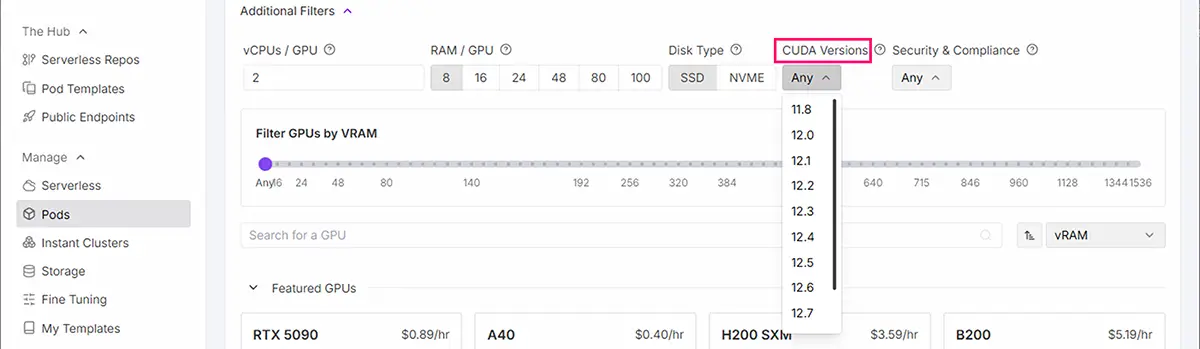
STEP
必要なCUDAバージョンを選択(例: 12.8, 12.4, 11.8など)
先程のテンプレート内に記載にあったバージョン以下すべて(下位互換) を選択します。
(例)12.1の場合なら、12.1,12.2,12.3,12.4…..と以下の全てを選択します。
テンプレート内に記載がない場合は、基本的には新しすぎず古すぎないGPUを選択すれば大体使えます。
STEP
互換性のあるGPUのみが表示される
GPU性能ざっくり比較(Stable Diffusion / AI推論系)
※ 目安と傾向
| GPU | txt2img速度 | LoRA学習 | VRAM | 備考 |
|---|---|---|---|---|
| RTX4090 | ◎ | ◎ | 24GB | まだ強い |
| RTX5090 | ◎ | ◎ | 32GB | 最近人気 |
| RTX6000 | ◎ | ◎ | 48GB | A40より速いが L40S には負ける |
| H100 | ★ | ★ | 80GB | 現役トップクラス |
| H200 | ★★(最速クラス) | ★★ | 141GB | 化け物性能 |
| A40 | △ | △ | 48GB | コスパ良いが古い |
| L40S | ◎++ | ◎++ | 48GB | 4090の倍近い速度 |
- テンプレートに必要なCUDAバージョンと互換性のあるGPUのみ表示
- ドライバー互換性の問題を自動的に解決
ネットワークストレージを使用する場合は、ネットワークストレージ(Network Storage)の設定をします。
ネットワークストレージを使用しない場合はこちら このまま選択したPodを Deploy します。
ネットワークストレージ(Network Storage)の設定
ネットワークストレージは、Podを止めたり再起動する際に、学習データ・モデル・出力画像などを保存しておくための機能です。
ネットワークストレージに保存したデータは、別のPodでも共有可能です。
事前にStragesで「New Nerwork Volume」を作成しておくと、
Pod作成時に「Nerwork Volume」の欄で、ボリューム(ネットワークストレージ)が選べます。
データセンターの選び方
1. 使いたいGPUが使えるリージョン(データセンター)を選ぶ
左側のStorageから、ネットワークストレージ(New Network Volume)をクリックします。
すると以下の画面が出て来ます。
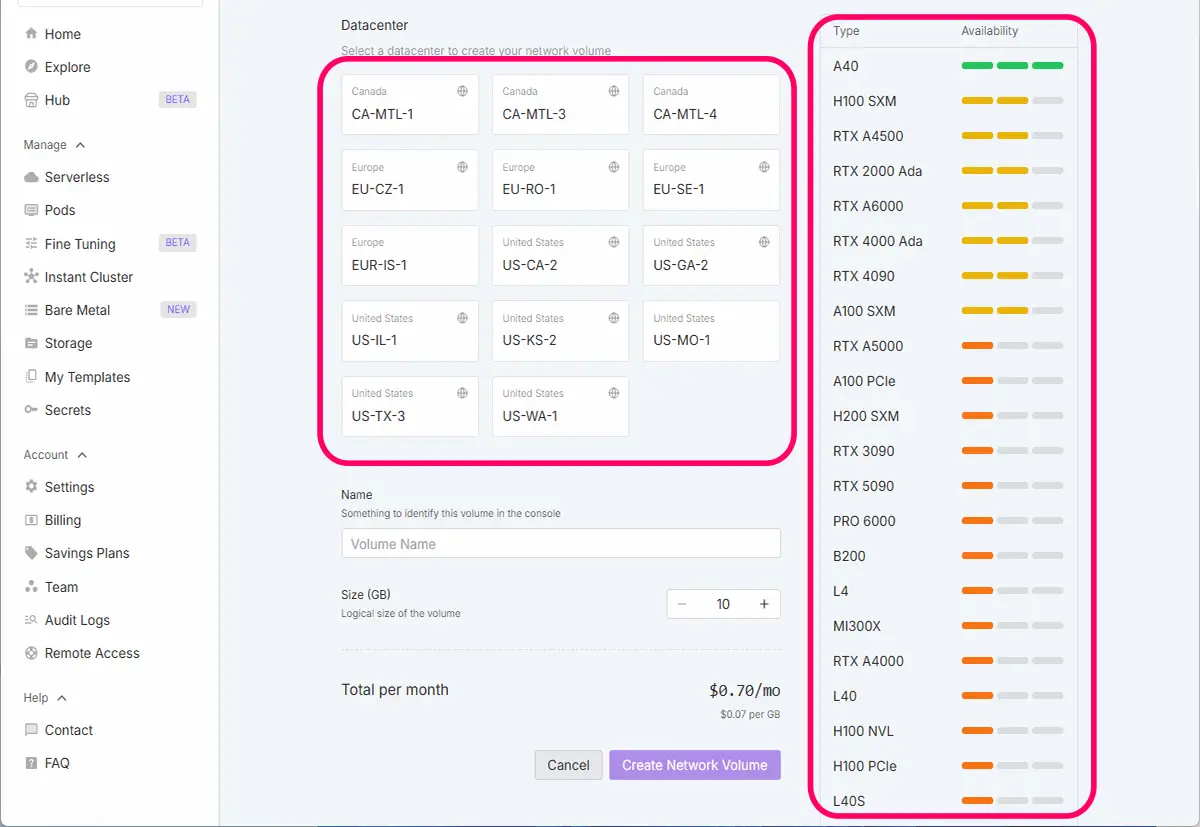
- 一番大事なポイントです。
- 例:RTX 5090を使いたい → そのGPUが使えるデータセンターにボリュームを作成する
- 違うリージョンだとPodに接続できません。
2. 頻繁に起動するGPUが安定して空いているリージョンを選ぶ
- 「混雑していてなかなかGPUが借りられない」となると非効率なので、なるべく空きやすいリージョンを選ぶと◎。
- 時間帯によって混雑が変わるので、ご自身が作業する時間帯に空きがある地域が理想です。
未来NetworkVolumeに気に入ったモデルを全てDLしてある状態でも
使いたい時にリージョンのGPUに空きがないと使えないよ!
