Kohya_ssとは?LoRA学習に特化したGUI版の使い方【完全ガイド2026年最新版】

Kohya_ssとは?
本記事では、Kohya_ssとは何かという基礎から、LoRA学習に特化したGUI版の使い方、
そして2026年時点の最新UIの実践手順までをまとめて解説します。
目次
Kohya_ssとは何か?
Kohya_ss(kohya_ss) とは、Stable Diffusion向けの LoRA(Low-Rank Adaptation)学習に特化したGUI対応ツール です。
学習用画像の準備からキャプション生成、各種パラメータ設定、LoRAの学習実行までを一括で操作でき、コマンド操作に不慣れなユーザーでも比較的簡単にLoRAを作成できるのが特徴です。
LoRA(Low-Rank Adaptation)は、Stable Diffusionのような大規模モデルに対して、低コストで特定の情報(キャラ・作風など)を学習させる軽量なファインチューニング手法です。
元のモデルの重みはそのままに、一部の重みだけを小さな「差分パラメータ(LoRA層)」として学習・保存します。
Kohya_ssはLoRAを学習するためのツール(GUI付きスクリプト群)で、Stable Diffusionベースの画像生成モデルに対して、
- LoRA学習(Low-Rank Adaptation)
- DreamBooth学習
- Textual Inversion
- フルファインチューニング
などを行うための多機能なトレーニングツールです。
| 特徴 | 内容 |
|---|---|
| GUI対応 | Web UIで初心者でも操作しやすい(Gradioベース) |
| 柔軟な設定 | rank, alpha, learning rate, optimizerの選択など細かく設定可能 |
| 画像ラベリング機能 | キャプションの自動生成ツール(BLIP)などが統合されている |
