Qwenを使う前提でComfyUIを組むと、考え方が変わる
最近は、Stable Diffusion以外の生成モデルが
ComfyUIで扱われています。
中でもQwen系モデルは、
従来のSD前提のワークフローとは
考え方そのものが異なる部分が多くあります。
使いたいノードが
LoRAをどう使うか、
顔の同一性をどう保つか、
参照画像をどう扱うか。
これらはStable Diffusionでは「お決まりの解」がありましたが、
Qwenを前提にすると、その解がそのまま通用しない場面が出てきます。
この記事では、私がQwen前提でComfyUIを組む中で気づいたポイントや、作業の考え方がどう変わったかをまとめています。
・なぜその発想に至ったのか
・なぜSDの延長ではうまくいかなかったのか
といった「考え方の違い」を中心にまとめます。
目次
なぜ「Qwen前提」でComfyUIを考えるのか
- モデルを決める
- 必要ならLoRAを足す
- IP-Adapterで顔を固定する
- ControlNetで構図を寄せる
この流れは、SDでは合理的だし、実際に多くのケースでうまくいきます。
だから疑問を持つ理由がありませんでした。
ただ、Qwenを使いはじめて、
少しずつ疑問が出てきました。
Qwenで生成する静止画は、
「絵柄を作っている」という感覚がほとんどありません。
プロンプトで細かく誘導しなくても、
構図や空気感が自然に立ち上がってきます。
精度も高いし、完成度も高い。
でも、「自分が触っている感覚」はありません。
そして決められた枠の中で遊ばせてもらっている事に気付いてきます。
そこでようやく、
モデルの問題ではなく、ComfyUIの組み方そのものが
SD前提の頭のままの自分に気付いてきたのでした。
Qwenを使っているのに、
頭の中ではまだStable Diffusionを使っている。
QwenはStableDiffusionでは無いのだから、
「Qwenを使う前提」でComfyUIを組み直していく必要がある。
どこで決めて、どこを任せるのか。
何を固定し、何を捨てるか。
Stable Diffusion前提の構成とは何だったのか
これまで私たちが「当たり前」だと思ってきたComfyUIの構成は、ほとんどが Stable Diffusion前提 で最適化されたものでした。
Checkpointを読み込み、CLIPでプロンプトを解釈し、
Samplerでノイズを削り、LoRAで癖を足し、
足りなければControlNetで形を縛る。
この流れは合理的で、再現性が高く、
「狙った絵を安定して出す」ことにおいて、非常に優秀なワークフローでした。
LoRAを中心に据える設計思想
特にLoRAは、その中心にありました。
- キャラを固定する
- 画風を寄せる
- ブレを抑える
- 出力を“自分のもの”にする
Stable Diffusion系モデルは、
LoRAで補完されることを前提に設計されていると言ってもいいかもしれません。
だからComfyUIの構成も、
まずはLoRAをどう当てるか
次にSamplerやCFGでどう整えるかという思考順になっていたのだとおもいます。
しかし、この構成には暗黙の前提があります。
それは、
モデルは「未完成」であり、
使い手が後から性格を与えるものという考え方です。
