【別物】ComfyUIで“描き直す”高解像化|Qwen-Image-Rapid AIO(v18)の使い方と実力

Qwen-Image-Rapid AIO
ComfyUIでQwen-Image-Rapid AIO(v18)を使うと、
単なるアップスケールではなく「ディテールを描き直す」高解像度化ができます。
・ぼやけた顔がくっきりする
・線がシャープになる
・質感がリアルに補完される
従来のHires.fixやアップスケーラーとは別物の新たな書き直しをしてくれます。
目次
Qwenの特徴
Qwen-Imageは、Stable Diffusion系のモデルと比べると
全体的にコントラストが控えめで、やや柔らかい描写になります。
そのため、人によっては「ぼやけている」と感じる場合がありますが、
実際にはディテールが弱いのではなく、
質感や階調を重視した表現になっているのが特徴です。
そして、もう一つの特徴は、Qwen Image Edit 系は本質的に画像編集ができる拡散モデルであるため、
入力画像を高解像度キャンバスに再投影しプロンプトに沿って「描き直す」という動きになります。
Qwen Image Edit 系の種類
ComfyUIテンプレでは、この三種類のどれかが使われています。
Qwen Image Edit
Qwen Image Edit Rapid
Qwen Image Edit Rapid AIO
すべて「画像編集」ですが、それぞれに特徴があります
① Qwen Image Edit(無印 / base)
精度重視モデル
性格
- 指示理解が強い
- 編集は割と大雑把
- 再生成寄り
向いてる
- 雰囲気変更
- 大きな服装変更
- 背景差し替え
向いてない
- 細かい保持
- 顔の完全一致
「再解釈・再生成」
最近、人気の一枚絵からの多角度生成などもこのモデルに、Qwen-Edit-2509-multiple-anglesなどのLoRAモデルを組み合わせている。
② Qwen Image Edit Rapid
高速版(軽量・推論短縮)
性格
- ステップ少なめ
- 編集が速い
- 保持力がやや強い
向いてる
- 軽い修正
- 表情変更
- 微調整
向いてない
- 大改造
- 厳密一致
「軽再構成・軽編集寄り」
③ Qwen Image Edit Rapid AIO(v18など)※今回のモデル
AIO(All-In-One)の特徴は、
通常のQwen Editでは、
- 本体モデル
- VAE
- CLIP
- LoRA(複数)
- Accelerator
すべてバラバラで管理&接続が必要なところを、ひとつにまとめたモデル。
モデル本体が最初から高速設計で、All-In-Oneの29GB
性格
- 統合モデル
- プロンプト忠実
- 一貫性重視
向いてる
- キャラの整形
- 最終ブラッシュアップ
- 見栄え改善
向いてない
- 機械的編集
- 線の保持
「再構築+安定」
Qwen Image Edit Rapid AIOに向いてる用途
⭕ 向いてる
- AIイラストのブラッシュアップ
- キャラの修正・衣装変更
- 表情・ポーズの微調整
- 3Dレンダ → イラスト化
- 「もう一段上の見栄え」にする工程
❌ 向いてない
- 写真補正
- 線画の忠実編集
- UI素材
- 技術資料
具体的にできること
できるアップスケール的用途
✔ 512px → 1024px / 2048px
✔ キャラの顔ディテール追加
✔ ぼやけた服・装飾の描き直し
✔ 写真 → より写真っぽく
✔ AI絵 → より情報量の多いAI絵に
「元絵を尊重しつつ、情報を増やす」用途
苦手なアップスケール
✖ ロゴ・UI・文字
✖ 線画の忠実な拡大
✖ ドット絵
✖ 技術資料・スクショ
ここは Real-ESRGAN / SwinIR / AnimeSR の方が得意だと感じます。
ComfyUIでの生成手順
STEP
ComfyUIインストール
(もしくは*RunodでComfyUIを開く)
(もしくは*RunodでComfyUIを開く)
Qwen-Image-Edit-Rapid-AIO で必要なVRAM
Qwen-Image-Edit-Rapid-AIOは、VAE・Qwenテキストエンコーダ・Lightning LoRAを1ファイルにまとめたAll-in-One型モデルです。通常のFluxなどと比べてセットアップが楽な反面、バージョンによってVRAM要件が変化しており注意が必要です。
▶ Qwen-Image-Edit-Rapid-AIO で必要なVRAMについては、こちらをクリックして下さい
バージョン別・形式別のVRAM目安
| バージョン / 形式 | 必要VRAM | 備考 |
|---|---|---|
