ComfyUIとは?Stable Diffusion 各モデルの特徴・用途・対応ツールのインストールと使い方

ComfyUIの使い方
Stable Diffusionの代表的WebUI「AUTOMATIC1111」に続き、InvokeAIやForgeも人気が急上昇。
しかし、最も高機能なツールとして注目されるのは、自由自在にカスタマイズできるComfyUIですね。
 未来
未来ComfyUIは、“ノード”をつないで自由にワークフローを組めるのが最大の特徴です。
目次
ComfyUIの主な特徴
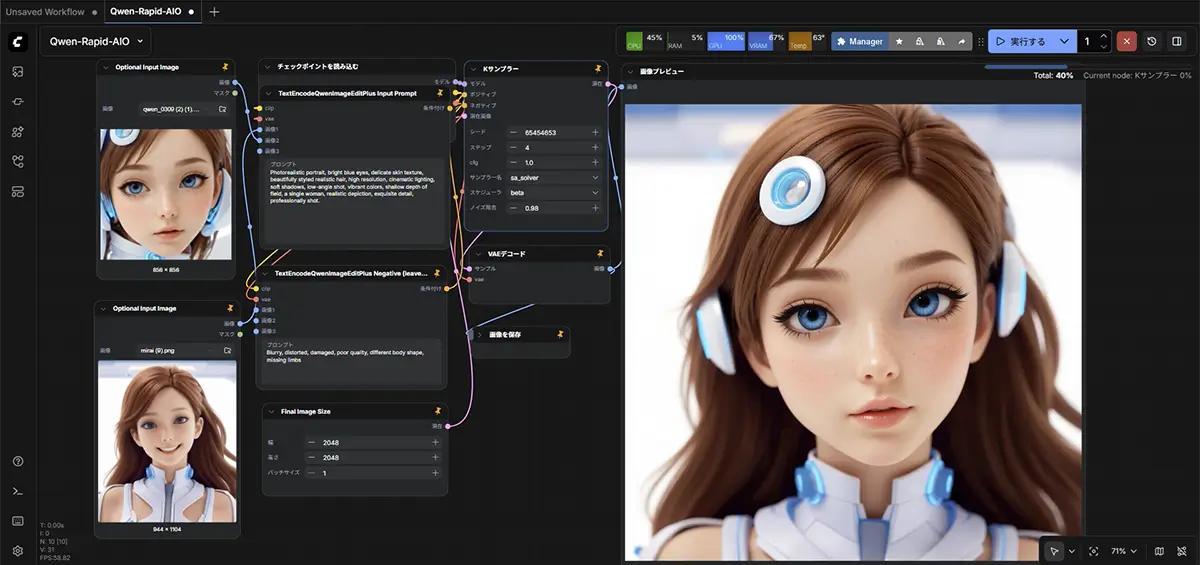
ComfyUIはStable Diffusion モデルを「どう動かすか」をノードベースで組み立てられるツールです。
2024年10月から、2025年8月にかけて大幅アップデートが次々に行われUIデザインも一新され、とても使いやすくなりました。
起動時に用途別のテンプレートを選択するだけで、必要なモデルは自動でダウンロードを促してくれるため、初心者でもすぐに画像生成を始められます。
これまでComfyUIは柔軟性が高い反面、初心者には敷居が高いという印象でしたが、
現在ではノードベースの柔軟性を維持しつつ、初心者でも簡単に扱えるツールへと進化しています。
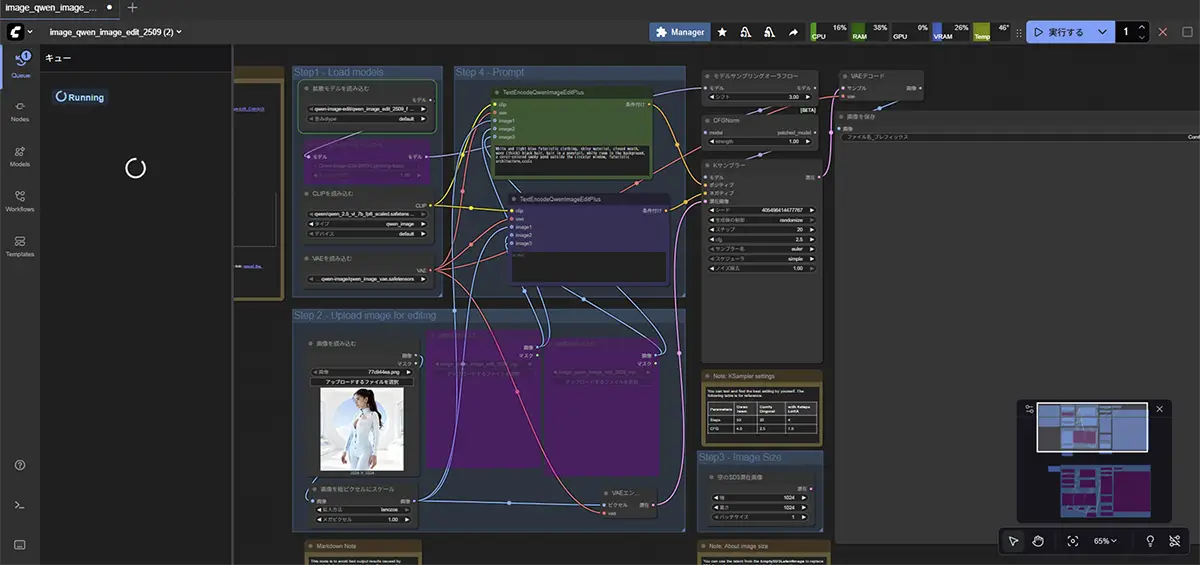
最初は、ややこしく感じるかもしれませんが、慣れると「自由度」と「再現性」が抜群です。
例えば、「SDXLでLoRAを適用して、ControlNetでポーズを指定し、画像を動画に変換」なんて複雑な処理も、1つの画面でまとめて操作できます。
―ノードについての詳しい解説はこちらをCLICK!