| 複数形式の保存 | .safetensorsやDiffusers形式のLoRA保存に対応 |
| RunPodやGoogle Colab対応 | クラウドでも動作させやすい構造になっている |
現在ではローカル環境だけでなく、RunPodやColabなどのクラウドGPU環境でも広く利用されており、個人クリエイターから実務用途まで幅広く使われています。
※Runpodでの使用方法も後ほど解説しています。
Kohya_ssでできること/できないこと
- できること
- LoRA / LyCORIS 等の学習をしてオリジナルモデルを作る
- キャプション生成(WD14 / BLIP2)
- できないこと
- 画像生成(画像生成ツールではない)
- 元画像よりをグレードアップさせたLoRAモデルを作る(モデル自体を魔法のように良くするものではない)
Kohya_ssのGUI版ツールの導入方法
Kohya_ssのローカルPCへの導入方法はこちらの記事をご覧ください
Kohya_ssをクラウドGPU”RunPod”でLora学習をする方法はこちらの記事をご覧ください
Kohya_ssの画面構成と役割(全体マップ)
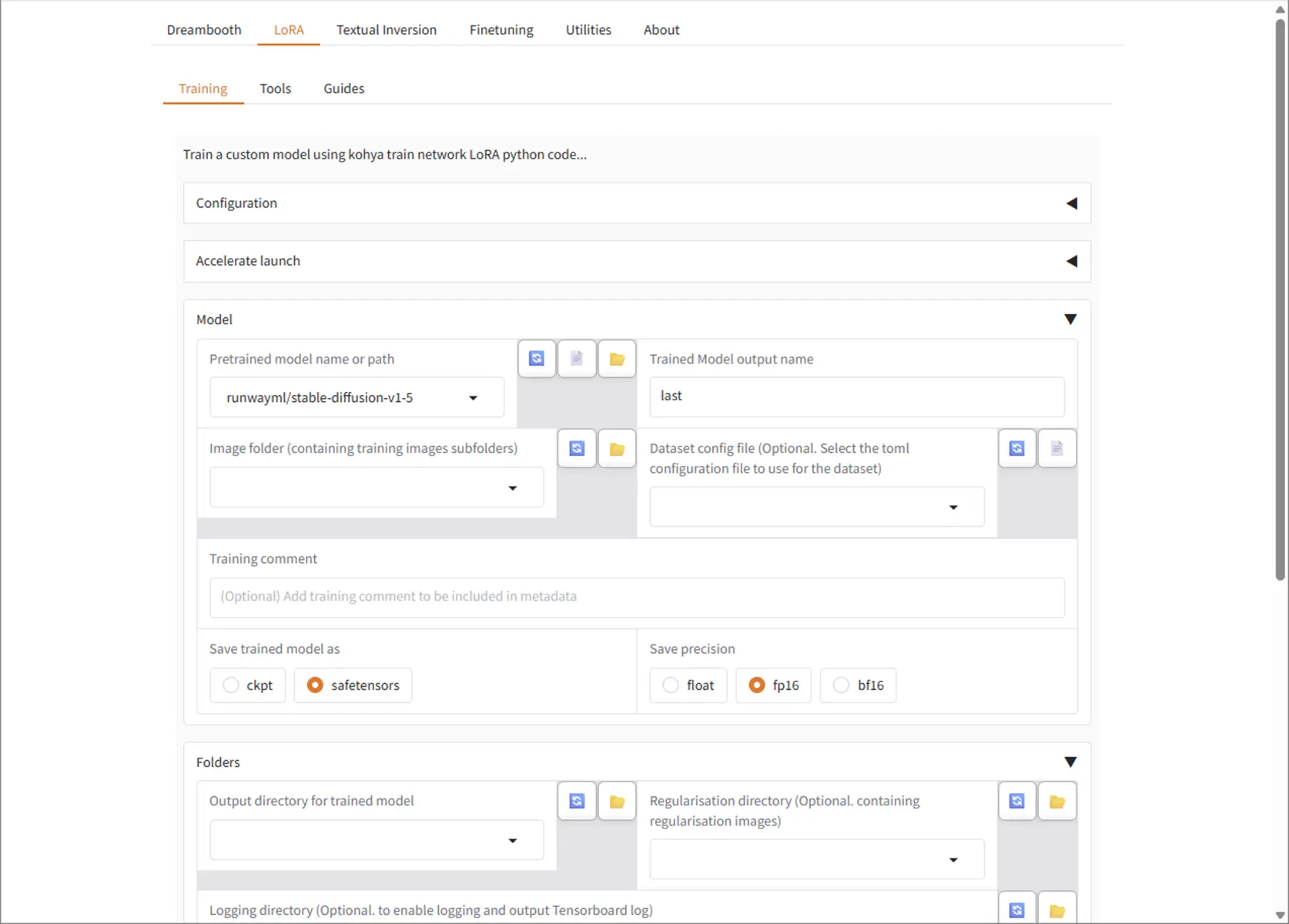
Kohya_ssの画面構成と役割はこのようになっています。
- Dreambooth ← Dreambooth学習用タブ
- Training
- LoRA ←LoRA学習用タブ
- Training
- Textual Inversion
- Finetuning
- Utilities
- Captioning ←キャプション生成用タブ
- About
※この記事では、主に、Lora/学習について書いています。
Dreambooth学習に関しては、上のリンク内でをご覧ください。
事前準備
 未来
未来下準備がLoRAモデルの出来を左右するよ!