Stable Diffusionは「土台」であり、
LoRAやControlNetは「オプション」。
ComfyUIは、その意思をいかに正確に反映させるかのためのツールでした。
この前提がある限り、
- LoRAを作る
- LoRAを重ねる
- CFGやSamplerで抑え込む
という構成は、自然な選択ですが、
問題は、この前提そのものが、Qwenには必ずしも当てはまらないという事なのかも知れません。
LoRA・ControlNet中心の設計ではなくなっている
LoRAやControlNetが悪くなったわけではない。
Qwenは、それらを「中心」に置く設計思想でないのに、StableDiffusionと同じComfyUI内であたかも同じ仕組みであるかのようにノードを並べられる為、すこし勘違いをしてしまいます。
Stable Diffusionでは、モデルが足りない部分を、外部条件(LoRA・ControlNet)で補う設計でした。
Qwenは「完成度の高いモデル」から始まる
一方で、Qwenは最初から違うようです。
Qwenは、
- 顔の一貫性
- 質感の統一
- 光と空気感の解釈
といった部分を、モデル内部でかなり強く完結させてくれる。
そのため、LoRAやControlNetを「主役」として重ね始めると、
補完ではなく干渉が起きやすくなる可能性がでてきました。
具体的には、
- LoRAを当てるほど「Qwenらしさ」が薄れる
- ControlNetで縛るほど、質感や空気感が均される
- 顔は似ているのに、どこか“別のモデル感”が出る
という現象が起きやすくなる。
だからモデルが持っている表現を最大限尊重する。
手抜きで無く、お任せする姿勢が必要なのかもしれません。
Qwenは「顔を固定する」発想を持たない
Stable Diffusionを使ってきた人ほど、「顔を固定する」という考え方を当たり前の前提として持っている。
LoRAで顔を覚えさせ、IP-Adapterで参照し、崩れたら強度を上げる。それが正解だと思っていた。
けれど、Qwenはその必要すらない。
完成品を出すためのノード構成ではなくなる
これまでのComfyUIは、「最終的に完成品を出すための構成」を作るものだった。
ノードはできるだけ少なく、迷わず一枚の完成画像にたどり着くことが正解
しかしQwenはどうだろうか。
一度で完成させようとするほど、難しいと感じる。
そしてその感覚の違いを決定的に見せつけたのが、Qwenの多角度キャラ生成のノードテンプレでした。
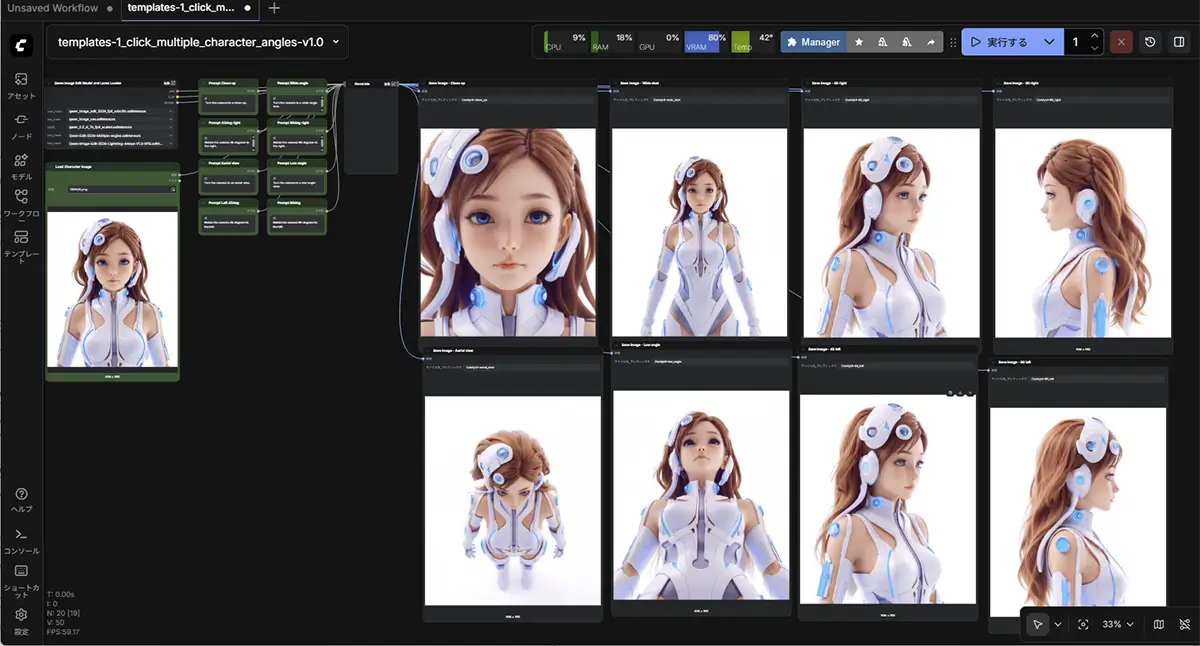
SD多角度テンプレとの違い
| 項目 | Stable Diffusion | Qwen |
|---|---|---|
| 同一性 | 固定する | 解釈を保つ |
| 主役 | LoRA / IP-Adapter | ベース生成 |
| ControlNet | 多用 | ほぼ不要 |
| プロンプト | 詳細指定 | 最小限 |
| 成功条件 | 強制力 | バランス |
プロンプトの役割が「指示」から「方向付け」に変わる
Stable Diffusionでは、プロンプトは「指示文」でした。
細かく書けば書くほど、モデルはその通りに従い、意図した要素を拾ってくれる。だから言葉は多く、具体的であるほど良いとされていました。