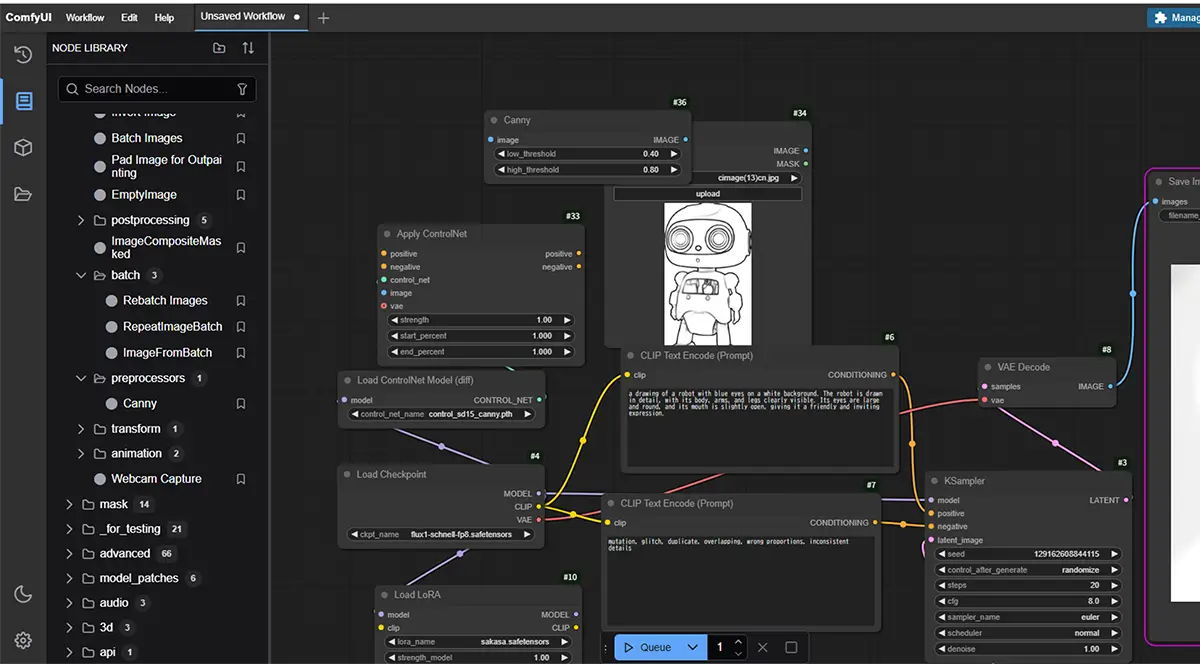
「ノード」とは、画像生成の中で「1つの処理や機能を担うパーツ」のことです。
たとえば、Stable Diffusionの処理にはこんな流れがあります
- モデル(Checkpoint)を読み込む
- テキストをエンコードする(プロンプト処理)
- ノイズから画像を生成する(サンプリング)
- 画像を保存する
この1つ1つが、それぞれ独立した「ノード」として用意されています。
※この上の画像の一つ一つのブロックの事を言います。
ComfyUIではこれらを“ブロック”や“箱”のような形のノードを配置し、線でつなぐことで処理の流れを組み立てるというスタイルを採っています。
基本的なノード(例)
| ノード名 | 機能 |
|---|---|
| Load Checkpoint | モデル(例:SDXL)を読み込む |
| CLIP Text Encode | テキストプロンプトを処理する |
| KSampler | 実際に画像を生成する |
| Save Image | 出力画像を保存する |
ノードを線でつなぐことで、「このモデルを使って、このプロンプトで、画像を作って、保存する」といった一連の流れが形になります。
ノードを使うメリット
- 処理の流れが目に見えてわかる
ブラックボックス感がなく、変更も簡単。 - 一部だけ再利用や差し替えができる
LoRAやVAEだけ変更して生成を比較する事も出来る。 - 複雑な処理を段階的に組める
ControlNetや動画生成のような構成も柔軟に。
ノードは「ブロックのように、必要な機能を組み合わせて自分だけの画像生成パイプラインを作る部品」です。
ComfyUIはこの“ノード式”で作業できるため、創造の自由度が非常に高いのが特徴です。
- ノードベースの自由な構成
生成の流れを細かく制御できる。失敗した箇所だけ再実行できる効率の良さも魅力。 - 高い拡張性
ControlNet、LoRA、Tiled Diffusion、動画生成、動画生成、アップスケーラーなどの機能を追加可能。フォルダに置くだけで導入できる拡張も豊富です。 - モデル学習にも対応
LoRAのトレーニングや出力調整、画像分岐などもノードで管理できるため、AI画像の研究にも向いています。 - 軽量・マルチプラットフォーム
Windows/Mac/Linuxに対応し、Colab上でも動作可能。初回セットアップも比較的かんたんです。
 未来
未来パラメータや処理の流れを視覚的に操作できるので、「生成の仕組みを理解しながら使いたい」という人におすすめです!
ComfyUIとAUTOMATIC1111 WebUIの違い
AUTOMATIC1111 WebUIと比較すると、ComfyUIはUIがコンパクトにまとまっている為、見やすくモデルやワークフローの管理が直感的です。
特に環境構築の面では、テンプレートベースのセットアップにより、AUTOMATIC1111よりも圧倒的にスムーズに始められるようになりました。
ワークフローの再利用性も高く、一度作成した設定を簡単に保存・共有できるため、効率的な作業が可能です。
処理の流れが視覚化されているため、トラブルも対応もしやすく、現在では初心者から上級者まで幅広くおすすめできるツールとなっています。
※最近特におすすめなのが、”WAN”などの動画生成ツールです。
未来現在、当サイトのトップページでもWANで作成した動画を使用していますよ!