事前に準備が必要なもの
- Checkpointsモデル(Stable Diffusion 1.5系 or SD) ※後ほど解説しています
- 学習画像
- 例:
dataset/images/character_name - 10〜50枚程度からでもOK
- 例:
- キャプション(テキストタグ or 文章)
.txtファイル- 手動作成 or WD14 / BLIP2 などで自動生成
※キャプション生成は、現在ではKohya_ss内でも精度が高く、生成から学習まで、完結も可能です。その場合は、学習用画像のみの準備で学習できます。
学習画像とテキストタグの事前準備
【自作イラストをLoRA化】画像とキャプション(テキストタグ)の準備からフォルダ構成まで徹底解説 学習用データセットの作り方 LoRA(Low-Rank Adaptation)は、既存のAIモデルに対して、自分のイラストや作風を学習させられる技術です。でもいざ始めようとすると── 「…
Kohya_ssのキャプション生成機能について
Kohya_ssには、拡張機能のWD14 Tagger(ConvNeXt V2) がタブが標準で組み込まれており、
画像から Danbooru形式のタグを自動生成 できます。
※ Utilitiesタブのキャプション機能に関する詳細と使用方法に関してはこちらをクリックしてください
Kohya_ssの基本的な学習フロー
 未来
未来詳細はこのあと解説しています。まずは流れを見ていきましょう
Kohya_ssは、LoRA学習に特化したGUIツールです。
実際のところ、すべての項目を理解しなくても、最低限の設定だけでLoRA学習は可能です。
ここでは「まず動かす」「失敗しにくい」ことを重視した、最小構成の学習フローを整理します。
STEP
学習データの配置とフォルダー指定
- Image folder
dataset/
└ images/
└ 1_character_name/
├ image001.png
├ image001.txt
├ image002.png
└ image002.txt
1_character_name/…これが、自分の学習用データ(dateset)フォルダ
STEP
ベースモデル(Checkpointsモデル)を指定する
- Stable Diffusion 1.5系 or SDXLなど
- Kohya_ssでは 「Model」欄で1つ選ぶだけ
STEP
ベースモデル関連の設定
- Pretrained model name or path
- VAE(使う場合/使わない場合)
STEP
出力先とLoRA名を設定する
最低限必要なのは以下です。
- Output name
→ 作成されるLoRAのファイル名 - Output directory
→ 保存先フォルダ
この2つが未設定だと、学習が始まっても成果物が見つからない。
STEP
学習設定(最小限)
細かいパラメータは多いですが、最初は触る必要があるものはごく一部です。
- Network Rank(dim)
- 8 / 16 あたりが定番
- Epoch
- 5〜10程度
- Batch size
- VRAMに応じて 1〜2
- Learning rate
- デフォルト値で問題なし(最初は変更しない)
※Kohya_ssは「設定を詰めなくても一応動きます」
STEP
学習を実行する
- GUIの Start Training を押すだけ
- 初回は以下の理由で時間がかかることがあります
- ライブラリの初期化
- キャッシュ作成
- WD14 / BLIP2 使用時のモデル読み込み
ここで止まったように見えても、失敗ではないケースが多いです。
気長に待ちましょう。
STEP
LoRAの完成
- 学習が完了すると
.safetensorsが出力される - Stable Diffusion / ComfyUI に読み込んで動作確認
うまく学習できていない場合は、
Epoch / Rankを調整します。
STEP
LoRAを読み込んで生成テスト
WebUI / ComfyUI でLoRAを読み込み
トリガーワードを入力して挙動確認
強すぎる / 弱い場合は:
- weight 調整
- Epoch / Rank の見直し
詳細設定は下で解説しています。
Checkpointsモデルとモデルフォルダ構成について
Checkpointsモデルとは?Kohya_ssで使用する学習元モデルについて
ここが、おそらく一番の初心者の方の”つまづきポイント”です。
Kohya_ssでLoRA学習を行うには、
必ず「学習元となるCheckpointモデル」が必要です。
これは、Stable Diffusionで画像生成に使用する.ckpt や .safetensors 形式のベースモデルを指します。
このCheckpointモデルが存在しないと学習は開始できません。
Kohya_ssでのLoRA学習は、
- 設定項目は少ない
- でも 「どのモデルを、どこに置くか」だけは絶対に間違えられない
という特徴があります。
※ Kohya_ssのGUIには、モデルは入っていません。
Checkpointsモデルは自分でダウンロードして指定のフォルダに配置する必要があります。
Checkpointsモデルが入っていない状態では、学習は出来ません。
Diffusersモデルは別の扱いになる(※詳細は別記事で解説)
Checkpointsモデルの選び方は、こちらの記事の、”LoRA学習で使用できるモデル”の項目で詳しく書いています。