SAKASA2つNetworkVolumeを作っておくのも便利だよ。
3. 自身の物理的な居住地に近いリージョン(※必須ではない)
- 通信速度を気にする場合は、ネットワーク経由で学習データや画像をアップロード/ダウンロードする際の速度に影響が出ることがある様ですが、これは学習性能には影響しません(あくまで転送速度のみ)。
ネットワークボリュームを作成するデータセンターを選びます。データセンターを選択すると、使用できるGPU一覧が表示されます。
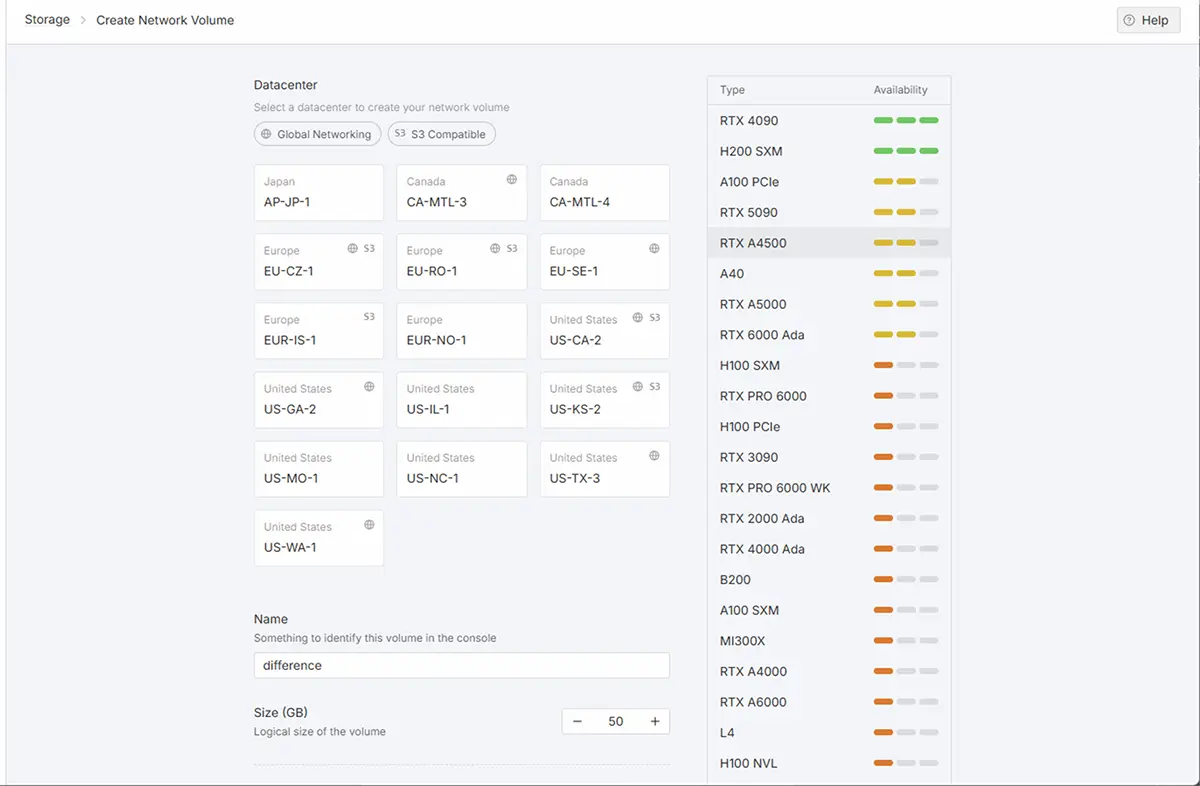
使用したいGPUが使えるリージョンを選択し、Volume Nameを付け、サイズ(GB)を設定し、Create Network Volumeを押すと自分のネットワークストレージが作成されます。
ボリューム(ネットワークストレージ)の設定基準
| 内容 | 容量の目安 |
|---|---|
| 学習画像(100〜200枚) | 100MB〜500MB程度 |
| .txtタグファイル | 数MB未満 |
| モデル本体(SD1.5やLoRA) | 2〜7GB程度(1モデルあたり) |
| 出力されたLoRAファイル | 50MB〜200MB/個 |
| 学習キャッシュ・ログ | 数百MB〜2GB程度 |
設定目安
| 項目 | 推奨 |
|---|---|
| 最低限 | 30GB(削除に注意) |
| おすすめ | 50GB~(複数回学習する) 80GB~重いモデルを多くダウンロードする場合(SDXLもQwenもFluxも使いたい場合は100GBほど欲しい。) |
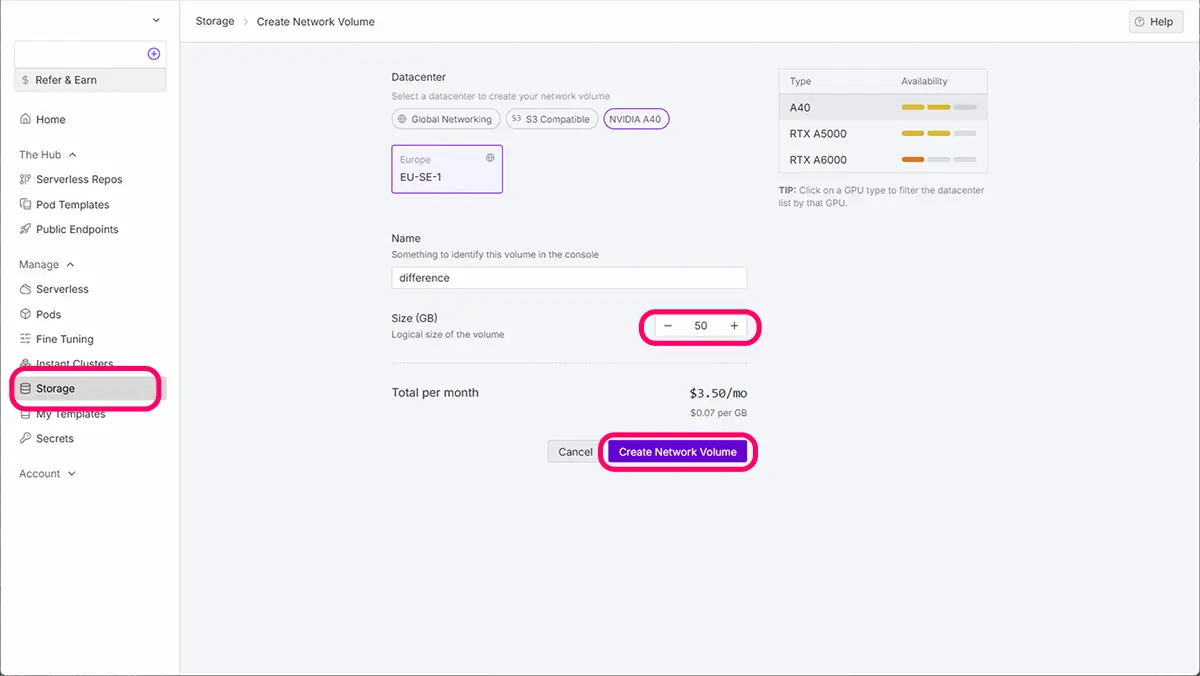
作成したストレージは、ストレージに内に反映されます。
RunPod ネットワークストレージの月額料金目安(日本円換算2025/10記載**為替変動します)
RunPodの「ネットワークストレージ(Network Volume)」は、作成した時点から削除するまで、ずっと課金され続けます。
※課金はPodが停止中でも発生します。
- Podを停止、削除しても、ネットワークストレージが残っていれば料金は発生し続けます