ComfyUIの使用方法
必要条件
ComfyUI公式ページシステム要件
ComfyUI自体はGPUがなくてもCPUだけで動く設計であり、ComfyUIの公式の「システム要件」ページには、細かいVRAMやメモリの目安が書かれていませんが、
必要なVRAMやメモリは使用するモデル次第で変わりますので以下は基本的な目安です。
目安:
- 公式では、最低4GBのVRAM、NVIDIA製グラフィックスカードを推奨、RTX3060以上が望ましい
との記載があります。
実際は、GPUメモリ(VRAM)6GB以上 → Stable Diffusion 1.5 系が普通に動作可能 - VRAM 12GB以上 → SDXL や Flux などの大型モデルが快適という印象です。
- 最低8GBのシステムメモリがあるとある程度動く。
画像生成の為のGPU解説
【2026年】AI画像生成におすすめGPU比較:RTX4060~5090【Stable Diffusion・LoRA対応】 画像生成AIを使いたい!GPUは何を選べばいい? Stable DiffusionやComfyUIで画像生成に挑戦したい――そう思ったとき、最初に立ちはだかる壁が「GPU選び」ではないでしょ…
クラウドで使う場合(レンタルGPU)
- GPU性能がクラウド側にあるため、自分のPCが重くならない
- 大容量モデル(SDXL、Fluxなど)も快適に動作(ハイクラスGPUを選択すれば爆速で生成出来る。)
- 必要なときだけ利用できるため、料金は使った分だけ
最初はクラウドGPUで試してみて、
慣れてきたらローカル環境に入れて、自分のペースで使うのもおすすめです。
おすすめクラウドGPU
【RunPodの料金と使い方】Stable Diffusionなどで画像生成やLoRA学習をする方法【②実践編】 RunpodでStable Diffusion系画像生成やLoRA学習をする方法 Stable DiffusionやLoRA学習では、長時間GPUをフル稼働させるため、発熱や電源の安定性が大きな課題になりま…
クラウドGPU比較記事
【2026年版】クラウドGPU比較|RunPod・Colab・Paperspace・Lambda Labsの特徴と選び方 クラウドGPUのニーズと記事の目的 近年、AI生成や3Dモデル作成、機械学習の学習用途などで、高性能GPUの需要が急速に高まっています。個人のPCでは対応が難しい処理も、…
ローカルPCで使う方法
- 自分のPCにComfyUIをインストールして利用する方法です
- 一度セットアップすれば、以降は無料で使える
- ネットに接続せずに作業できるため、データを外に出さずに完結可能
- ただし GPU性能が低いと重い/モデルが動かない こともある
長く使いたい場合や、ネットに依存せず作業したい場合はローカルがおすすめです。
最新バージョンを体験したい場合は、ポータブルバージョンまたは手動インストール推奨です。
※インストール方法は、公式HPで三通り記載されています。
快適なUIデスクトップ(ComfyUI Desktop)のインストール方法
Windows または macOS (Apple Silicon) 向け。
インストーラー形式で提供され、Pythonや依存ライブラリが内蔵されている。
特徴:
アプリケーションなので、コマンド操作なしで起動できる。
- インストーラー付き
- 手軽に使える
- カスタムノードの依存関係で問題が起きやすいので、**ノードを沢山追加したい方**には不向き。
