GPU「GeForce RTX 5090」のスペックを画像生成の視点から解説

画像生成AIを使っていて、「もう少し速ければ…」「高画質にするとエラーが出る…」なんて経験、ありませんか?
今回は、そんな悩みを一発で吹き飛ばすNVIDIA GeForce RTX 5090―について画像生成の視点から見ていきたいと思います。
例えば、Stable Diffusionで1枚生成するのに10秒かかっていた作業は、5090では6秒に短縮。
しかも、ノイズ除去やLoRAモデルなど、これまで“重かった処理”も余裕でこなす計算になります。
本記事では、2025年1月に発表された新世代のグラフィックスカードNVIDIA「GeForce RTX 5090」について、
Blackwellアーキテクチャの実力や、現行のRTX 4090との違い、
そして「本当に買う価値があるのか?」という点まで、多方向から初心者にもわかりやすく解説していきたいと思います。
そして、この記事の最後では、RTX 5090をクラウドで、1時間0.69円~で使用する方法についても書いていますので、チェックしてください。
目次
GeForce RTX 5090
発売日と価格
発売日:2025年1月30日
販売:NVIDIA公式サイトおよび主要小売店で販売。
価格:$1,999(日本国内では約393,800円)
主な仕様と特徴
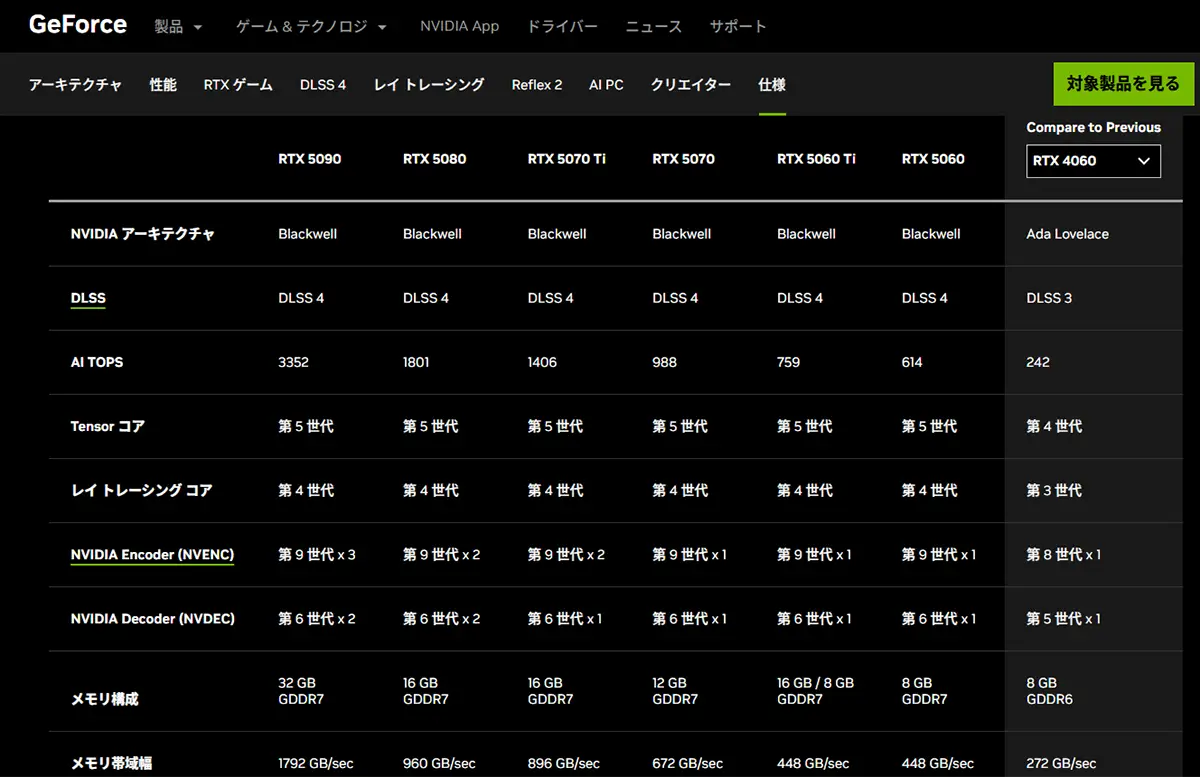
アーキテクチャ:Blackwell(GB202 GPU)
CUDAコア数:21,760
メモリ:32GB GDDR7、512ビットバス
メモリ帯域幅:1.8 TB/s
インターフェース:PCIe 5.0 x16
TDP(消費電力):575W
新機能:DLSS 4、Reflex 2、AIフレーム生成、改良されたレイトレーシング性
あわせて読みたい
【2026年】AI画像生成に最適なGPU比較:RTX4060~5090【SD/LoRA/ControlNet対応】 画像生成AIを使いたい!GPUは何を選べばいい? Stable DiffusionやComfyUIで画像生成に挑戦したい――そう思ったとき、最初に立ちはだかる壁が「GPU選び」ではないでしょ…
Blackwellアーキテクチャの主要ポイント(GB202 GPU)
電化製品あるあるですが、そもそもBlackwell?アーキテクチャの時点で思考が停止してしまう私です。
Blackwellとは一体・・・?