- 料金は GB単位/時間あたり で加算されます(例:$0.0001/GB/時間 など)
| 容量 | 月額料金(USD) | 月額料金(JPY) |
|---|---|---|
| 10GB | $0.70 | 約 ¥103 |
| 20GB | $1.40 | 約 ¥206 |
| 50GB | $3.50 | 約 ¥515 |
ストレージ課金を止めたい場合
「ネットワークストレージ(Network Volume)」自体を削除する
- RunPodの左メニューから「Volumes」を選択
- 削除したいストレージの右側にある「︙」メニューをクリック
- 「Delete」を選択
| 状況 | おすすめ対策 |
|---|---|
| 一時的に使わない | PodだけStop(停止)、Delete(削除)はしない。 |
| しばらく使う予定がない | 必要なデータをバックアップし、Delete(削除)Volume削除 |
| コストを最小限にしたい | 作業の都度Delete(削除)、Volumeを作成・削除 |
RunPod上のGPU切り替えは「Podを再作成」が前提
現在のRunPodでは、稼働中のPodのGPUタイプを後から変更することはできません。そのため、
- Podを一度停止して削除
- 新しいPodを別のGPUで作成
- 永続ストレージで環境を引き継ぐ
という流れになります。
Podの起動
Pod Templateの選択画面から使用するテンプレートを選んで Deploy pod
ネットワークボリューム(永続ボリューム)の設定を確認 ネットワークストレージを使用する場合
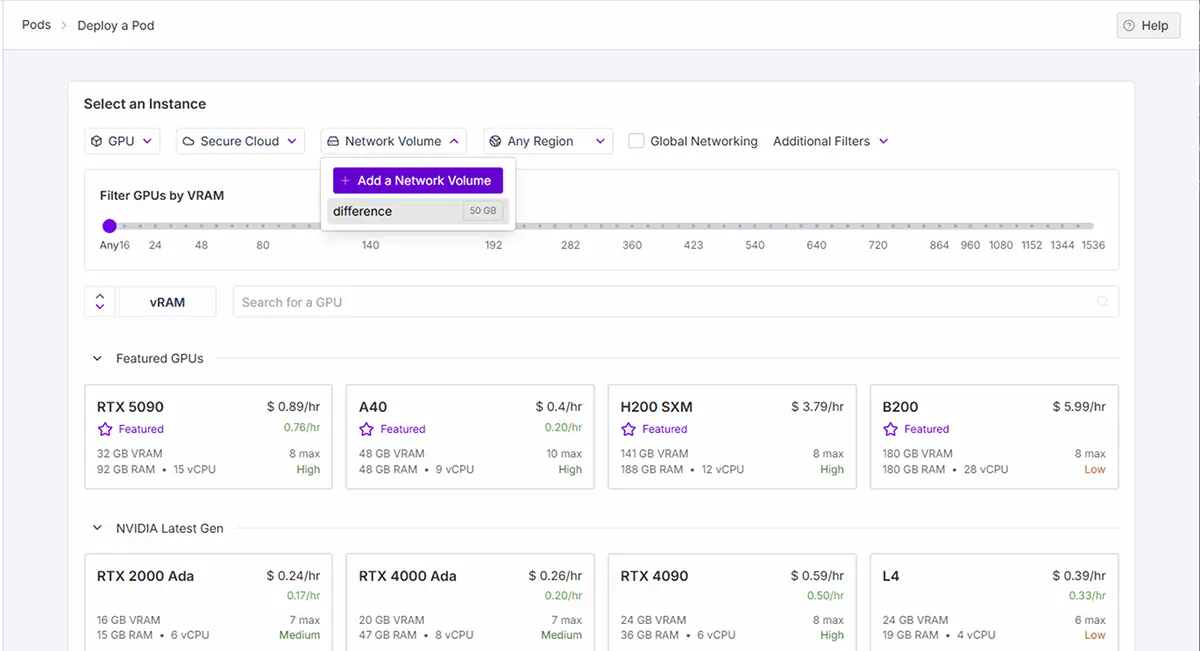
ネットワークストレージを使用する場合は、作成しておいたネットワークストレージで設定したGPUを選択。
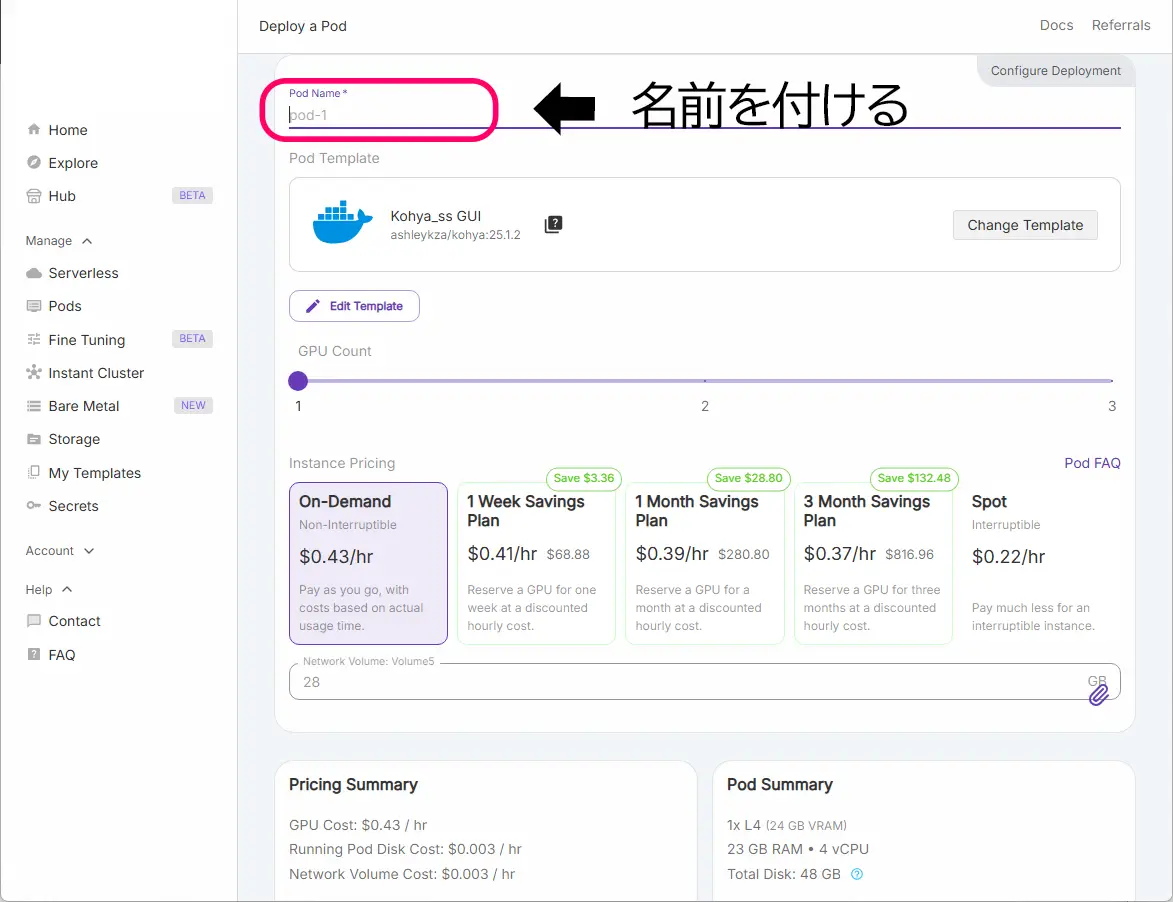
Podに名前を付けて(任意)、Podを起動する。
Running状態になるまで待ちます。
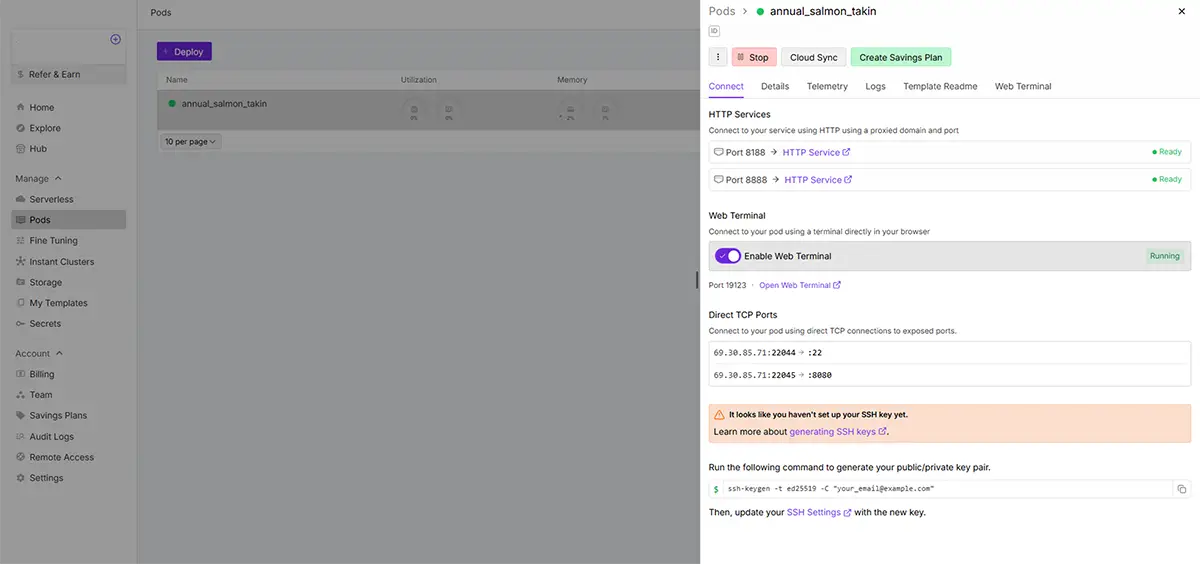
Running状態になると、Connect(接続する)が開けます。