使用出来るモデル
- Stable-diffusion
- Lora
- VAE
- embeddings
モデルフォルダの基本構成
kohya_ss/
└─ models/
└─ checkpoints/
├─ model.safetensors
└─ model.ckpt
Runpod×Kohya_ss
RunPod内では、Checkpointsモデルの自動ダウンロードと、モデル自動配置機能
拡張機能(別途追加する必要がある)のWD14 Tagger(ConvNeXt V2)も自動セットアップされているテンプレートが使用できます。
学習画像のアップロード + 数クリックでLora学習が出来るRunpodテンプレート
【RunPod×Kohya_ssテンプレート】LoRA学習とWD14・BLIP2キャプション生成解説|最新版 キャプション生成からLoRA学習まで1Podで完結させる 本記事では、クラウドGPUのRunPod内で、 WD14”と、モデルダウンローダーが組み込まれた”Kohya_ss”のテンプレートを…
実践記事・環境別ガイドはこちら
- ▶ ローカル環境でのKohya_ss
- ▶ RunPodでKohya_ssを使う方法
- ▶ エラー対処まとめ
LoRA学習での設定項目の詳細と学習パラメータ解説
※学習の際の設定は、学習する**データセットの内容と、使用するGPUによって設定が変わります。
上記の内容でも基本的な学習は可能ですが、精度を高めたい場合には設定をかえてみましょう。
**データセット・・・自身が学習させたい画像とテキストタグのセットの事を指します。
LoRA用学習設定
GUI画面で以下を設定します。
- Model: (例)
runwayml/stable-diffusion-v1-5 - Train batch size: 下で記載
- Max train steps: 100〜数千(テストなら少なめで)
- Save trained model as:
safetensors推奨 - Mixed Precision:
fp16
「output name」「model name」について
Kohya GUI の「Training」で、「LoRA」や「DreamBooth」などの学習種類を選ぶと、「Training」や「Basic」タブが表示されます。
「output name」で選択したフォルダ名が .safetensors のファイル名になります。
| ラベル名例 | 説明 | 例 |
|---|---|---|
Output name | 出力されるLoRAの名前(.safetensors) | 20_cat |
Output directory(出力フォルダ) | 保存先のディレクトリ(/outputsなど) | /outputs |
output_name = last(デフォルト)の場合
- 学習によって出力されるモデル(
.safetensorsなど)のファイル名が、last.safetensorsになります。 - これは **「最後のエポックのモデル」**という意味合いで、わかりやすい汎用名です。
- 保存先は通常
/outputsに保存されます。

上の画像内では、Trained Model output name に10_sakasaを指定しています。
この例では、/kohya_ss/output/10_sakasa にLoRAファイル(.safetensors)が生成されます。.safetensorsは、ComfyUIや、AUTOMATIC1111 などに組み込めば即使用可能です。
注意点
空白や日本語のパスは避ける(例:C:\Users\ユーザー名\マイ ドキュメント\ は非推奨)
Windowsではバックスラッシュ \ を使う(ただしGUIや設定ファイルではスラッシュ / でも通ることが多い)
手動で読み込ませる方法(上級者向け)
もし別フォルダに置きたい場合は、WebUIの webui-user.bat や launch.py を編集して環境変数 --lora-dir を追加することで、LoRAの読み込み場所を変更できます(ただし一般には非推奨)。
VRAM制限あり/なしでの設定の主な違い(一覧)
| 設定項目 | VRAMに制限がない場合(例:24GB〜) | VRAMに制限あり(例:~8GBの) | 違いの理由・ポイント |
|---|---|---|---|
| 学習解像度 | 768×768、1024×1024 も可能 | 原則512×512まで(768は片側のみ) | 高解像度はVRAMを大幅に消費 |
| バッチサイズ(batch) | 2〜8(高速学習) | 1(これ以外はほぼOOM) | VRAMに最も直結する項目 |
| LoRA Rank | 8〜32(高精度) | 4〜8(VRAM制限のため低く) | Rankが高いほど学習に必要な重みが増える |
| gradient accumulation | 基本的に不要(バッチサイズで調整) | 必須(例:4〜8) | 小バッチでの学習安定化に必要 |
| mixed precision | fp16 or bf16 | fp16固定(fp32は不可) | 高精度(fp32)はメモリ消費が大きい |
| キャッシュの活用 | 使わなくても余裕がある | cache latents は必ず有効 | エンコード処理を減らしメモリを節約 |