STEP
ダウンロードしたアプリをインストールする
ダウンロードしたインストールパッケージファイルをダブルクリックすると、
デスクトップにComfyUIデスクトップのショートカットが作成されます。
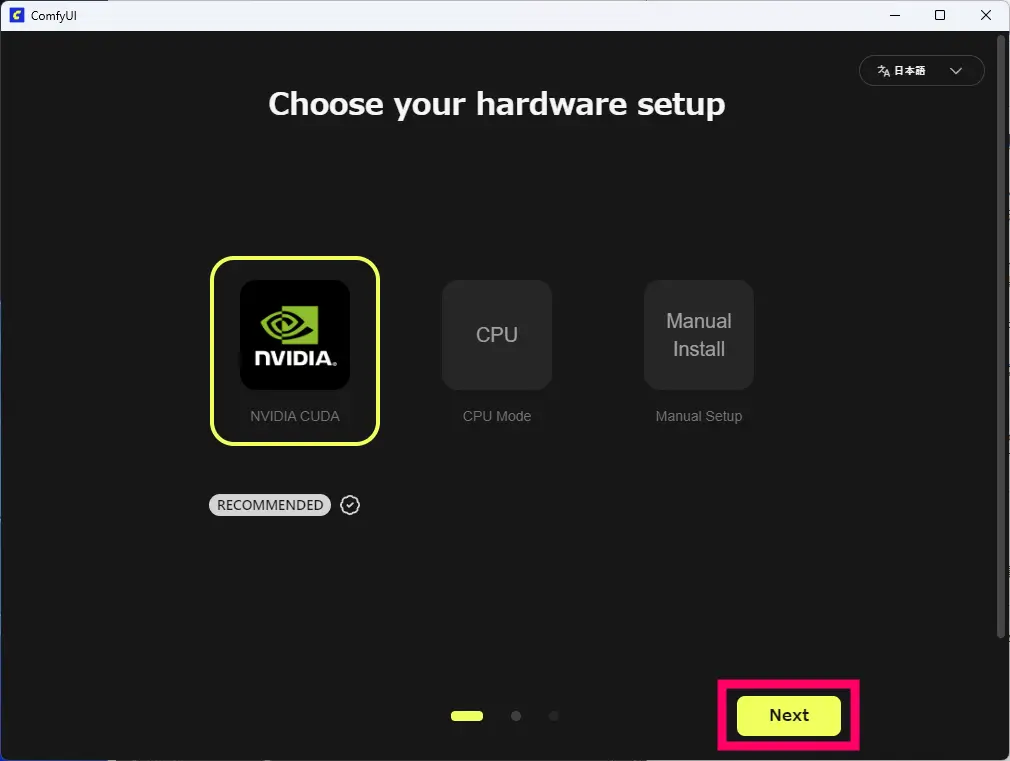
STEP
GPUを選択➡Next
STEP
Install
STEP
インストール先を選択➡Next
ComfyUIのポータブル(Windows)のインストール方法
最新CUDA版で、Windowsの場合は最も簡単で確実な方法です。
- 独自の組み込みPython環境が同梱。
- 特徴:
zipを解凍するだけ- 最新のコミット(開発版)も利用可能。
- 移動や他のPCでの利用も簡単(フォルダごとコピーして実行可能)。
- コマンド操作やPythonインストール不要。
ダウンロードしたzipを解凍すると以下のファイルが入っています。
➡ run_nvidia_gpu.bat 場合によっては、run_cpu_bat で起動します。ComfyUIの手動(GitHub版)インストール方法
手動インストールで、
ComfyUIコードリポジトリをクローンする方法は、こちらの公式ページ内で詳しく解説されています。
【ローカル環境・クラウド環境共通】ComfyUIを起動する
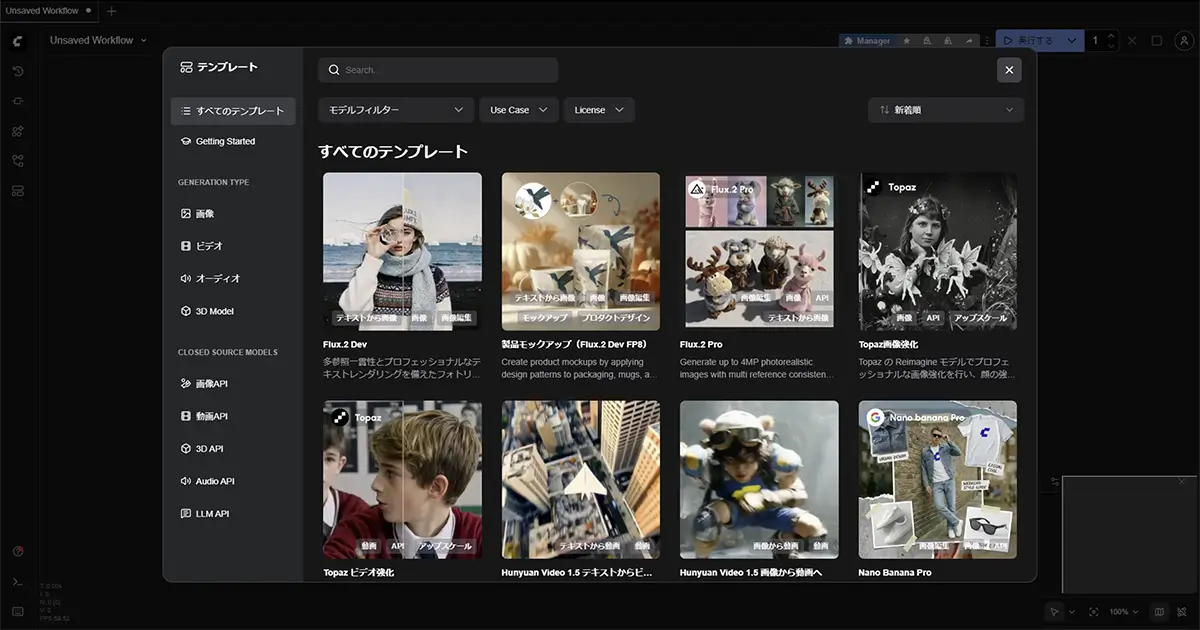
ComfyUIのV1アップデート以降、起動時に左上の「ワークフロー」メニューから様々なテンプレートを選択できるようになりました。テンプレートリストから使用したいテンプレートをクリックすると、システムが自動的に対応するワークフローを読み込み、必要なモデルファイルがインストールされているか確認してくれます。
主なテンプレート一覧
| カテゴリ | テンプレート名 | 用途・特徴 | 初心者向け |
|---|---|---|---|
| 基本生成 | Image Generation | テキストから画像を生成する最もシンプルなテンプレート | ◎ |
| 基本生成 | Simple txt2img | テキストプロンプトから画像を作成する最小構成 | ◎ |
| モデル別 | Flux Dev | FLUX.1モデル用。高品質な画像生成に特化 | ○ |
| モデル別 | Flux Schnell | FLUX.1モデル用。高速生成に特化し、動作確認に最適 | ◎ |
| モデル別 | SDXL | SDXLベースモデル向け。高品質で汎用性が高い | ○ |
| モデル別 | SD1.5 | Stable Diffusion 1.5向けの軽量テンプレート | ◎ |
| 高度な機能 | Image-to-Image | 既存の画像をベースに新しい画像を生成 | ○ |
| 高度な機能 | Upscale | 画像の高解像度化(アップスケール) | ○ |
| 高度な機能 | ControlNet系 | ポーズ指定、線画からの生成など構図をコントロール | △ |
| 高度な機能 | LoRA適用 | スタイルやキャラクター再現用 | △ |
| 動画生成 | Video Generation | テキストや画像から動画を生成 | △ |
| 動画生成 | WAN系 | クラウド環境限定の動画生成ワークフロー | △ |
初心者向け表記: ◎=最適 / ○=おすすめ / △=中級者以上
初心者におすすめのテンプレート