| v5以前(通常) | 8GB | 比較的軽量。8GB環境でも動作実績あり |
| v9〜v18(通常) | 12GB以上推奨 | v9以降は8GBでOOMが多発する報告あり |
| FP8版 | 12〜16GB | 品質重視。RTX 4070Ti以上が快適 |
| GGUF版(Q4_K_M等) | 6GB〜 | RTX 4050(6GB)で1024×1024画像を約2分で生成可能 |
| フルFP16版 | 24GB〜 | RTX 4090推奨。高品質だがファイルサイズも大きい |
GPU別の動作目安
| GPU | VRAM | 評価 |
|---|---|---|
| GTX 1080 / 20xx系 | 8GB〜 | ⚠️ 非推奨。RTXシリーズ(CUDA AIコア対応)が必須とされており、GTX系は正常動作しない場合がある |
| RTX 3060(12GB) | 12GB | ✅ v18をGGUFで動かす最低ライン |
| RTX 4060Ti(16GB) | 16GB | ✅ FP8版も安定。コスパ重視ならベスト |
| RTX 4070Ti / 4080 | 16GB | ✅ FP8版でも快適に動作 |
| RTX 4090 | 24GB | 🏆 FP8ワークフローを快適に動かせる推奨GPU |
ストレージの注意点
フルバージョンは約60GBのストレージが必要です。量子化FP8版なら約30GB・VRAM 6GB以上・RAM 32GBで動作するため、ローカル環境ではFP8版かGGUF版の選択がおすすめです
ComfyUIのインストール方法はこちら
ComfyUIとは?Stable Diffusion 各モデルの特徴・用途・対応ツールのインストールと使い方 ComfyUIの使い方 Stable Diffusionの代表的WebUI「AUTOMATIC1111」に続き、InvokeAIやForgeも人気が急上昇。しかし、最も高機能なツールとして注目されるのは、自由自在…
安定しない場合は、RunPod(クラウドGPU)でRTX 4090を時間課金レンタルするのが最も確実な解決策です。
※Runpodで使用する場合はComfyUIインストールは不要です。
RunpodでComfyUIを使用する場合はこちら
【RunPodの料金と使い方】Stable Diffusionなどで画像生成やLoRA学習をする方法【②実践編】 RunpodでStable Diffusion系画像生成やLoRA学習をする方法 Stable DiffusionやLoRA学習では、長時間GPUをフル稼働させるため、発熱や電源の安定性が大きな課題になりま…
STEP
Qwen-Image-Rapid AIO(v18)のダウンロード
Qwen-Image-Rapid AIO(v18)は「ダウンロードする必要があります」
モデル本体(必須)
まず モデルファイルをダウンロードします。
例(よく使われるもの)
- Qwen-Image-Edit-Rapid-AIO-v18.safetensors
- または GGUF版
このモデルは通常
ComfyUI/models/checkpoints
に入れます。
このAIOモデルは
複数のQwenモデルをまとめたもので、生成や編集を1つでできるようにしたものです。
STEP
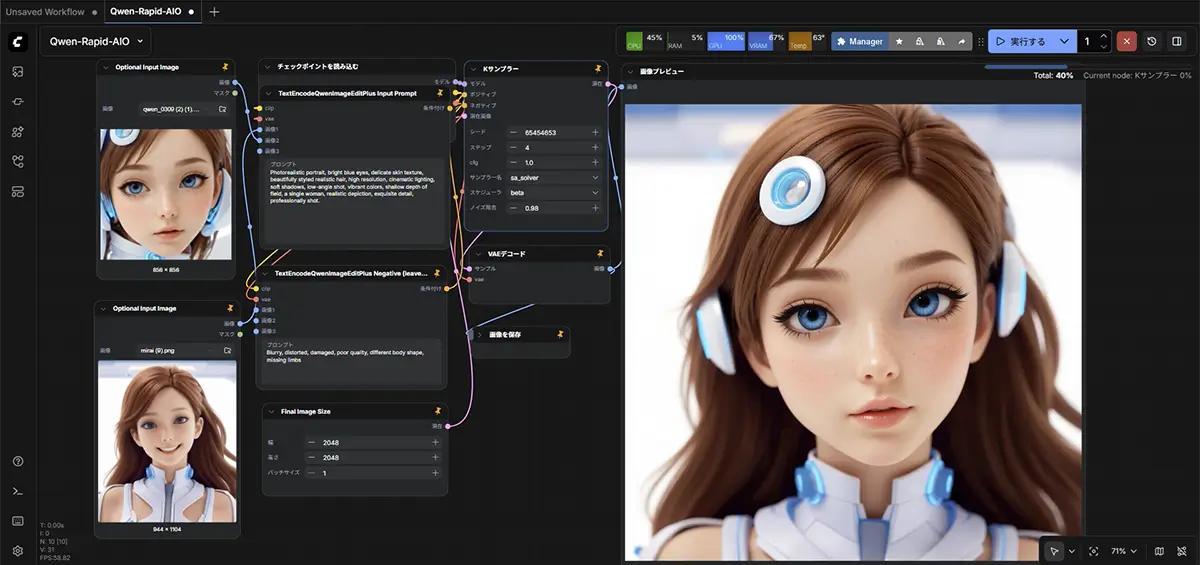
workflow.jsonを読み込む
ワークフロー(JSON)
次に必要なのが
workflow(ノード構成)
あわせて読みたい
Phr00t/Qwen-Image-Edit-Rapid-AIO · Hugging Face We’re on a journey to advance and democratize artificial intelligence through open source and open science.
例
Qwen-Rapid-AIO.json
これは
ComfyUIにドラッグ
すると読み込めます。
ComfyUIは画像やJSONをドラッグするとワークフローを読み込める仕組みです。
STEP
生成
- 元画像を Load Image
- 1024〜2048px にリサイズ
- Qwen-Rapid-AIO v18 で I2I
- Denoise:0.2〜0.4
「雰囲気・構図は維持しつつ、描写だけ増える」
より詳しい設定や実際のワークフローは
note や Patreonで公開しています
あわせて読みたい
Qwenを使う前提でComfyUIを組むと、考え方が変わる 最近は、Stable Diffusion以外の生成モデルがComfyUIで扱われています。 中でもQwen系モデルは、従来のSD前提のワークフローとは考え方そのものが異なる部分が多くあり…