電力効率が上がって、AI処理が早くなった事で画像処理において、どれ程のスピードアップと省電力が見込めるのか?ゆっくりと見ていきましょう。
アーキテクチャは…コンピューターやシステムの「設計思想・構造」を指す言葉で、特にハードウェアやソフトウェアの基本構成や動作の仕組みを指します。
アーキテクチャ
ハードウェアのアーキテクチャ
- CPUやGPUなどの設計方式(例:Intelの「x86」や、Appleの「ARM」、NVIDIAの「Blackwell」)
- 命令セット、演算処理の仕組み、キャッシュの構造、パイプライン方式などが含まれる。
ソフトウェアのアーキテクチャ
- アプリケーションやシステム全体の構成(例:MVCモデル、マイクロサービス、クライアントサーバー構造など)
- モジュール間の関係、通信の流れ、データの扱い方などが決まっています。
「アーキテクチャ=中身の設計図」のようなものであり、
同じ「GPU」でも、アーキテクチャが違えば性能や特徴も大きく変わります。
Blackwell(GB202 GPU)アーキテクチャ何がすごいのか?
これは、前世代の「Hopper(H100)」や「Ada Lovelace(RTX 40シリーズ)」の後継にあたりますが、その威力の差はいかほどなのでしょうか?
因みに、NVIDIAは、アーキテクチャに有名な科学者や技術者の名前をつける傾向があるようです。
- 「Turing」 → アラン・チューリング(計算理論の父)
、Quadro RTX 6000 / 8000Quadroなどのアーキテクチャ - 「Ampere」 → アンペール(電流の単位の由来)
、RTX A6000、NVIDIA A100などのアーキテクチャ - 「Hopper」 → グレース・ホッパー(コンピュータ科学の先駆者)
、NVIDIA GH200などのアーキテクチャ
その流れで「Blackwell」もおそらく歴史的な人物に由来していると考えられます。
「Blackwell」アーキテクチャは、Ada Lovelaceと比べて、大規模AI処理に最適化されており、より効率的な演算が可能だと公式ページでも書かれているとおり、
画像生成AIだけでなく、動画処理や3Dレンダリングにも強く、プロクリエイターの新しい標準になり得る設計だと思いますが、果たしてその中身は・・・
1.MCM構造(Multi-Chip Module)を採用
MCM構造(Multi-Chip Module)とは?