- Image Generation(画像生成) – 最もシンプルで理解しやすい
- Flux Schnell – 高速に結果が得られるため、動作確認に最適
- Simple SDXL – 高品質な画像を手軽に生成できる
これらのテンプレートは、必要なモデルファイルが不足している場合、システムが自動的にダウンロードを促してくれるため、環境構築に悩むことなくすぐに始められます。
テンプレートのカスタマイズと保存
一度作成したノードの組み合わせは、選択した状態で右クリック「Save Selected as Template」から.json形式のファイルとして保存できます。
よく使う設定をテンプレート化しておくと、作業効率が大幅に向上します。
また、OpenArtなどのオンラインプラットフォームでは、コミュニティが作成した多数のワークフローテンプレートが共有されており、自由にダウンロードして使用できます。
モデルを入れる
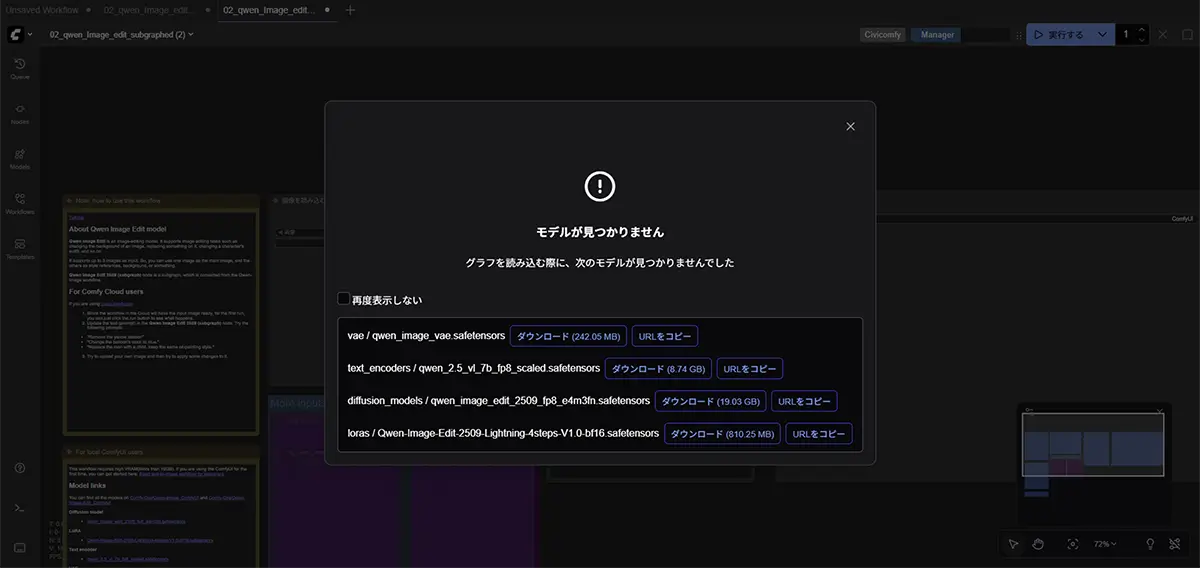
起動時にテンプレートを選択するだけで、すぐに画像生成を始められるようになり、必要なモデルがない場合は自動でダウンロードを促してくれます。
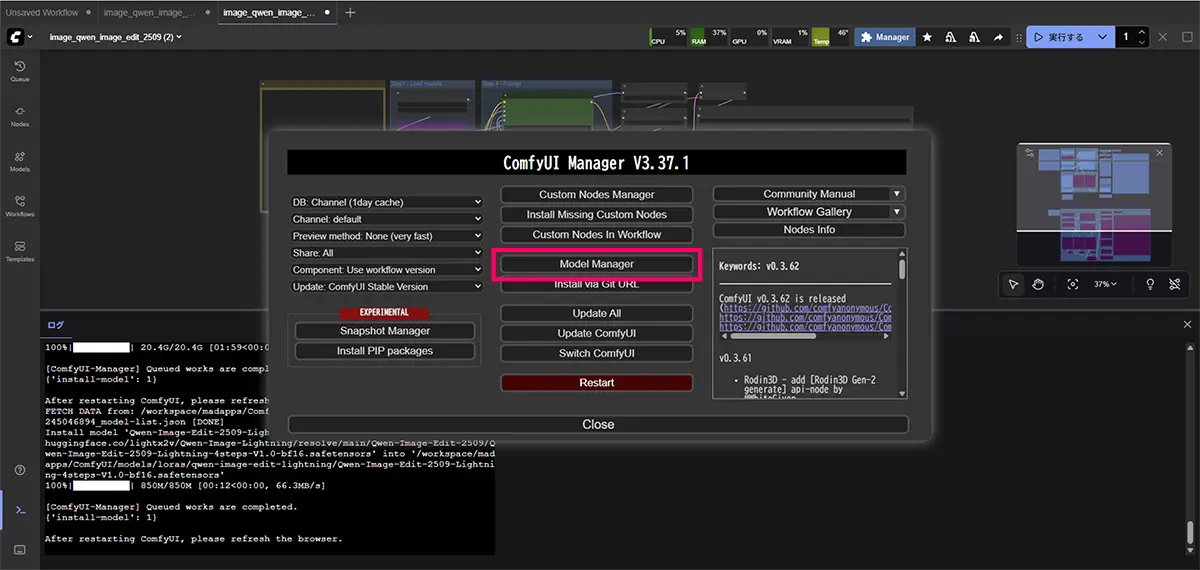
Model Managerに入っていないモデルは、HuggingFaceやCivitaiから直接ダウンロードします。
あわせて読みたい
【2025年版】Civitaiの見方と使い方|LoRA・Checkpointモデルの選び方 本記事では、”AI画像生成用のモデル共有・配布プラットフォーム”「Civitai(シビタイ)」の使い方を、画像生成の目的に合わせて解説します。 引用元:Civitai公式サイト…
SAKASA AI
【別物】ComfyUIで“描き直す”高解像化|Qwen-Image-Edit-Rapid-AIOの使い方と実力 | SAKASA AI ComfyUIでQwen-Image-Rapid AIO(v18)を使い、ディテールを“描き直す”高解像度化の方法を解説。ぼやけた画像をシャープに改善する仕組みや導入手順、向いている用途までわか…
Fluxや一部のSDXL系は、Hugging Face の「認証が必要なモデル」です。認証モデルのダウンロード方法に関しては以下の記事の中で書いています。
SAKASA AI
ComfyUIでFLUXとSDXLを使う方法と認証モデルのダウンロード | SAKASA AI AI画像生成の世界で人気の、SDXL(Stable Diffusion XL)とFLUXが2大人気モデル。最近では、そこに、WANの動画生成のノードも組み込めるようになり(WANはクラウド限定で使…
SAKASA AI
Stable Diffusion 各モデルの特徴・用途・対応ツール【最新版】 | SAKASA AI Stable Diffusion 各モデルの特徴・用途・対応ツール・実行方法と商用利用OKな組み合わせ、商用利用OKのモデルライセンスと注意点などをまとめました。
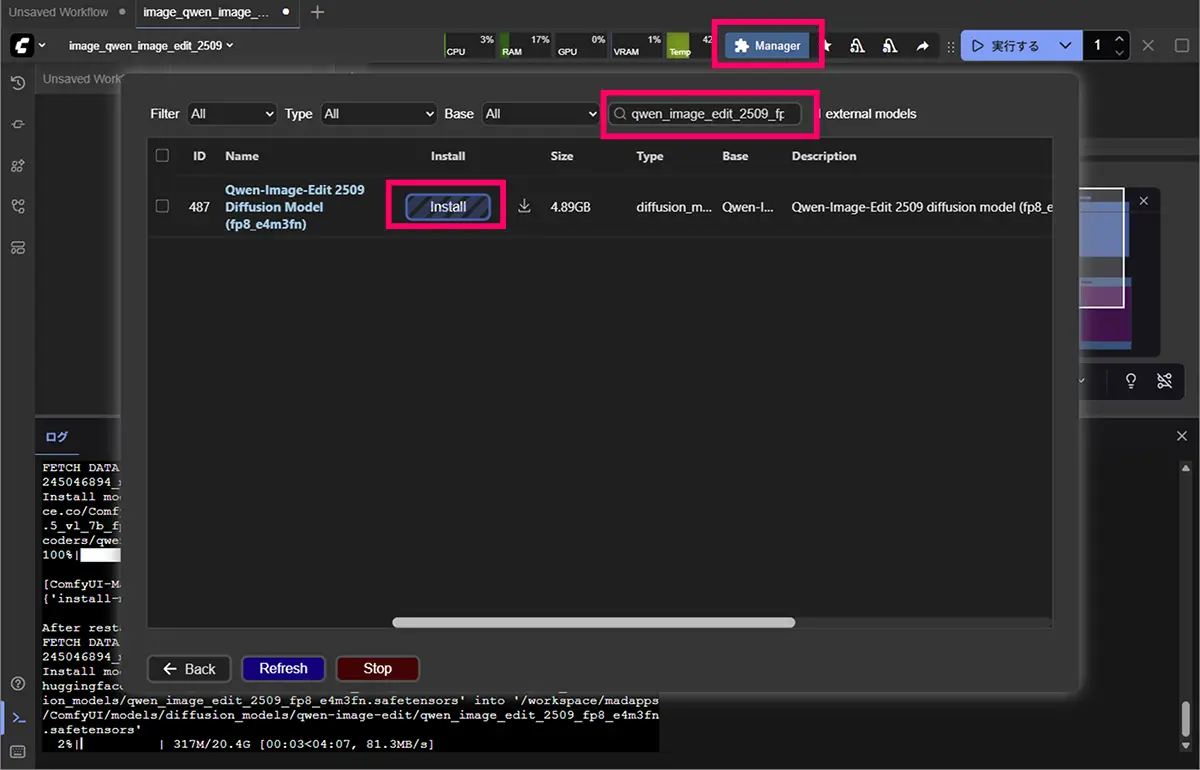
- ComfyUIを立ち上げると、ノードテンプレートが選択できる画面が開く。
- 促されたダウンロードが必要なモデルをチェックする
- ComfyUI画面の上部にある
Manager(マネージャー)を開く - 必要なモデルを選択してダウンロードボタンをクリック!
