【最新版】LoRA学習用画像に自動キャプション(タグ)付けする方法|kohya_ssのWD14 TaggerとBLIP2

kohya_ssのCaptioning機能まとめとWD14 TaggerとBLIP2の違いと使い分け
これまで、 画像タグ生成のために外部ツールとして個別で使用されることが一般的だった WD14 taggerは、
現在では、WD14 tagger が kohya_ss に統合 されたことで、
キャプション(タグ)生成から LoRA 学習までの一連の工程を、
kohya_ss だけで完結できるようになっています。
本記事では、Gradio(グラディオ)をベースにしたUI、 「Kohya_ss」に組み込まれた WD14 tagger 拡張機能 ”WD14 Coptioning”と、”BLIP2”を使用して、LoRA学習用の画像に自動でキャプション(タグ)を付ける方法について解説しています。
※kohya_ss では、WD14 tagger を用いたタグ生成機能が「WD14 Captioning」 として提供されています。
目次
kohya_ss(Gradio製のWeb UI)でのタグ付け(キャプション生成)機能
kohya_ss にある主な Caption / Tag 系の方式
kohya_ss には、 3系統+補助 が存在しています。
① WD14 Tagger
- danbooruタグ形式
- キャラLoRAの事実上の標準
- 再現性・安定性が高い
アニメ・イラスト用途ではほぼこれ一択
SDのTiggerとWD14 Taggerの比較
| 項目 | WD14 Tagger | SD Tagger (DeepBooru系) |
|---|---|---|
| 精度 | ⭐⭐⭐⭐⭐ 非常に高い | ⭐⭐⭐ 中程度 |
| アニメ対応 | ⭐⭐⭐⭐⭐ 特化 | ⭐⭐⭐⭐ 良い |
| 実写対応 | ⭐⭐⭐⭐ 良い | ⭐⭐⭐ 普通 |
| タグ数 | 11,000+ | 6,000程度 |
| 更新頻度 | 頻繁 | 停滞気味 |
| 速度 | ⭐⭐⭐⭐ 速い | ⭐⭐⭐ 普通 |
| LoRA学習 | ⭐⭐⭐⭐⭐ 最適 | ⭐⭐⭐⭐ 良い |
② BLIP / BLIP2
- 自然文キャプション
- 写真・リアル寄り
- SDXL / Diffusers 系向け
用途が合うと強い
③ DeepDanbooru
- 古いdanbooruタグger
- 精度がWD14に劣る
- モデル更新も少ない
現在はほぼ淘汰
④ Manual / 既存txt
自動では無く、手動で作成する方法。
- 既存のタグtxtを使う
- 自分で調整したタグ
- 商用・配布LoRAでは非常に多い
最終品質はここに集約される
実際の使用パターン
WD14 → 人が軽修正 → 学習写真・Diffusers系
BLIP2 → 軽修正 → 学習上級者・販売向け
WD14 → 手動調整 → 再学習WD14 Tagger の特徴
2024-2025年の業界標準
現在は、LoRA学習のタグ付けは、 WD14 Tagger (SwinV2) が 一番人気のようです。
理由
- CivitAI の多くのLoRAが WD14 で学習
- Hugging Face のデータセットも WD14 採用
- コミュニティで最も使われている
WD14 (Waifu Diffusion 1.4)
├─ SwinV2 Transformer(最新アーキテクチャ)
├─ 11,000+ タグ(Danbooru由来)
└─ 2023年以降も更新継続細かいタグ付け
例:同じ画像での出力
WD14:
1girl, solo, blue_hair, long_hair, smile,
looking_at_viewer, school_uniform, serafuku,
white_shirt, blue_skirt, outdoors, sky,
cloud, cherry_blossoms, depth_of_field
DeepBooru:
1girl, blue_hair, smile, uniform, outdoors誤検出が少ない
閾値調整で精度コントロール可能複数モデルが選択可能
WD14 Taggerのモデル
├─ SwinV2(最高精度、推奨)
├─ ConvNext(バランス型)
├─ ConvNextV2(高速)
└─ ViT(実験的)WD14タグ「無調整」と「修正」の違い
出力されたキャプションを、どの様に扱うかも賛否が分かれるところかもしれません。
① 無調整(完全自動)
特徴
- タグ数が多い
- 曖昧タグも混ざる
- 背景・小物・構図タグが大量
学習時に起きること
- モデルが
「特徴を広く浅く」覚える - トリガー無しでも
それっぽく出やすい
結果
- 🔹 出力は安定
- 🔹 破綻しにくい
- 🔹 汎用性が高い
- ❌ キャラ再現度が甘いことがある
② 修正あり(人の意図を入れる)
特徴
- タグ数を削る
- キャラ要素を強調
- 不要背景・構図タグを消す
学習時に起きること
- モデルが
「何を覚えろと言われているか」を理解しやすい - キャラとタグの結びつきが強くなる
結果
- 🔸 キャラ再現度が高い
- 🔸 表情・髪型が揃いやすい
- ❌ 条件が変わると破綻しやすい
- ❌ 融通が効きにくいことがある
無調整の方が「良い」ケース(重要)
枚数が少ない(〜30枚)場合
修正すると 情報不足 になります。
- 無調整:
モデルが補完してくれる - 修正:
覚える情報が足りず不安定
汎用スタイルLoRA
例:
- 絵柄
- 塗り
- 線画
- 雰囲気LoRA
無調整だと
「何にでも乗る」LoRA に。
配布・販売用LoRA
- 使う人のプロンプトが千差万別
無調整は事故りにくい
ControlNet / Comfy併用前提
- 構図やポーズは別で制御
背景タグが残っている方が学習が安定
修正した方が良いケース
キャラLoRA(最重要)
特に
- 顔
- 髪
- 目
- 服
ここは作者が目で見て判断した方がいい
枚数が多い(50〜100枚以上)
ノイズタグが 確実に邪魔になる
トリガーワードを作りたい
トリガーワードを“効かせたい”場合は、最低限の修正は必須なる
ただし 「1行足すだけ」でも・・・
sarena_stylesks_robot
無調整だとトリガーが埋もれる
8割無調整からはじめてみるという選択
- WD14をそのまま生成
- 消すだけ
white backgroundsimple background- カメラタグ
rating:*
- 足すのは最小限
- キャラ名
- 固有特徴 2〜4個
「整理」と
「編集」を少し。
違いはどれくらい出るか?