NVIDIAのBlackwell「GB100」では、**2つのGPUチップ(Compute Die)**を1つにまとめています。(GeForce RTX5090は「GB202」 )
MCM構造「GB202」の基本
MCM構造とは、複数のチップ(ダイ)を1つのパッケージに統合する技術です。RTX 5090では、このMCM構造により従来のモノリシック(単一チップ)設計から大きく進化しています。
- コア部分とメモリI/O部分を分離して最適化
- 製造効率・歩留まりの向上(高性能チップの生産がしやすくなる)
- 消費電力あたりのパフォーマンスが向上
画像生成におけるメリット
1. CUDAコア数の増加による高速化
- MCM構造でより多くのCUDAコアを搭載可能になるため、Stable DiffusionやStyleGANなどの推論・生成処理がより高速になります。
- 例:同じ512×512サイズの画像を生成する場合、生成時間が数秒単位で短縮される。
2. VRAM帯域の強化
- GB202はGDDR7メモリと組み合わせ、より広いメモリ帯域幅に。
- これにより、高解像度画像やバッチ生成時でもVRAMのボトルネックが軽減される。
※解像度が高い(例:4K、8Kなど)画像ほど、扱うピクセル数が多くなり、より多くのメモリ(VRAM)を消費します。「バッチ生成」とは、一度に複数の画像やデータを同時に(1枚ずつではなく「5枚まとめて生成する」など)処理・生成することです。その際、VRAM(GPUのメモリ)が足りないと、処理が途中で止まったり、極端に遅くなったりします。これが「ボトルネック(=足かせ、制限)」です。
VRAM帯域の強化により、VRAMの効率的な使い方(新アーキテクチャによる最適化)が出来るという意味です。
3. 分割されたチップでAI処理効率UP
- AI向け演算(TensorコアやRTコア)を専用チップに割り当てる設計が可能になり、AI処理の最適化が進むと考えられます。
- 特にLoRAなどの軽量ファインチューニングやオンデバイスのトレーニング処理でも高い効果を発揮するでしょう。
4. 発熱と消費電力の効率化
長時間のバッチ生成や動画用フレーム生成にも安定して対応できると期待されます。
MCMにより熱分散がしやすくなり、クロック上限を引き上げられる可能性があるため、発熱に強い構成。
※チップが1つの塊ではなく分散しているため、熱が一箇所に集中しにくくなり、熱の集中(ホットスポット)を避けることで、冷却がしやすくなり、安定性や寿命も向上すると考えられている。
Logic「クロック上限を引き上げられる」という理屈です。クロック(GHz)が高くなれば、それだけ1秒あたりにこなせる仕事量が増えます。
AIや高解像度画像生成などの負荷が高い処理では、GPUがフル稼働します。このとき、数百ワット(場合によっては1,000W超え)の熱が発生するのですが、温度が上がりすぎると…自動でクロックが下がる(性能ダウン)システムが不安定になる
2.第2世代Transformer Engine
- 「第2世代Transformer Engine」は、特にLLM(大規模言語モデル)や生成AIなど、最新のAIワークロードに最適化。において、計算速度の向上・省メモリ・高精度な演算を可能にする特殊な演算ユニットです。
- FP8/INT8精度に対応し、推論速度や学習効率が大幅に向上かつ省電力でのAI処理が可能。
- AI画像生成・音声合成・自然言語処理などで高速かつ省電力。
第2世代 Transformer Engine の特徴と効果
| 項目 | 内容 |
|---|---|
| 精度を自動調整(FP8対応) | 精度と速度のバランスをとるため、FP8(8ビット浮動小数点数)を利用。第2世代では、より柔軟にFP8と他の精度(FP16やBF16)を使い分けることで、最大2倍以上のAI計算効率を実現。 |
| 演算最適化 | LLMの「Attention」や「MLP」層に特化した行列演算の高速化アルゴリズムを搭載。 Transformer構造の処理に必要な演算をより少ないサイクルで完了。 |
| メモリ使用量の削減 | FP8によってメモリ使用量が従来の半分以下になり、大規模モデルの学習・推論時の負荷が大幅に軽減される。 |
| より高いモデル精度を維持 | FP8でも高精度を維持するために、スケーリングや再正規化技術を使って精度劣化を防止。第2世代ではこの精度保持性能がさらに進化。 |
| ハードウェアアクセラレーション | NVIDIAのTensor Core内にTransformer専用回路が追加され、従来よりも大規模モデルに対する処理効率が劇的に向上。 |
どんな恩恵があるのか?