- UI画面を再起動させる
- ComfyUIを起動すると、ノードからモデルが選べるようになります
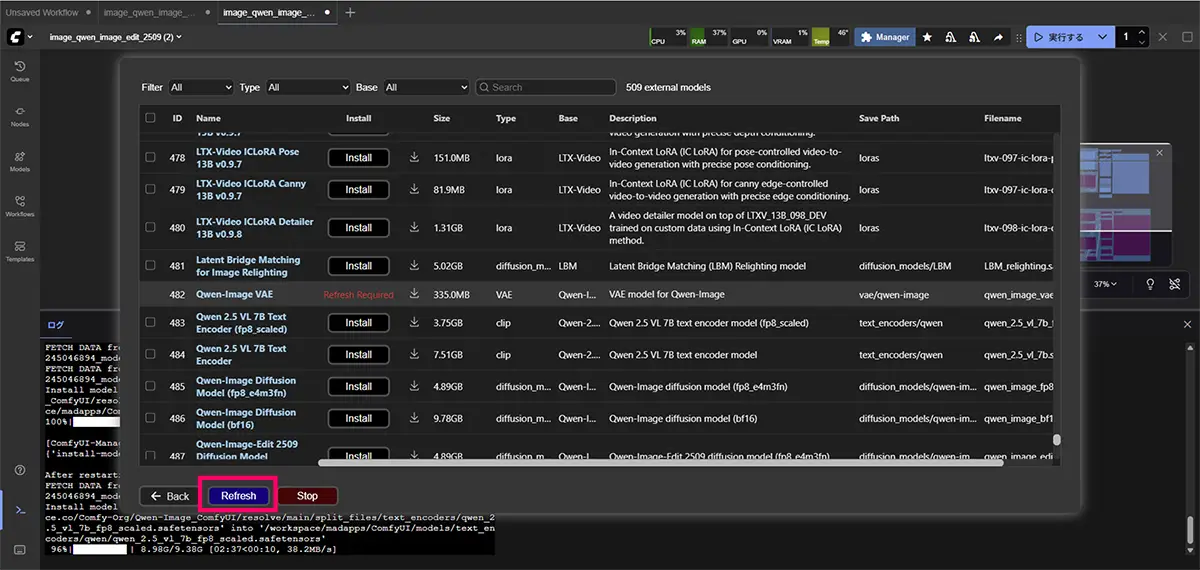
代表的なチェックポイントモデルのサイズ
チェックポイントモデルとは、画像生成をする際に、必ず必要となる”元となるモデル”です。
代表的なモデルのサイズの目安です。
- Flux.1-Schnell → 約 4 GB
- SDXL 1.0 Base → 約 6.6 GB
- SDXL 1.0 Refiner → 約 6.6 GB
- Stable Diffusion 1.5 (pruned-emaonly) → 約 4 GB
- Stable Diffusion 2.1 (768-ema-pruned) → 約 5.2 GB
合計: 4.0 + 6.6 + 6.6 + 4.0 + 5.2 = 26.4 GB
26GB前後になるので、SSDの空き容量は最低30GB以上必要になります。さらに VAE や LoRA を入れると追加で数GB〜数十GB必要になります。
※LoRAモデルなどを使用する場合には、上記のチェックポイントモデルに更に追加して使用します。
ノードの追加方法(ComfyUI)
- UI画面の空いているところで右クリック
→ メニューが出てきます。
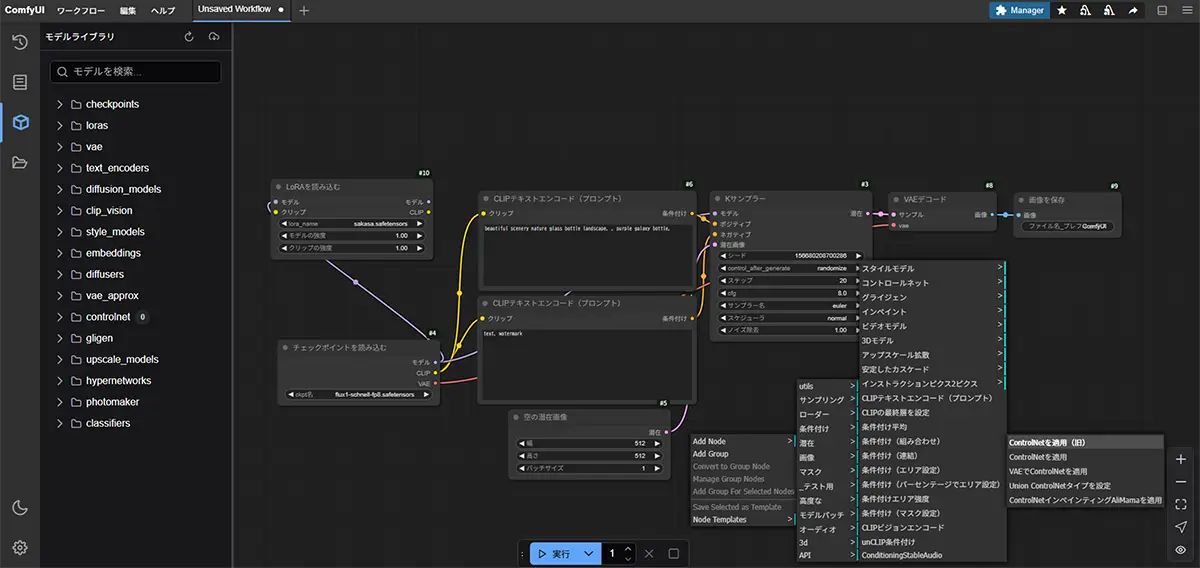
- その中に「Add Node」という項目があります。
search…(検索窓)が開くので、そこに clip と入力するとCLIPTextEncode (Prompt)CLIPTextEncode (Negative Prompt)
が候補に出ます。
設定
解像度を上げる方法
- 生成サイズ が小さいと、細部や顔の描写が荒くなりがちです。
- ComfyUIでの設定例:
Width: 512 → 1024Height: 512 → 1024
- 注意点:VRAM使用量が増えるので、GPUに余裕があるか確認。
ステップ数
- Sampling Steps(ステップ数) が少ないと画像が荒くなることがあります。
- 例:
- 20〜25ステップ → 粗め
- 30〜50ステップ → 高精細
サンプリング方法の変更
- Samplerによって結果のシャープさやディテールが変わります。
- 推奨:
Euler a(標準的で安定)DDIM(滑らかで自然)DPM++ SDE Karras(高画質向き)
CFG Scaleで調整
cfg = 1.5-2.0: 画像の影響が非常に強い
→ ほぼ元画像に近い
cfg = 2.5-3.5: バランス(推奨)
→ 画像とテキストのバランス
cfg = 4.0-6.0: テキスト影響が強い
→ 画像は参考程度Denoiseで調整
denoise = 0.5-0.7: 元画像の特徴を強く維持
→ ControlNet strength 0.9-1.0 相当
denoise = 0.7-0.85: バランス
→ ControlNet strength 0.7-0.8 相当
denoise = 0.85-1.0: 大きく変化
→ ControlNet strength 0.5-0.6 相当高解像度修正(High-Res Fix / Upscale)
- ComfyUIには HiRes Fix ノード や ESRGANノード がある場合があります。
- 流れ:
- 通常解像度で生成
- HiRes Fixで2倍アップスケール
- ディテールを補完
LoRA・モデルの品質も影響
- ベースモデルが荒いと画質改善だけでは限界があります。
- 高精細向けのモデルや、SDXL系モデルを使うと全体の描写がきれいになります。
画像を生成する
Promptノードに任意のプロンプトを入力(例:a cute cat in watercolor)- 画面左で「Load」→
ComfyUI/examples/workflowsにあるプリセットを選択
例:simple.txt ▶ ボタンをクリック- 画像が生成されて表示されます!