| optimizer | 何でも選べる(AdamW, Lion, DAdaptなど) | AdamW8bit, Lion8bitなど軽量最適化器推奨 | 8bitオプティマイザはVRAM消費が少ない |
| 複数モデル同時学習 | 可能(LoRA+TextualInversionなど) | 基本不可(VRAM不足) | マルチ学習は負荷が非常に高い |
| エポック数の調整 | 短時間で済むので少なめでもOK(5〜10) | 小バッチなので多めが必要(10〜20以上) | 学習の進みが遅いため、反復で補う必要あり |
| 学習速度 | 非常に高速(大バッチで並列処理) | 遅い(小バッチ+反復) | 効率の差は大きい |
Train batch size は、主にGPUのVRAM容量によって決めます。
Train batch size を大きくすると、一度に学習する画像の数が増える=使うVRAMも増えます。
目安例(LoRA学習・画像サイズ512×512)
以下は大体の目安です。
| VRAM容量 | 推奨バッチサイズ(batch size) |
|---|---|
| 6GB | 1(低解像度でもギリギリ) |
| 8GB | 1~2 |
| 12GB | 2~4 |
| 16GB | 4~6 |
| 24GB以上(例:A100) | 8以上も可能 |
※ 実際の上限は学習設定や画像サイズによって前後します。
モデルファイル fp16とfp32の違いについてはこちらをクリック
Stable DiffusionなどのAIモデルでは、モデルファイルに「fp16」または「fp32」という表記があることがあります。
これは浮動小数点(floating point)精度の違いを意味しています。
基本的な違い
| 項目 | fp16(半精度) | fp32(単精度) |
|---|---|---|
| 精度 | 16ビット | 32ビット |
| ファイルサイズ | 小さい(例:2GB前後) | 大きい(例:4GB以上) |
| メモリ消費 | 少ない(軽い) | 多い(重い) |
| 処理速度 | 速い(対応GPUなら) | 遅い(より計算コストが高い) |
| 対応GPU | RTX 20XX以降がおすすめ | すべてのGPUで動作可能 |
| 精度(品質) | 若干落ちる場合あり(ほぼ差なし) | 高精度(LoRA学習ではこちら推奨) |
fp16のメリット・用途
- 画像生成に向いている
- 軽くて高速、VRAM消費も少なめ
- GPUに
Tensor Core(例:NVIDIA RTXシリーズ)があると恩恵が大きい - LoRAの**生成(推論)**時はほとんどの場合fp16で十分
fp32のメリット・用途
- 学習(トレーニング)に向いている
- 精度を重視する必要があるときに使用
- LoRAやDreamBoothなどの学習作業にはfp32が安定
- ただし重く、メモリ消費が多い
| 目的 | おすすめ |
|---|---|
| 画像生成のみ | fp16 |
| 学習やLoRA作成 | fp32 |
| 低VRAM環境(8GB未満) | fp16 |
- 入力画像(例:512×512)
- 学習対象のモデル(例:Stable Diffusion v1.5)
- 重みの更新に必要な中間データ(勾配など)
- バッチ全体のデータ(画像の枚数 × 各種情報)
注意点
- フォルダ名は 「Lora」(Lが大文字)。
※小文字の「lora」だと読み込まれないことがあるらしい。 - ファイル名に日本語やスペースが入っていると、うまく動作しないことがあるので、半角英数字・アンダーバーを使用。
「 Save every N epochs」
ave every N epochs は、Kohya_ssでLoRA学習中に、何エポックごとに中間モデルを保存するかを指定する項目です。
| 項目名 | 説明 |
|---|---|
Save every N epochs | Nエポックごとに1回、LoRAファイルを保存する設定 |
例:2 | → 2エポックごとに保存される(2, 4, 6…) |
例:0 | → 中間保存せず、最後だけ保存される |
学習結果の過程を比較したい場合や、学習途中で品質が下がるリスクに備えたい場合に使用します。
「Save every N steps」
ステップ(バッチ数単位)ごとに保存するオプションで、通常は Save every N epochs の方がわかりやすく使いやすいのです。
| 設定 | 動作 |
|---|---|
0 | 最後に1回だけ保存(中間モデルなし) |
1 | すべてのエポック終了時に毎回保存 |
2 | 2エポックごとに保存(バランス良) |
5〜10 | 長期学習向き。ログ用の軽保存 |
「Max train epoch」について
デフォルトの「10」は多いかもしれません。使用データ量によって調整します。
- 意味:「何回データセットを繰り返して学習するか」を指定します。
- デフォルトは
10ですが、以下のように調整するのが一般的です。
| 画像枚数(×1枚に1タグ付き) | 推奨 Epoch |
|---|---|
| 10〜20枚 | 10〜20回 |
| 30〜50枚 | 5〜10回 |
| 100枚以上 | 2〜5回 |
Epoch が多すぎると、訓練データに特化しすぎて汎用性が下がる「過学習」になります。
network_rankについて
network_rank(ネットワークランク)は LoRA学習での超重要な設定項目 です!