Connect内は、ポート番号で記載されています。ツールは各ポートに紐づけられています。
※紐づけられたポートはテンプレート毎で異なります。詳細は、各Explore(テンプレート内)に記載があります。
Pod内の詳細な使用方法は、こちらの記事をご覧ください。
SAKASA AI
RunPodの【Podの見方と使い方】と【接続オプションの使い方】【⓪基礎・1.Pod編】 | SAKASA AI レンタルサーバーRunPodの”Podの見方と使用方法、そしてPod内の接続オプションの見方と使用方法”とコツそして、エラー対処方法なども加え、困ったときにいつでも見返せるよ…
画像・動画生成をする方法
Runpodで 画像・動画生成をする方法
- Web UI(AUTOMATIC1111、Comfyなど)を開く
- 使用したいモデル(checkpoints、ControlNet、VAEl、LoRA)があればアップロードする
- 所定のフォルダに配置
- 「Stable Diffusion」タブからベースモデルを選択
- あとはPromptを入力して画像生成!
未来お疲れさまでした!
Runpod記事の総合リンクページ
Runpodお役立ちリンクページ
【RunPodリンクページ】活用マニュアル|使用方法から注目テンプレートまで 【2025年最新版】RunPodガイド・Stable Diffusionから”今注目のテンプレート”まで 本ページでは、RunPodの使い方や料金、具体的な活用方法などに関する記事のリンクをま…
今の一押し!RunpodでFooocus×SDXLを簡単に使う方法をこちらでご紹介しています
あわせて読みたい
Fooocus 2.5.3(Stable Diffusion)完全ガイド|ComfyUI・Automatic1111比較|SDXL・RunDiffusion対応【… Fooocusの使い方 「Fooocus(フーカス)」は Webサービス ではなく、ローカルで動かす画像生成ツール です。今回の最新版2.5.3 では、安定性や速度、アップスケーラーや…
Stable Diffusion記事まとめ

ComfyでWANを使用して動画生成をする方法
SAKASA AI