- より大きなLLMを、より少ない電力・時間で学習・推論できる
- ChatGPTのような応答型AIの応答速度・精度が向上
- NVIDIA H100やBlackwell(B100, GB100)などのAI特化GPUで真価を発揮
約4倍の効率で処理でき、低コストかつ高速に推論可能。
FP8演算とTransformerの関係は、AIモデルの「高速化」と「効率化」を根本から支える重要な技術です。
FP8(8-bit Floating Point)は、従来のFP16(16ビット浮動小数点数)よりも数値の表現範囲は狭いが、計算量が少なく、メモリも少なくて済むデータ形式で、GPUメモリをより節約しながら高速に演算できるのが大きなメリット。
精度を保ちながら高速化(FP8でも精度落ちなし)
NVIDIAの発表資料によると、FP8演算を使ってもBERT・GPT系の精度はFP16と同等。第2世代では、
- 量子化スケーリング
- 正規化の再調整
- 精度損失の検出と補正
といった技術で、「速さと正確さの両立」が可能になっています。
Transformerベースの大規模モデルでは、以下のような状況になります
- FP32(高精度)→ FP16(高速)→ FP8(超高速+効率)
AI推論時にメモリ消費と計算負荷を抑えつつ、十分な精度を確保。
3.第4世代RT(レイトレーシング)コア・第5世代Tensorコア
RTコアは、リアルタイムでの光の挙動(反射・屈折・影など)を物理ベースで計算するための専用ハードウェアです。
第4世代RTコア → レイトレーシング性能が向上し、より現実的な光の反射・影・屈折をリアルタイムで描画。
画像生成への影響
- よりリアルで高精度なライティングやシャドウ処理が可能に!
- Stable Diffusionや3D生成ツール(例:Blender、NVIDIA Omniverse)で、
- 背景のライティング
- マテリアルの質感
- 照明下の立体表現が自然に再現される
- リアルタイムプレビューを強化し、作業効率がアップ
Tensorコアは、AI処理(特にディープラーニング)向けに最適化された行列演算用ユニットです。
第5世代Tensorコア →DLSS 4(Deep Learning Super Sampling)に対応し、高画質と高FPSを両立。
画像生成への影響
- Stable Diffusion、DALL·E、Midjourneyなどの推論速度が高速化
- 特にFP8/FP16など低精度演算に対応し、消費電力を抑えつつ高速処理
- 超解像(画像の高画質化)、ノイズ除去、顔修正(CodeFormer など)も高速化
- ONNX/TensorRT最適化モデルの動作が軽くなる
結論:生成速度の向上による具体的な数値
Blackwellアーキテクチャは、特に大規模な生成AIモデルにおいて、前世代のH100と比較して最大30倍の速度向上を実現。
コストとエネルギー消費を最大 25 倍削減します。
情報元:NVIDIA米国時間 2024年 3 月 18日に発表されたプレスリリースの抄訳
CUDAコア数:21,760
CUDAコア数「21,760」というのは、NVIDIA GPUにおいて、並列処理に使われる計算ユニットの数を表しています。
GB202 GPUのフルスペック:24,576 CUDAコア
これは、GB202チップが持つ最大のCUDAコア数で、192のストリーミングマルチプロセッサ(SM)に各128コアが搭載されているようです。
GeForce RTX 5090の仕様:21,760 CUDAコア
RTX 5090では、製品化の際に一部のSMが無効化されており、結果としてCUDAコア数が21,760となっているとの記載がありました。
CUDAコア(Compute Unified Device Architecture core)は、
NVIDIA独自の 汎用GPU並列演算用プロセッサの最小単位 です。
※前世代のRTX 4090ではCUDAコア数は「16,384」。
- 通常のCPUでは4〜16コア程度なのに対し、
- GPUは数千〜数万個の小さな「CUDAコア」を搭載しています。
- 各CUDAコアが、画像処理やAI演算、ゲーム描画などの単純な処理を※並列で一斉に実行します。
この数値は、現在のGPUの中でも非常に高密度で、次のような処理性能を持ちます。
イメージ
- CPU(8コア):8人で重たい本を順番に読んでコピーする。
- GPU(21,760コア):21,760人が同時に1ページずつ読んでコピーする。
GDDR7メモリ:次世代メモリが本気を出してきた?