ComfyUI でよく使うノード早見表
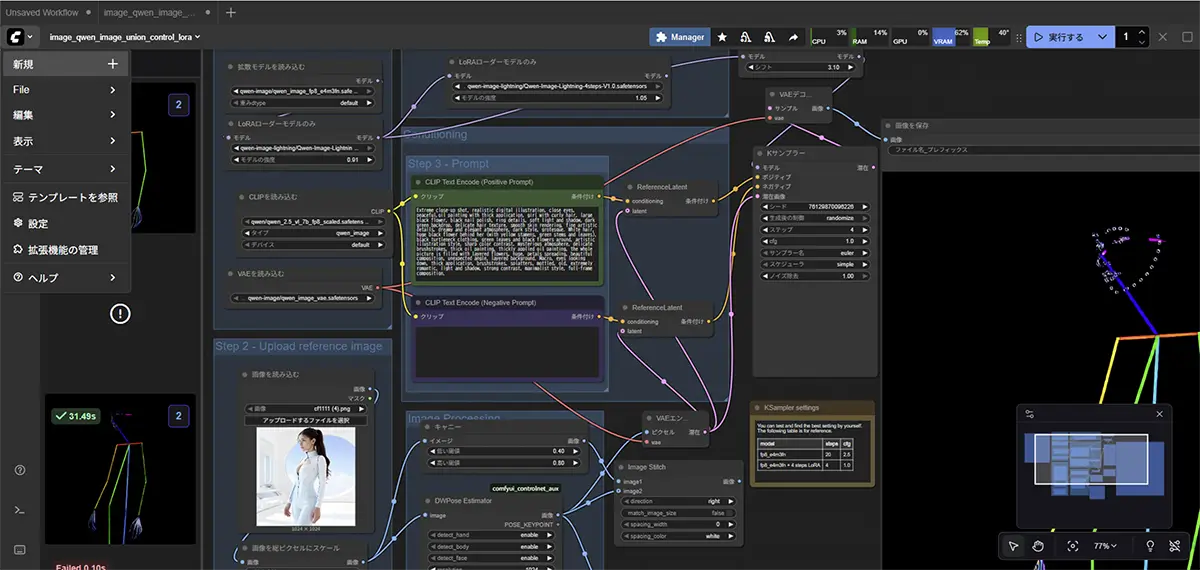
基本ノードセット(最小構成)
最小限のノードで 画像生成をする場合
Stable Diffusionを初めて触る人は、まずこの構成を理解すればOKです。
| ノード名 | 役割 | 補足 |
|---|---|---|
| Load Checkpoint | モデル(SD1.5、SDXLなど)を読み込む | .safetensors / .ckpt を指定 |
| CLIP Text Encode (Prompt) | プロンプトをエンコード | ポジティブプロンプト用 |
| CLIP Text Encode (Negative Prompt) | ネガティブプロンプトをエンコード | ノイズ抑制・不要要素を除外 |
| KSampler | 実際の画像生成を実行 | サンプラー、ステップ、シードを設定 |
| VAE Decode | 潜在画像 → 通常の画像に変換 | モデルによっては自動設定も可 |
| Image Save | 生成画像を保存 | 出力フォルダに保存される |
応用ノードセット(LoRA・ControlNetなど)
応用機能を追加したいときに使うノード。
キャラクターの一貫性やポーズ指定、アップスケールなどが可能になります。
| ノード名 | 役割 | よく使う場面 |
|---|---|---|
| Load LoRA | LoRAファイルを読み込み | 絵柄やキャラクター再現 |
| Apply LoRA | LoRAをテキストエンコード/UNetに適用 | Load LoRA とセットで使用 |
| ControlNet Loader | ControlNetモデルを読み込み | OpenPose、Canny、Depthなど |
| ControlNet Apply | ControlNetをUNetに適用 | 構図や線画を反映 |
| Image Loader | 画像を読み込み | ControlNetの入力用など |
| Preprocessor系(Canny, OpenPose, Depthなど) | 入力画像から線画・骨格・奥行を抽出 | ControlNetの前処理に必須 |
| Upscaleノード(Latent Upscale、ESRGANなど) | 高解像度化 | 512px → 1024px など拡大 |
| Preview / Image Display | プレビュー表示 | ワークフロー途中で確認 |
基本構成にこれらを組み合わせることで、
- LoRAで絵柄指定
- ControlNetでポーズ指定
- アップスケールで高画質化
が可能になり、実用レベルの生成環境が完成します。
【LoRA導入】ComfyUI編
個別にモデルをダウンロードして使用する場合のLoRAモデルの配置場所。
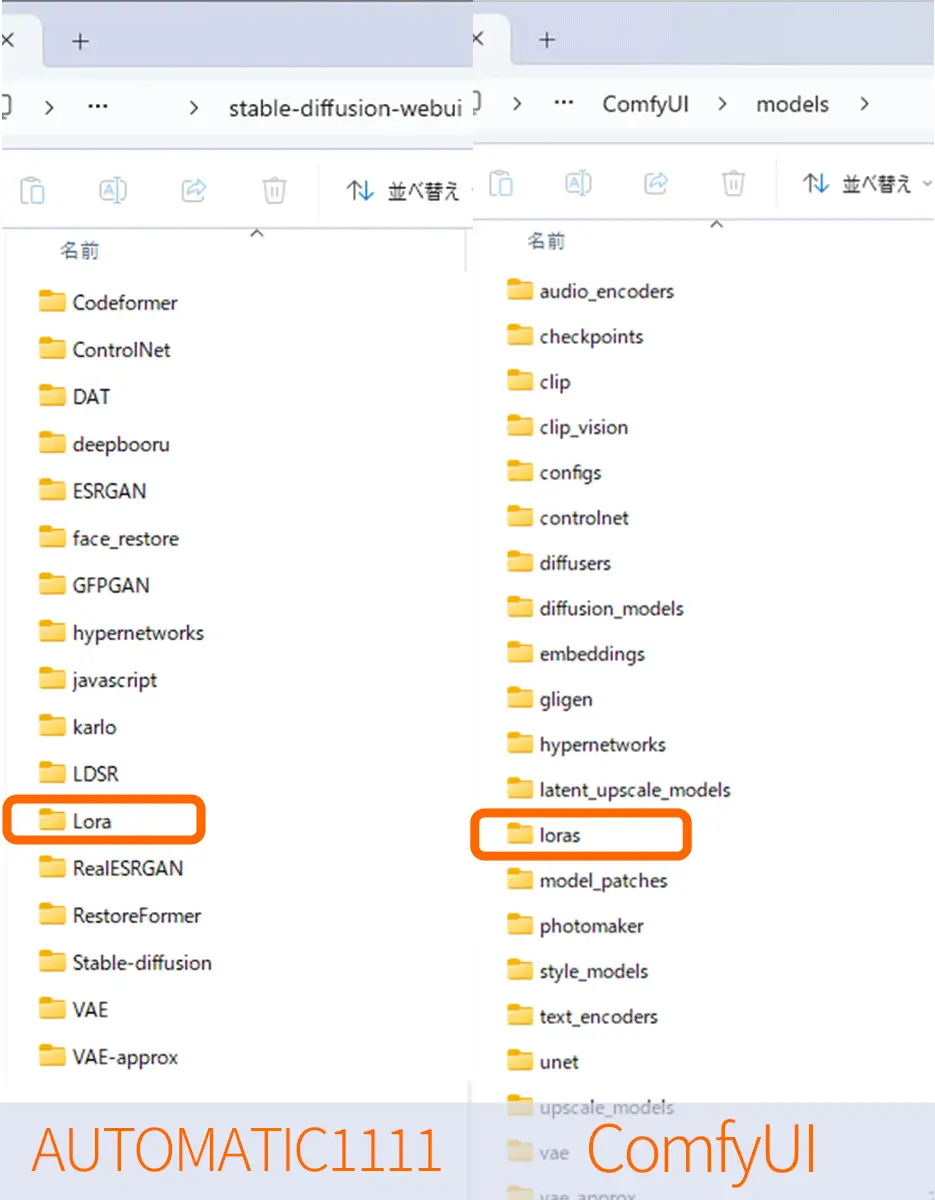
StableDiffusion Automatic1111では、Stable-Diffusion-webui/Loraとなっていますが、
ComfyUIでは、ComfyUI/models/lorasがLoRAモデルの配置場所になっています
Step 1:LoRAファイルのダウンロード
- Hugging Face、Civitaiなどのサイトから
.safetensors形式のLoRAファイルをダウンロードします
例:anime_style_lora.safetensors - ファイルを次の場所に移動
ComfyUI\models\lora\Step 2:ComfyUIでLoRAノードを使う
- ComfyUIを起動して、ワークスペースを開く
- ノード追加 → 検索窓で「LoRA」と入力
→Load LoRAを追加 Load LoRAノードでファイルを選択(プルダウンメニューに出てきます)Apply LoRAノードをCLIP Text EncodeとCLIPに接続
LoRAは「テキストエンコードとUNet」に適用されるので、2箇所に接続が必要です。
便利な拡張ノードとプラグイン
SAKASA AI
Stable Diffusion 拡張機能まとめ|ComfyUI・A1111・Invoke対応の完全ガイド | SAKASA AI Stable Diffusionの拡張機能(Extension) 本記事では、StableDiffusionの拡張機能が使用できるツールと拡張性、そして現在、使用できる拡張機能についてまとめました。 St…
- ComfyUI Manager(拡張管理が楽になるアドオン)
- Impact Pack(便利なノード集)
- WAS Node Suite(高機能な画像処理ノード集)
- Efficiency Nodes(軽量化・効率化用)
- ControlNet Preprocessors(Canny、Depth、OpenPoseなど)