ComfyUI + Wanで動画生成!i2v・t2vをRunPodで簡単に使う方法 | SAKASA AI ComfyUI + WanでAI動画生成!i2v(画像→動画)、t2v(テキスト→動画)、VACEモデルの使い方をRunPod環境でわかりやすく解説。GPU目安やテンプレート設定も掲載。
ファイルのアップロード方法についての詳細はこちらのアコーディオンをCLICKして展開してください。
少量の画像生成や、ちょっとした学習目的の場合は、アップローダー付きのテンプレートを使用してファイルをアップロード出来ます。
安心な利用には、学習終了直後にローカルへダウンロードする事を忘れないようにしましょう。
| 方法 | 解説 |
|---|---|
| ブラウザ | Web UIのFile機能からだけで可(RunPodのPod内の画面からドロップでアップロード出来ます)※画像生成用途、少量の学習など |
| SFTP | WinSCP, FileZillaなどで高速転送 |
| Google Drive | rcloneで連携/保管する方法この方法は簡単で便利なので本格使用の方におすすめです。 |
※ここで、”rclone”の設定を行う方の為に、こちらのrcloneの設定方法を解説した記事のリンクは新しいタブで開く仕様になっています。
SAKASA AI
【rclone(アールクローン)】の使い方・クラウド×ローカル【ファイル転送・同期・バックアップ】方法 | SA… RunPodやクラウドAI環境でのLoRAモデル管理に便利なrcloneの導入方法を初心者向けに解説。「rclone 入らない」「rclone パスが通らない」「rclone version が効かない」な…
ブラウザで、直接画像のアップロードを行う場合の目安
| 条件 | 内容 |
|---|---|
| 画像枚数が少ない | 例:8枚〜40枚程度 |
| ファイルサイズが小さい | PNG・WEBP・JPEGなどで数MB以下 |
| 毎回作業環境を大きく構成し直さない | 一時的にアップ → 処理してDLして終了 |
SAKASA学習目的の場合は、ここから学習用データのアップロードと設定をしていきます。あと少し、がんばって!