| 項目 | 無調整 | 軽修正 |
|---|---|---|
| 初見安定性 | ◎ | ○ |
| キャラ再現 | ○ | ◎ |
| 破綻耐性 | ◎ | △ |
| 汎用性 | ◎ | △ |
| 調整コスト | ◎ | ❌ |
WD14 Captioningの使い方
STEP
WD14 Captioningをダウンロードする
※ kohya_ss に最初から入っているのは「WD14を使う仕組み(プログラム)」だけです。
WD14 Captioning は、画像を解析して自動で「タグ形式のキャプション」を生成するAIモデルです。
- Stable Diffusion の画像生成モデル(Checkpoint)ではない
- LoRA 学習そのものを行うモデルでもない
- 「画像 → テキスト(.txt)」を作るためだけの補助モデル
です。
ダウンロードすべきファイル
RunPod や Colab では自動でダウンロードされることがありますが、実際に画像を解析するための
**学習済みモデル(重みファイル)**は、
別途ダウンロードして自分で配置する必要があります。
LoRA学習を手軽に行いたい場合
LoRA学習を手軽に行いたい場合は、モデルなどが入っている Runpodのテンプレートを使用するのがおすすめです。
RunpodでLoRA学習をする方法はこちらの記事をご覧下さい。
以下は、ローカル利用で最も一般的な WD14 Tagger モデルです。
※ kohya_ss のバージョンによっては
convnext / vit など複数種類がありますが、
基本は convnext 系を1つ入れればOKです。
WD14 Tagger(ConvNeXt)→ Hugging Face(公式)
wd-v1-4-convnextv2-tagger.onnxselected_tags.csv
WD EVA02-Large Tagger v3(モデル & タグ辞書)
こちらもモデル本体とタグ定義 CSV が含まれています。
| ファイル名 | 用途 |
|---|---|
model.onnx | 推論用モデル本体 |
selected_tags.csv | タグ語彙ファイル(解析後のラベル一覧) |
注意点
※ モデルファイルは数百MBあります。回線状況によってはダウンロードに時間がかかります。
配置場所
kohya_ss のフォルダ構成
kohya_ss/
└ models/
└ wd14_tagger/
├ wd-v1-4-convnextv2-tagger.onnx
└ selected_tags.csv- Checkpoint や LoRA を置く models とは別
models/wd14_tagger/フォルダに入れる- フォルダ名が違うと kohya_ss が認識しない
STEP
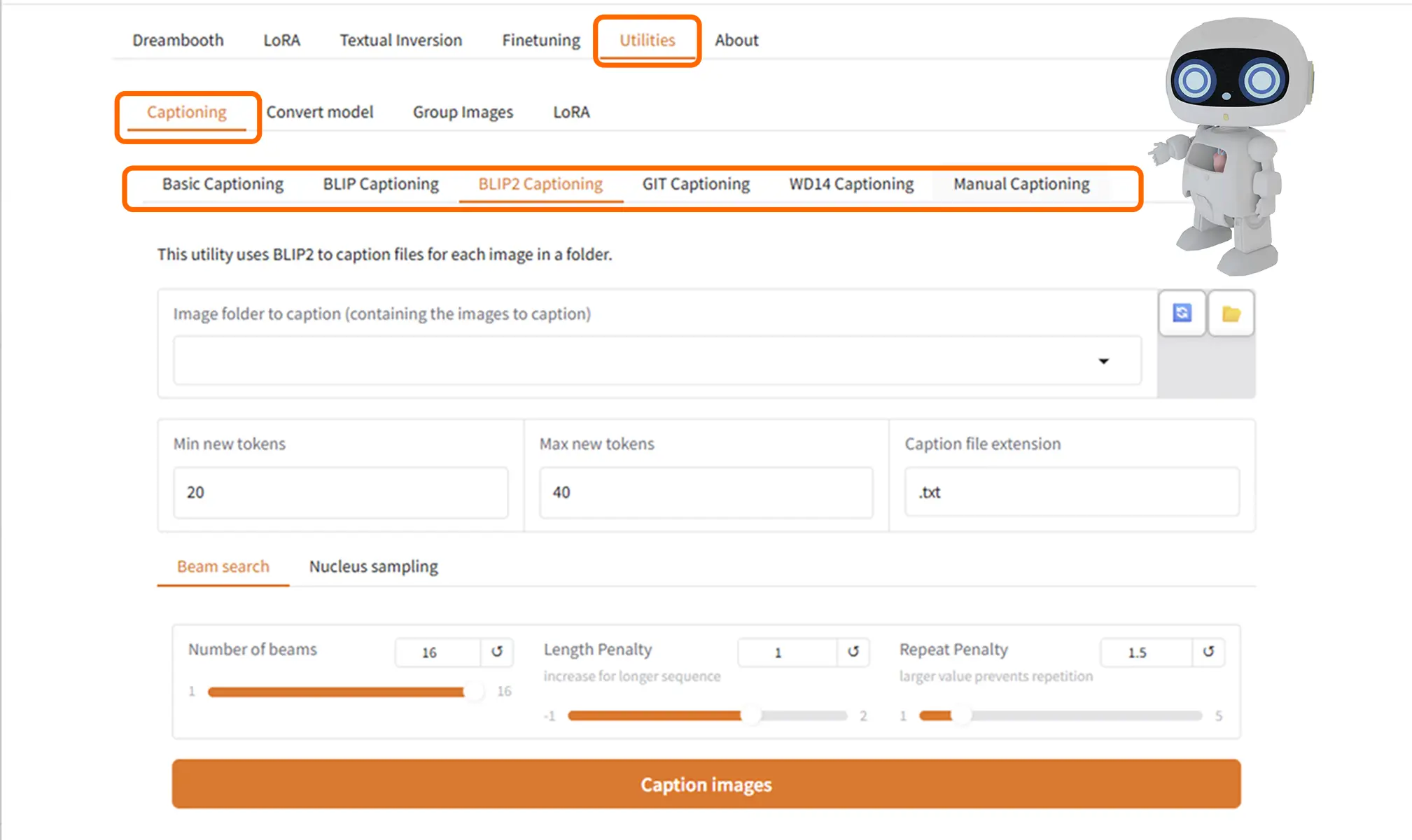
Utilitiesタブを開く
STEP