GDDR7 × 512bit × 約32Gbpsという数字を聞いてもピンきません。
でも、これは言うなれば「巨大なデータを、秒速でさばく」ためのハイウェイのようなもの。
しかも、その帯域幅は2000GB/s超(理論値)。これは、RTX 4090の約1.5倍以上のスピード感です。
又、GDDR7+512ビットバス構成は、GDDR6X時代から帯域幅が最大2倍近くに進化しています。
| 項目 | 従来(RTX 4090など) | 新世代(例:RTX 5090) |
|---|---|---|
| メモリ規格 | GDDR6X(21Gbps前後) | GDDR7(最大32Gbps以上) |
| メモリ容量 | 24GB | 32GB(約33%増) |
| メモリバス幅 | 384ビット | 512ビット(帯域幅アップ) |
実質的な違い(帯域幅の増加)
バス幅 × メモリクロック速度 = メモリ帯域幅(GB/s)
- RTX 4090(GDDR6X / 384bit / 約21Gbps)
→ メモリ帯域:約1,008 GB/s - RTX 5090(GDDR7 / 512bit / 約32Gbpsと仮定)
→ メモリ帯域:約2,048 GB/s
▶ つまり、「容量(32GB)」自体はHPCやAI用GPUと比べればそこまで多く見えないが、帯域幅が倍近くになり、データ転送速度が飛躍的に高速化。
進化
- 高解像度(4K/8K)でのゲーミングに有利
- 複雑な3Dモデルやレイトレーシングの処理効率がアップ
- 軽量なAI処理や画像生成タスクにも対応力向上
- より大きなバッファが確保でき、動画編集やマルチアプリ運用に強い
GDDR7+512ビットバス構成は、GDDR6X時代から帯域幅が最大2倍近くに進化しており、ゲーミングからクリエイティブ用途まで体感的なパフォーマンスの底上げされました。
一方で、AI・科学技術分野での処理を重視する場合は、やはりHBM搭載GPU(例:GB100系)の方が圧倒的に有利です。GB100(例:NVIDIA B100)についてはこちらをクリック!
HBM = High Bandwidth Memory(高帯域幅メモリ)
高速かつ大容量なメモリを搭載し、生成AIや大規模データ解析に対応。遅延が非常に少なく、処理効率が高い
| 項目 | GB202(例:RTX 5090) | GB100(例:NVIDIA B100) |
|---|---|---|
| 用途 | コンシューマ向け (ゲーミング/クリエイティブ) | AI/科学技術/大規模LLM向け |
| アーキテクチャ | Blackwell | Blackwell |
| メモリ規格 | GDDR7(最大32GB予定) | HBM3e(最大192GB) |
| メモリ帯域 | 高速(例:最大1.5TB/s程度) | 超高速(最大4.8TB/s以上) |
| MCM構造 | 採用(ただし構成は単純化) | 採用(高密度AI計算向け) |
- HBMメモリは高密度・高帯域だが、非常に高価で発熱管理も難しいため、一般消費者向けGPU(RTXシリーズなど)には採用されないのが通例です。
- 一方、**GDDRメモリ(GDDR7など)**は価格と性能のバランスが良く、ゲーミングやクリエイティブ用途には最適です。
「最大192GB」とはどれほどの大容量か?