自作LoRAの作成手順
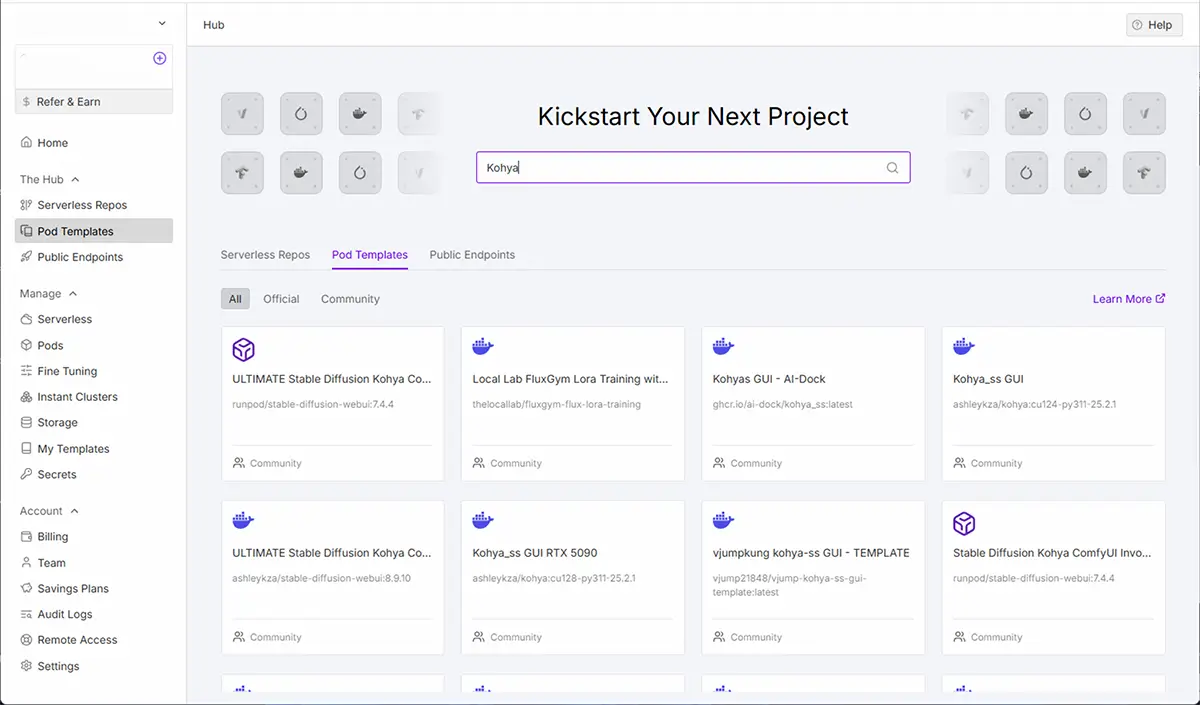
学習目的の場合は、学習専用テンプレートを使います。
LoRA学習に最適なテンプレート:例
RunPodのテンプレート: Kohya、 LoRA 、DreamBooth 、Trainerなどで検索これらのテンプレートには、以下が入っています。
- Kohya_ss GUI(LoRA学習に特化したツール)
- 必要なライブラリ
- Web UI付きでわかりやすい
※これらのテンプレートを選べば、LoRAの学習設定ができますが、先にLoRA学習の流れを見てみましょう。
LoRA学習の大きな流れ
| ステップ |
|---|
| 1. (例)Kohya_ss GUIのテンプレートでPod起動 |
2. *学習用データセット をアップロード(例:/training/dataset/) |
3. *ベースモデルを /models に入れる(例:Anything-v4.5.safetensors) |
| 4. Kohya GUIでパラメータ設定(学習ステップ、学習率など) |
5. 学習開始→ .safetensors ファイルとしてLoRA完成 |
| 6. そのLoRAを他のWeb UIに移して画像生成に使う |
未来上記の用意がすべて整っている場合は、このままPodを”Deploy”して学習を始める事が出来ます!!