Captioning セクションを開く
STEP
Caption with WD14 tagger を選択
設定(標準例)
標準的な値から少しづつ調整していく
Image folder: /kohya_ss/dataset/images
Model: SwinV2
General threshold: 0.35
Character threshold: 0.85
Remove underscore: チェック推奨
Caption file extension: .txtSTEP
Caption images ボタンをクリック
反応は薄め。生成してくれているのか不安になったらlogsを確認する。
STEP
出力
/Kohya_ss/dataset/image 内に以下のような.txtが出力が得られます。
1girl, solo, blue_eyes, blonde_hair, long_hair, smile,
open_mouth, :d, hair_ornament, hairclip, white_dress,
sleeveless, bare_shoulders, collarbone, jewelry, necklace,
outdoors, garden, flowers, rose, day, sunlight,
depth_of_field, bokeh※一瞬で生成される時もありますが、画像サイズ、画像枚数などによって生成時間は異なり、遅い時では10分ほどかかる時もあります。
 SAKASA
SAKASA壊れたと思って何とか直そうと頑張って、20分後にみたら生成されていたこともあったよね(笑)
 未来
未来たしかに分かりづらいよね!
20分かかった事もあります・・・ので気長に待ちましょう。
キャプション生成が終わったら早速学習を始めましょう!
続きはこちら・・・
Kohya_ssでのLoRA学習の手順
Kohya_ssとは?LoRA学習に特化したGUI版の使い方【完全ガイド2025年最新版】 Kohya_ssとは? 本記事では、Kohya_ssとは何かという基礎から、LoRA学習に特化したGUI版の使い方、そして2025年時点の最新UIの実践手順までをまとめて解説します。 Kohy…
Kohya_ssのUIで、テキストフィールドのボタンが反応しない時
ブラウザの問題
- キャッシュクリア:
Ctrl + Shift + R - 別ブラウザで試す
- シークレットモードで開く
Kohya_ssのバグ
最新版で既知の問題の可能性もあります。その場合は、再起動、それでもダメな場合は再ダウンロードなどを試してみましょう。
あわせて読みたい
【自作イラストをLoRA化】画像とキャプション(テキストタグ)の準備からフォルダ構成まで徹底解説 学習用データセットの作り方 LoRA(Low-Rank Adaptation)は、既存のAIモデルに対して、自分のイラストや作風を学習させられる技術です。でもいざ始めようとすると── 「…