| 比較対象 | メモリ容量の目安 |
|---|---|
| 一般的なゲーミングGPU(RTX 4090) | 24GB GDDR6X |
| プロ向けAI開発用GPU(A100など) | 40〜80GB HBM2 |
| 最新のGB100(Blackwell世代) | 最大192GB HBM3e |
▶ 192GB HBM3eは、
- 画像生成AIで数千万画素の画像を一括処理可能
- GPT-4クラスの大規模言語モデルでもオンメモリ推論が可能
- 巨大な3Dシーン、複数モデル同時学習などにも対応
GB202(GeForce RTX 5090など)にはHBM3eは搭載されておらず、GDDR7が使われます。
HBM3e対応は、AI専用のGB100/B100などに限られます。
メモリ帯域幅:1.8 TB/s
メモリ帯域幅「1.8 TB/s(テラバイト毎秒)」というのは、GPUが一秒間に1.8テラバイトものデータをメモリから読み書きできる能力を意味します。クリエイティブ用途やAI生成などにおいて以下のような大きなメリットをもたらします
高解像度画像・動画の処理がスムーズに
大量のピクセルデータやテクスチャを一気に処理できるため、8Kや16Kなどの高解像度素材でもリアルタイムに近い編集・生成が可能になります。
AI生成(画像・動画・音声・テキスト)の高速化
AIモデル(特にStable DiffusionやRunwayなどの生成系ツール)は、大量の重みデータやテンソル演算結果をメモリ間で高速にやり取りする必要があります。
- メモリ帯域が広い → 推論速度が速くなる
- データの転送ボトルネックが減る → 生成処理の安定性や画質も向上
3Dレンダリングやレイトレーシングの性能向上
リアルタイムレイトレーシングでは、光線の追跡やシェーディング処理に膨大なデータ転送が必要になります。帯域が広ければ、複雑な3Dシーンもスムーズに描画可能です。
複数モデル同時処理やVR/AR用途にも有利
複数の画像生成AIやゲーム・配信・編集ツールを同時に動かす場合、帯域が狭いとボトルネックになります。1.8TB/sあれば、マルチタスクにも余裕が生まれます。
インターフェース:PCIe 5.0 x16
インターフェース「PCIe 5.0 x16」は、GPUとCPU(またはメインメモリ)とのデータのやり取りを行う通路(バス)の規格です。画像生成においては、以下のようなメリットをもたらします。
PCIe 5.0 x16 の主な特徴
前世代(PCIe 4.0)の 約2倍の転送速度
画像生成におけるメリット
テクスチャやモデルの転送が高速に
画像生成AI(例:Stable Diffusion)は、GPUに重いモデルデータや画像素材を送って演算させます。
- PCIe 5.0ならこの転送が速いため、ロード時間や推論の前処理が短縮されます。
- 特に 大規模モデル(LoRA、ControlNet併用)や複数画像の同時生成時に有利。
VRAM不足時の「メインメモリ⇔GPUメモリ」補助がスムーズ
VRAM(GPUメモリ)が足りない場合、一部データはシステムメモリから補完します(通称「仮想VRAM」)。
- 通常これが遅くなる原因ですが、PCIe 5.0では帯域が広いため、この補完速度も大幅アップ。
- → 大きな画像や高精細な生成がしやすくなる
AI画像生成+配信・編集などの同時作業に強い