これは、LoRAが「元モデルに追加する微小な学習層(低ランク行列)」の**パラメータ数(≒学習力)**をコントロールするものです。
学習できる情報量の多さ(≒容量・精度)を決める
- 数値が高いほど学習能力が高く、表現力も上がる
- でもVRAM消費・ファイルサイズも増える
Rank の目安と比較表
| Rank | 特徴 | 使用シーン例 |
|---|---|---|
2 | 非常に軽量・低精度(LoRA Tiny) | 容量重視。効果は薄め |
4 | 軽量でVRAM節約向き | 8GB環境や軽量キャラ向け |
8 | 標準的な精度と軽さのバランス | 初心者や汎用LoRAに最適 |
16 | 精度重視、高情報量 | 表情・ポーズ・背景も細かく覚えさせたいとき |
32〜64 | 非常に高精度(モデルに近い重さ) | 高VRAM環境(24GB〜)、特定用途向け |
Dreambooth/LoRA Dataset Balancingについて
- こちらは**複数のコンセプトフォルダ(例:キャラA、キャラB)**がある場合の補助機能です。
- 学習画像数が極端に偏っているとき、自動でバランスを取ってくれる処理です。
- たとえばこういう構成
/dataset
├── character_A
│ ├── a1.png
│ └── a1.txt
└── character_B
├── b1.png
└── b1.txt
コンセプト数が多く、かつ枚数バランスに偏りがあるときに使用。
学習ステップ数とは?
LoRAでいう「ステップ数」とは、「どれくらい強く学ばせるか」の指標で、学習に使うデータのバッチを何回処理するかを指します。
「500ステップ」は「バッチ500回分の学習」を意味します。
| 用途 | ステップ数の目安(参考) | 備考 |
|---|---|---|
| 単純な表情差分/ポーズ差分 | 50〜200ステップ | LoRA Rankも低めでOK |
| キャラクターの顔・髪・服などの一貫性を持たせたい | 200〜400ステップ | 学習画像10〜20枚程度想定 |
| オリジナルキャラを強く固定したい | 400〜800ステップ | 学習画像が20〜50枚以上で調整 |
※「ステップ数が多い=強く学習する」ですが、過学習になるリスクも上がります。
画像枚数やバッチサイズ、目的(微調整 or 作風付与)別の具体的な指標
目安1:画像枚数 × エポック数 × バッチサイズ = ステップ数
これがステップ数の基本計算です。
以下は、計算が苦手な自分用に作成した計算ツールです。求めたい値(エポック数orステップ数)をラジオボタンで選択して各数値を入力して計算します。(小数点以下は切り捨て。)
ステップ数・エポック数 計算ツール
ステップ数を求める
エポック数を求める
例1:25枚の画像、エポック20、バッチサイズ1
→ 25 × 20 / 1 = 500ステップ
この構成なら ステップ数500は妥当です。
例2:10枚の画像、エポック10、バッチサイズ1
→ 10 × 10 = 100ステップ
これにステップ数500を設定すると、同じ画像を5回繰り返すことになります。
→ 過学習のリスクが高まります。
一般的なステップ数の目安
| 用途 | 画像枚数の目安 | エポック数 | 合計ステップの目安 |
|---|---|---|---|
| キャラ特化LoRA(簡易) | 10〜20枚 | 10〜20 | 100〜400 |
| 作風付与LoRA(軽量) | 30〜50枚 | 10〜15 | 300〜750 |
| 高精度LoRA(丁寧な作り) | 100枚以上 | 10〜20 | 1000〜2000 |
同じ画像を何度も回すと劣化・崩れやすい(顔が潰れるなど)ため、足りない場合は、「正則化画像(regularization)」で補うことも可能です。
設定の保存
「Load/Save Config file」について
「Load/Save Config file」は、Kohya GUI(kohya_ss)で使う学習設定の保存/読み込み機能です。以下のように使います。
Save Config file(設定の保存)
- 現在GUIで設定した 学習条件(画像フォルダ、出力名、エポック数など) を、