学習用データセット
*学習用データセットとは、LoRAで学習を行う際に使用する画像データとタグのセットの事を指しています。
学習用データセットの作成方法については、こちらの記事をご覧ください。
学習用データセットの作成方法
【自作イラストをLoRA化】画像とキャプション(テキストタグ)の準備からフォルダ構成まで徹底解説 学習用データセットの作り方 LoRA(Low-Rank Adaptation)は、既存のAIモデルに対して、自分のイラストや作風を学習させられる技術です。でもいざ始めようとすると── 「…
拡張子
.safetensors(推奨).ckpt.pt(LoRAモデルやVAEに多い)
ベースモデルの準備
Stable Diffusion 1.5、あるいは、SDXL 1.0 baseの基本的なモデルのみで、別のモデル(例:アニメ特化、写真特化など)を使用せず、
Kohya LoRA DreamBooth Trainerなどを使用して、画像生成やLoRA学習をするという目的の場合は、自身の作品の”学習用データセット(リサイズ済み+タグ付け済)”をRunPodにアップロードして学習を始める事が出来ます。
テンプレートに入っていないモデルを使用して学習をしたい場合
ベースとなるモデルは以下の方法で用意します。
- Civitai(https://civitai.com)などのモデル配布サイト
Civitaiについて、詳しくはこちらの記事をご覧ください - Hugging FaceなどのGitHub/公開リポジトリ
Higging Faceについて、詳しくはこちらの記事をご覧ください - 自分で学習したLoRA(後でアップロード)
自分の作品に合う作風か、確認(必要なら画像生成テスト)をしておきます。
| 比較項目 | Hugging Face | Civitai |
|---|---|---|
| 用途 | 公式モデル(SD1.5、SDXLなど)や研究系モデルが中心 | ユーザーが公開したカスタムモデルやLoRAを探すのに便利 |
| モデル例 | runwayml/stable-diffusion-v1-5 | line-art-anime-LoRA, realisticVision, Deliberate, etc |
| 検索性 | やや専門的で開発者向き | 画像付きで直感的に探せる(UIも一般ユーザー向け) |
| URL | Hugging Face公式ページ | Civitai公式ページ |
※ セキュリティと読み込みの安定性のため.ckpt よりも .safetensors形式が推奨されています。
【例】Hugging Faceからベースモデル(ここでは、SD1.5)をダウンロードする場合
今回は、stable-diffusion-v1-5で解説していきます。他のモデルを使用される場合も手順は同じです。
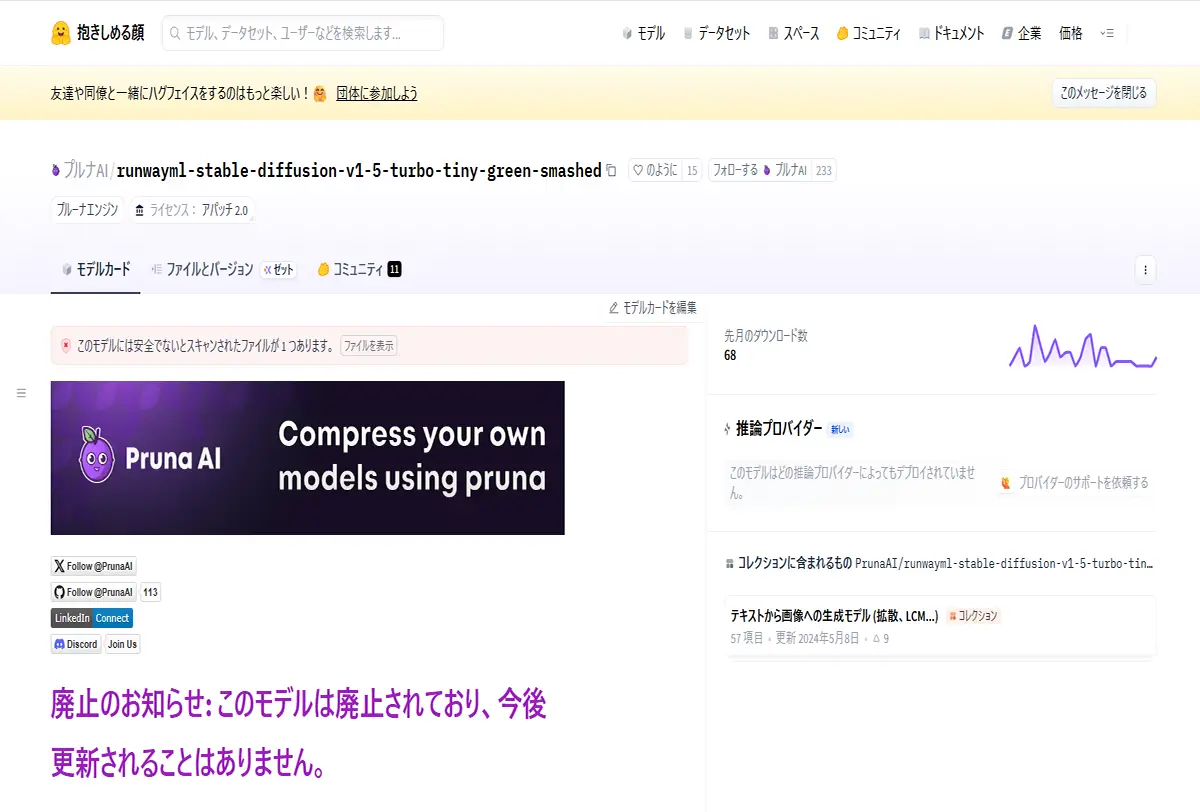
※「runwayml/stable-diffusion-v1-5」のリンクは、現在アクセスできない状態です。このモデルは2024年8月以降、Hugging Faceから削除されている為、直接検索すると、下の様な表示になってしまいます。
代替の公式アーカイブ:Comfy-Org/stable-diffusion-v1-5-archive
現在は、Comfy-OrgというHugging Faceのユーザーが、元のモデルとハッシュ値が一致する完全なアーカイブを提供していますので、こちらからダウンロードしていきましょう。Hugging Face(HuggingFaceにアクセスして、Comfy-Org/stable-diffusion-v1-5-archiveを検索して、ファイルとバージョンからダウンロード出来ます。)
Comfy-Org/stable-diffusion-v1-5-archive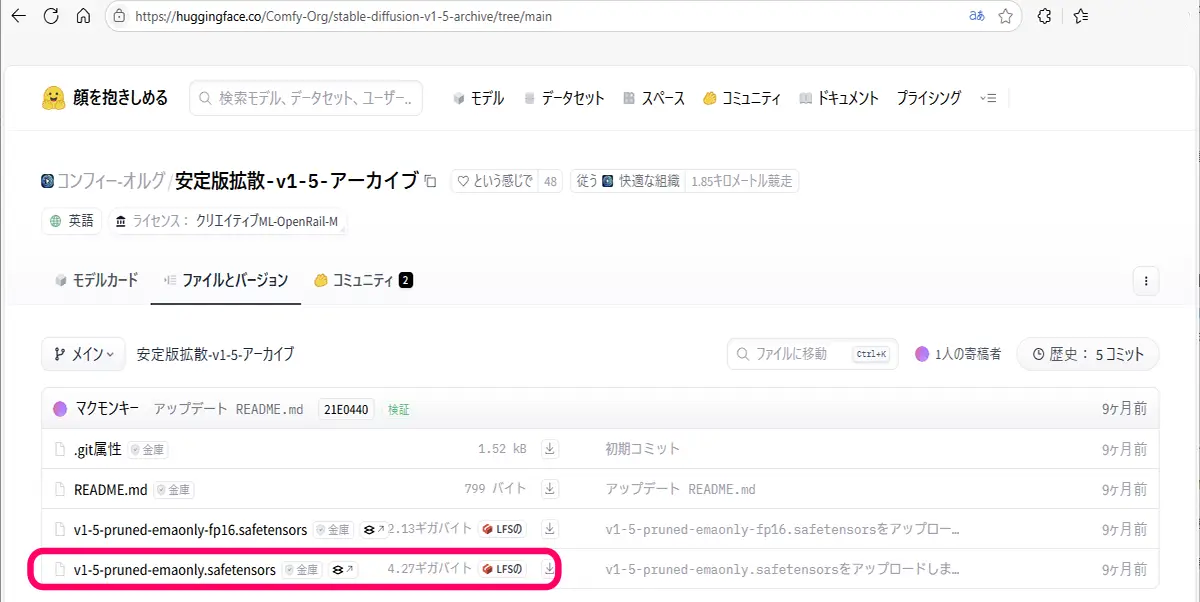
このページには、以下のファイルが含まれています
v1-5-pruned-emaonly.safetensors(元のモデルと同一)v1-5-pruned-emaonly-fp16.safetensors(FP16形式に変換されたバージョン)Hugging Face
これらは、元のRunwayMLモデルと完全に同一の内容で、LoRA学習や画像生成に安心して使用できます 。