GPUが複数タスク(生成・録画・ストリーミング・編集)を担う場面でも、PCIe 5.0はデータの通行渋滞を防ぎます。
- 生成しながらプレビュー編集、YouTubeライブ配信などもスムーズですね。
PCIe 5.0 x16 の恩恵が大きいケース
| ユースケース | PCIe 5.0の効果 |
|---|---|
| 重いAIモデルの画像生成 | モデル転送が速くなり、全体が軽快に |
| VRAM不足時 | メモリ補完でも遅延が少ない |
| 複数ツールの同時使用 | GPUデータ転送の渋滞を回避 |
| 高解像度・動画AI生成 | 帯域の広さが安定性に寄与 |
PCIe 5.0 x16は「画像生成をより安定・高速に行いたい人」にとって理想的な環境です。
特にStable Diffusionなどの高負荷処理をしている場合、その違いを体感できます。
TDP(消費電力):575W
TDP(熱設計電力)575Wは、「消費電力=最大575ワット程度の熱を出す=おおよそ575Wの電気を食う可能性がある」ことを意味します。これを家庭用の電化製品で例えると、以下のような感じです
消費電力575Wの家電製品の例
| 家電 | 消費電力の目安 | イメージ |
|---|---|---|
| ドライヤー(中~強風) | 約600W前後 | 風量を少し絞った状態 |
| 電子レンジ(弱~中) | 約500〜700W | 解凍モードや温め程度 |
| ノートPC(高負荷) | 約60〜120W | 約5〜10台分の電力 |
| 電気ストーブ(中) | 約400〜600W | 小型の暖房器具と同等 |
※電気代は「1kWh = 31円」で試算(2024年の全国平均)
| 使用状況 | 消費電力 | 電気代(1時間あたり) |
|---|---|---|
| 軽い使用(アイドル〜軽作業) | 約100〜150W | 約3.1〜4.6円 |
| ゲーム・AI生成(中負荷) | 約300〜400W | 約9.3〜12.4円 |
| 高負荷(AI学習・4Kゲームなど) | 約500〜600W | 約15.5〜18.6円 |
構成ごとの消費電力目安(概算)
| パーツ | 消費電力の目安 |
|---|---|
| GPU(ハイエンド) | 500W |
| CPU(高性能) | 100~150W |
| マザーボード | 50W前後 |
| メモリ(32GB程度) | 10~15W |
| ストレージ(SSD/HDD) | 10~30W(複数台なら増加) |
| 冷却ファン・水冷 | 10~30W |
| その他(USB機器など) | 10~20W |
PC全体での電気代(RTX5090搭載)
| シーン | 合計消費電力(推定) | 電気代(1時間) |
|---|---|---|
| 中負荷(ゲームなど) | 約600〜700W | 約18.6〜21.7円 |
| 高負荷(AI生成など) | 約800〜900W | 約24.8〜27.9円 |
電源ユニット(PSU)の推奨容量
消費電力に30〜50%の余裕を持たせるのが理想
例:消費電力が800W → 1000W~1200Wの電源が安全
1日3時間 × 30日間使用した場合
電気代の目安 例:高負荷作業で1日3時間 × 月30日 = 月90時間使用 900W×90時間=81kWh→81×31円=2,511円/月
電源ユニットの選定にも注意