【ControlNet導入】ComfyUI編
ControlNetは、Stable Diffusion系モデルに追加できる 条件付けモジュールです。外部画像を入力して、生成画像に「線画」「ポーズ」「マスク」などの形状を反映させる事が出来ます。現在では、使いやすいテンプレートも沢山あるので便利でお薦めです。
Step 1:拡張モデルのダウンロード
ControlNetモデル(例:control_sd15_canny.pth など)は、
ComfyUI画面の上部にあるManager(マネージャーを検索してみて、無い場合は、HuggingFaceなどから入手します。
※ControlNetモデルは、目的(ポーズ/線画/深度など)に応じて選びます。
用途例
| 目的 | 必要なノード例 |
|---|---|
| アニメ風にしたい | LoRA (anime style LoRA) |
| ポーズを再現したい | ControlNet + OpenPoseノード |
| 線画から着色したい | ControlNet + Cannyノード |
Hugging Faceのリポジトリ
SAKASA AI
【ControlNetの使い方】完全ガイド|線画・ポーズ・輪郭で思い通りに画像生成する方法 | SAKASA AI ControlNetの使い方を初心者向けに徹底解説!線画・ポーズ・輪郭を使って、思い通りの画像を生成する方法を具体的に紹介します。おすすめのプリプロセッサやLoRAとの組み合…
ファイルはcontrolnetフォルダに入れると反映されます。
ComfyUI\models\controlnet\Step 2:ControlNetノードを使う
- ノード追加 →
ControlNet Loaderを追加 ControlNet Applyノードも追加し、適用対象を設定するImageノードやCanny Detectorノードなどと接続して、元画像から条件を抽出する
例えば「ポーズ」や「線画」などから、ベース画像の構図を維持したまま画像生成ができます。
- LoRAとControlNetは併用可能です。どちらも使うと、精度の高い、意図したスタイルの画像が作れます
ノードで出来る事
- LoRAやVAEを切り替え
- ControlNetでポーズや構図を指定
- 複数の画像を並列生成
- SDXL+Refinerの高品質連携
- スライドや動画生成まで1画面で構成
処理を視覚的に理解しながら構築できるので、初心者の学習用にもぴったりです。
画像生成を“理解可能な構造”として扱いたい人に、ComfyUIはぴったりの選択肢です。
SAKASA AI
画像生成&学習用「クラウド型」「ローカル型」ツールまとめ | SAKASA AI このページでは、画像生成と、学習に使用できる各種ツールについて、まとめています。 下のリンク記事”【ローカル】【クラウド】【GUI】【CLI】画像生成AIを動かす7つの…
2025年8月 v0.3.51のアップデートでさらに使いやすくなったComfyUI
- 2025年8月20日にComfyUI v0.3.51がリリースされました。
- [C]キーで開く「Comfyメニュー」から「設定」と「拡張機能の管理」にアクセス可能に。
- 全体を見渡せるミニマップが追加(クリックでジャンプ)
- Manager機能の進化
- 追加された新規ノード(v0.3.51以降)
- WANノードのV3スキーマ変換:将来の拡張性を高める内部改善
- ImageScaleToMaxDimension(v0.3.57):画像を指定した最大寸法にスケーリング
- WanSoundImageToVideoExtend(v0.3.55):音声から生成された動画を手動で延長
- LatentCut(v0.3.55):潜在表現の一部を切り出し
- LatentConcat(v0.3.53):複数の潜在表現を連結
ComfyUIでQwenを使う
あわせて読みたい
【別物】ComfyUIで“描き直す”高解像化|Qwen-Image-Edit-Rapid-AIOの使い方と実力 Qwen-Image-Edit-Rapid-AIO ComfyUIでQwen-Image-Edit-Rapid-AIOを使うと、単なるアップスケールではなく「ディテールを描き直す」高解像度化ができます。 ・ぼやけた顔…
あわせて読みたい
Qwenを使う前提でComfyUIを組むと、考え方が変わる 最近は、Stable Diffusion以外の生成モデルがComfyUIで扱われています。 中でもQwen系モデルは、従来のSD前提のワークフローとは考え方そのものが異なる部分が多くあり…
Comfyのエラー
SAKASA AI
【保存版】ComfyUIが急に動かない原因はこれだった!ローカル環境の落とし穴と、クラウドで一発解決できる… ComfyUIが急に動かない?起動エラーの本当の原因を、ローカル環境の依存関係・CUDA衝突まで徹底解説。DockerやRunPodで一発解決する方法も詳しくまとめています。