使用したいモデルファイルをダウンロードして
注意点
- LoRAを本格的に学習したい場合や細かな差異にこだわる場合は、FP32(通常版)の方が安心です。
- 一部のツールやUI(例:AUTOMATIC1111)では、FP16モデルが正しく読み込めないこともあるため、注意が必要です。
モデルをアップロードする場所(例)
| モデルの種類 | アップロード先フォルダ(RunPodのWeb UI) |
|---|---|
| ベースモデル | /stable-diffusion-webui/models/Stable-diffusion/ |
| LoRAモデル | /stable-diffusion-webui/models/Lora/ |
| VAEモデル | /stable-diffusion-webui/models/VAE/ |
Podが起動したら、Web UIやFile Managerから上記の場所にアップロードします。
UI付きのテンプレートでアップロードする方法は、テンプレートによってまちまちですが、主に、File UploaderかJupiterLabを使用します。
あわせて読みたい
「RunPodでのJupyterLabの使い方:workspaceとの違いも解説」【⓪基礎・3.JupyterLab編】 JupyterLabの使い方 RunPodでテンプレートを使っていると、よくパッケージされている「JupyterLab(Jupyter Notebook)」や「workspace」。この2つは何が違うのか?そし…
LoRA学習での注意点
- LoRA学習に他人の著作物を使用した場合 → その著作物のライセンスが商用OKである必要があります。
- 再配布やLoRAの販売時 → ベースモデルを含めない形で(LoRAだけを)配布すればOKです。
※商用利用とライセンスについての詳細はこちらの記事をご覧ください。
SAKASA AI
Hugging Face Hub(全体)と Spaces(Webアプリ)の商用利用とライセンスの見方 | SAKASA AI 「AIで画像を作ってSNSやブログに使うだけだから大丈夫」と思いがちですが、実はその画像がライセンス違反になる可能性があります。商用利用NGのツールを使うリスクと、ど…
LoRA学習の手順と細かな設定や配置については、こちらの記事で詳しく解説しています。
あわせて読みたい
LoRAとは?仕組み・学習・使い方・学習パラメータまで【LoRA完全ガイド】 LoRAとは何か? LoRAとは、Low-Rank Adaptation(低ランク適応)の略で、大規模なモデル(例:Stable Diffusion)の重みをすべて再学習するのではなく、一部だけを効率…
この後、モデルと自分の画像をフォルダに配置して、Kohya_ssを使用してLoRA学習をしていきます。続きは【3⃣ 応用編】です。
【③ 応用編】Kohya_ssを使用してLoRA学習をする方法
【RunPod】で”Kohya_ss”を使用して”LoRA学習”をする方法【③応用編】 本記事では、クラウドGPUのRunPod内で、 ”Kohya_ss”のテンプレートを使用して、”LoRA学習”をする方法を解説しています。 RunPodの基本的な使用方法については、 こちら…
【⓪-1 Podの見方と使い方】
RunPodの【Podの見方と使い方】と【接続オプションの使い方】【⓪基礎・1.Pod編】 RunPodの大まかな使用方法、流れは こちらの記事でまとめています。 ”RunPodの使用方法と手順”については、上の記事でかなり細かくまとめたつもりでいました。しかし、…
【⓪ -2 GPUの選び方】
RunPod×Kohya_ss GUI|GPU非対応の原因・互換表まとめ【⓪基礎 2.GPU編】 RunPodでKohya_ss guiが動かない?原因はGPU非対応かも! Kohya_ssは学習に特化してる分、ちょっとGPUとの相性がシビアかも…。GPUエラーが多めのツールだよね。 今回は…
【① 解説編】
クラウドGPU”RunPod”とは?画像生成・LoRA学習の最適解?!個人利用の効率よいクラウド環境【①解説編】 ComfyUI、Stable Diffusionなどの画像生成も使いやすい Stable Diffusionで「思う存分、画像,動画生成がしたい」「自分の作風を学習させたい」「LoRAやDreamBoothを試し…