RTX 5090クラスでは、1000W〜1200Wの電源が推奨される可能性が高いです。
電力効率(80PLUS Gold以上)も電気代節約には重要です。
散々、高速かつ省電力と謳われていたので転倒しそうですが、さすがにそうか・・・。

 未来
未来魅力的だけど慎重に考える必要がありそうだね・・・
SAKASA AI
画像生成やLoRA学習を行うクリエイター向け、最適な冷却構成と空冷・水冷の選び方まとめ | SAKASA AI GPUは「電気 → 処理」に変えると同時に「熱」を生みます。 AIや高解像度画像生成などの負荷が高い処理では、GPUがフル稼働します。このとき、**数百ワット(場合によっては…
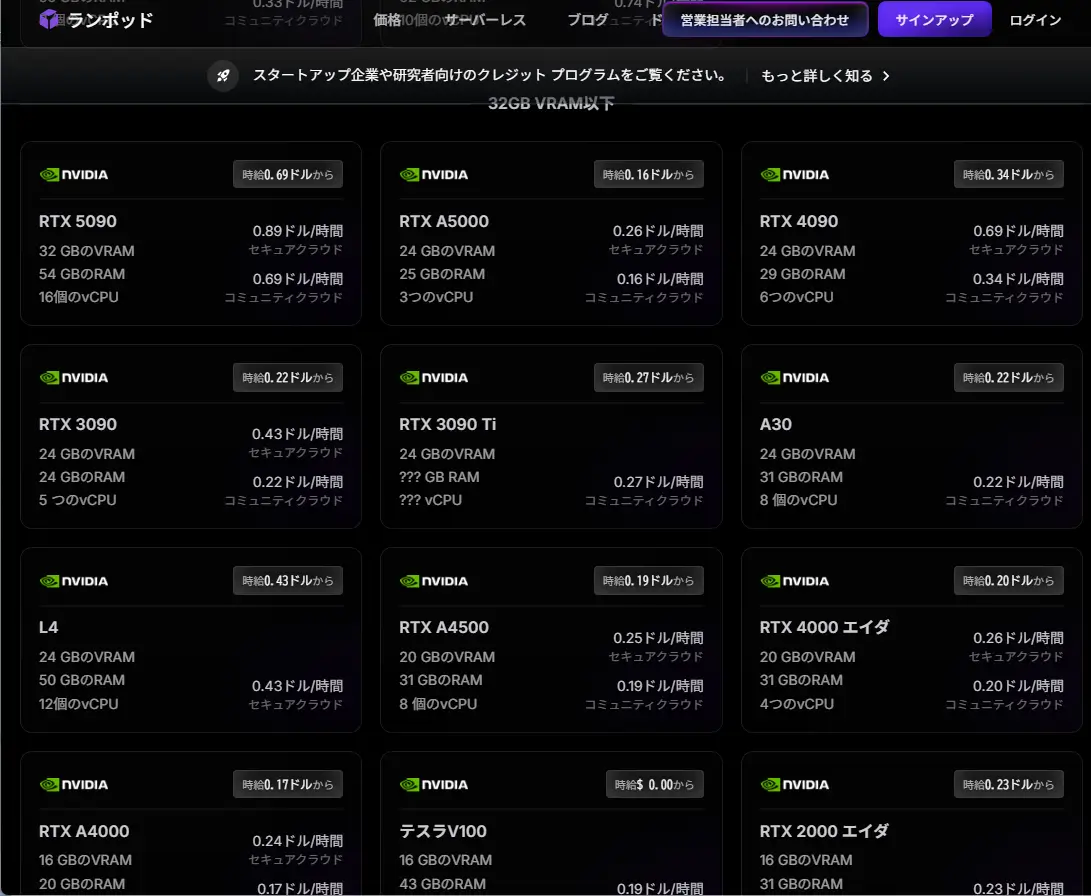
RTX 5090を、1時間0.69円~で格安レンタル”で一旦使ってみる!
ここまで読んでいただきありがとうございました。
ここからは 5090を「クラウド」で、たった1時間あたり約0.69ドル(約110円)〜のコストで使える方法について。(電気代だけで一時間約24.8〜円の機能なのに!)(※残念ながら熱風の体感は得られませんが…)
それが、GPUクラウドサービスの「RunPod」です。
高額なGPUを買わなくても、最新のGPU環境が今すぐ手に入ります。しかも、使った分だけの従量課金なので、電気代すら気にせず試せます。
実際に私も使ってみて、その快適さに驚きました。(生成速度が早い。)
画像生成AIや動画編集、LoRA学習にもぴったりなRunPodの使い方や始め方は、こちらの記事で詳しく紹介しています是非、色々と試してみて下さい。
あわせて読みたい
クラウドGPU”RunPod”とは?画像生成・LoRA学習の最適解?!個人利用の効率よいクラウド環境【①解説編】 ComfyUI、Stable Diffusionなどの画像生成も使いやすい Stable Diffusionで「思う存分、画像,動画生成がしたい」「自分の作風を学習させたい」「LoRAやDreamBoothを試し…
アイディアが浮かんだ瞬間に、もう作品が仕上がっている。そんなテンポ感で創作できるのは魅力的ですが
自宅PCにはむずかしいかな・・・。
GPU比較についてはこちらの記事もご覧ください。
あわせて読みたい
【2026年】AI画像生成に最適なGPU比較:RTX4060~5090【SD/LoRA/ControlNet対応】 画像生成AIを使いたい!GPUは何を選べばいい? Stable DiffusionやComfyUIで画像生成に挑戦したい――そう思ったとき、最初に立ちはだかる壁が「GPU選び」ではないでしょ…
 SAKASA
SAKASAその熱風と騒音にさえ憧れるよね。
まとめ
GeForce RTX 5090は、第2世代Transformer EngineとFP8演算に対応し、生成AI(画像・動画・テキストなど)の高速処理に優れる。GDDR7による広帯域メモリも搭載し、個人〜小規模プロジェクトに最適。ただし、超大規模モデルにはHBM搭載のGB100系がより適しているようです。
あわせて読みたい
Pythonで画像生成を始める方法~Pythonの基礎からインストールまで~ Python(パイソン)とは Python(パイソン)とは、1991年にオランダのプログラマ、グイド・ヴァンロッサム氏によって開発された、汎用の高水準プログラミング言語です。…