Qwen流の多角度設計
- 何も固定しない
- 多角度は「同一性テスト」ではなく
モデルの解釈能力を見る工程 - 顔の完全一致を狙わない
- 「この人物だと自然に認識できるか」を見る
- ズレは失敗ではなく、情報
つまり、
多角度 = 固定確認
ではなく
多角度 = 解釈の一貫性確認
モデルに“覚えさせる”のではなく、
モデルが最も自然に解釈できる起点を与える
という立場に変わっている
ストレージとVRAMの感覚も一変する
Qwenを本格的に使い始めて、ストレージとVRAMに対する感覚も大きく変わりました。
Stable Diffusionでは、モデルは比較的軽く、必要に応じて入れ替えるものでした。しかしQwenでは、一つ一つのモデルが重く、しかも用途ごとに複数のバリエーションを持ちます。
Text Encoder / Lightning / 派生モデルの管理問題
Text Encoder、軽量版、Lightning系──どれか一つを選べば済む、という話ではなくなっています。
結果として、VRAMだけでなく、ローカルやNetworkVolumeの容量そのものの考え方も自然と変化します。
モデルを「必要な時に落とすもの」から、「常に手元に置いておく前提」へ。
Qwen前提で考えると、生成環境そのものの設計思想が変わってきます。
クラウドならComfyUIを“環境ごと使い捨てられる”
Qwen前提でComfyUIを組むようになってから、環境そのものの扱い方も変わりました。
ローカルでは、モデルやノードが増えるほど環境は固定化され、壊さないよう慎重になる。けれどクラウドでは、その前提が崩れる。
必要なモデルと構成だけを用意し、試し、違和感があれば丸ごと捨てる。
ComfyUIを「育てる環境」ではなく、「目的ごとに立ち上げる環境」として扱えるようになりました。
この使い方は、Qwenのようにモデル構成が重く、試行錯誤が前提になる場合、特に相性がいいようです。
DockerやRunPodを使った環境分離は、この発想を現実的なものにしてくれます。
あわせて読みたい
【保存版】ComfyUIが急に動かない原因はこれだった!ローカル環境の落とし穴と、クラウドで一発解決でき… ComfyUIが急に動かない原因 本記事では、ローカル勢が知らずにハマりがちな 「本当の原因」 を徹底解説しながら、最後に Docker などのコンテナ環境や、RunPod などのク…
あわせて読みたい
【RunPodの料金と使い方】Stable Diffusionなどで画像生成やLoRA学習をする方法【②実践編】 RunpodでStable Diffusion系画像生成やLoRA学習をする方法 Stable DiffusionやLoRA学習では、長時間GPUをフル稼働させるため、発熱や電源の安定性が大きな課題になりま…
Qwen×Seedance
Qwenで作った画像をSeedanceで動画化したとき、
思ってもいなかった質感の変化が起きる。
それについては、こちらの記事で書いています。
SAKASA AI
404: ページが見つかりませんでした | SAKASA AI AIを活用したクリエイティブの可能性を探るサイトです。初心者にも分かりやすく生成AI技術、専門用語をツールの使い方を解説しています。画像生成をメインに、WEB、PCに関…