.jsonファイルとして保存できます。 - 次回、同じ学習設定を再利用したいときに便利です。
- 設定をGUIで入力
Save Config fileボタンをクリック.jsonファイル名を指定して保存
例:lora_cat_config.json
Load Config file(設定の読み込み)
- 以前保存した
.jsonの設定ファイルを読み込むと、GUIに自動で値が反映されます。 - 複数のLoRA学習パターンを切り替えて使う時にとても便利です。
Load Config fileをクリック- 以前保存した
.jsonファイルを選択
保存される内容(例)
- 画像フォルダのパス
- 出力名・保存先
- エポック数、バッチサイズ
- 学習率(Learning rate)
- 使用モデルのパス(Pretrained model)
- 正則化や学習スケジュールなどの高度なパラメータも含む
出力される2種類の .safetensors ファイル
① 出力フォルダ名-000004.safetensors
- エポック番号(チェックポイント付き)
- これは「学習ステップ途中のスナップショット」です。
--save_every_n_epochsや--save_every_n_stepsを指定していると、自動で一定間隔ごとに保存されます。- 用途:
- 学習の途中経過を検証したいとき
- 精度が最も高かった中間地点に戻したいとき
例:出力フォルダ名-000004.safetensors → 4エポック終了時のモデル
② 出力フォルダ名.safetensors
- 最終エポックまで完了した学習モデル(最終出力)
- 学習がすべて終わった後、自動的に出力されます。
- 最も安定した「完成モデル」として扱われます。
- 用途:
- 実際に画像生成で使うモデル
- Hugging Faceなどで公開するモデル
カスタマイズしたいときの設定項目
| 項目名 | 説明 |
|---|---|
--save_model_as=safetensors | 出力形式(safetensors / ckpt など) |
--output_name=出力フォルダ名 | モデル名の指定。出力ファイル名の先頭に反映されます |
--save_every_n_epochs=1 | 何エポックごとに中間モデルを保存するか(例:毎回保存) |
--max_train_epochs=10 | 最後のエポックで .safetensors(番号なし)が生成 |
注意点
出力フォルダ名.safetensorsは 学習が最後まで正常に完了しないと生成されません。途中で止まった場合は、番号付き(例:-000004)しか残りませんが、必要に応じてそれを手動でリネームして使うことが可能です。
LoRAの質を上げる再学習について
Kohya_ssでは「再学習」ではなく「追加学習(継続学習)」として扱います。
LoRAの追加学習では、既存LoRAを「ベースモデル」ではなく、「追加のLoRA(Network weights)」として指定し、「ネットワーク重み」として読み込みます
LoRAモデルの配置場所
/models/lora
学習設定画面の Network weights(LoRA weights) に指定してください。
models/lora/my_character_v1.safetensors
これにより
「このLoRAを初期状態として、続きを学習する」
という挙動になります。
チェックポイント(Base model)には、必ず元となるStable Diffusionモデルを指定します。
設定項目
- 「Resume from LoRA」
- または
- 「Network weights」に 既存LoRAのパスを指定
再学習は「修正・補強」向けです。
キャラを大きく変えたい場合は、最初から作り直します。
作成したLoRAモデルを使う方法
作成したLoRAファイルの使用方法は こちらの記事内の"LoRAが使える主なツールとフレームワーク”の項目で解説しています
SAKASA AI
LoRAとは?仕組み・学習・使い方・学習パラメータまで【LoRA完全ガイド】 | SAKASA AI LoRA(Low-Rank Adaptation)とは何か?Stable DiffusionやLLMでの仕組み・学習方法・活用例まで初心者にも分かりやすく解説