LoRAとは?仕組み・学習・使い方・学習パラメータまで【LoRA完全ガイド】

LoRAとは何か?
LoRAとは、Low-Rank Adaptation(低ランク適応)の略で、大規模なモデル(例:Stable Diffusion)の重みをすべて再学習するのではなく、一部だけを効率的に調整できる手法です。モデル全体ではなく、小さな追加モジュール(LoRA層)を学習させることで、
- GPUリソースが少なくても学習できる
- 学習時間が短くて済む
- 微調整(ファインチューニング)がしやすい
という特徴があり、画像生成AIや大規模言語モデルの軽量ファインチューニング技術として広く使われています。
 未来
未来本体モデルに着せ替えアイテムや拡張パックを加えるような感覚で、カスタマイズができます!
目次
LoRAの仕組み
LoRAは「学習元のモデル(base model)」の特定の層に、追加の小さな行列(LoRA層)を挿入します。この行列は初期状態ではゼロに近い値で、元のモデルの動作を邪魔しませんが、学習によって変化し、出力を補正するようになります。
LoRAで出来る事
- 特定のキャラや服装、ポーズに特化したスタイル
- 自分のオリジナルキャラを再現したモデル
- 特定の背景や構図、画風を再現するための補助モデル
LoRAを使うメリット
- **フルファインチューニングに比べてVRAM消費が圧倒的に少ない(8GBから可能(ただしSD1.5で512pxと限定的)できれば12GBほしい)
- 目的に合わせたモデルを簡単に追加・切り替えできる
- モデル容量が小さい(数十MB〜数百MB)
| 手法 | 特徴 |
|---|---|
| **フルファインチューニング | モデル全体を学習。高精度だが時間とVRAMが必要 |
| DreamBooth(ドリームブース) | 人物やキャラに特化。学習に時間がかかることも |
| LoRA | 効率よく学習・切替可能。軽量で実用的 |
| Textual Inversion | 文字列を新しい概念に対応させる。非常に軽量 |
LoRAの制約・デメリット
高度な表現力や複雑な概念には限界がある(→ DreamBoothやフルファインチューニングが必要)
学習データの質に強く影響される(少量データでも効率的だが、データ品質が重要)
既存モデルの構造に依存する(特定のベースモデルと互換性が必要)
LoRAのファイル形式とサイズ感
ファイル形式:.safetensors または .pt
サイズ目安:30MB~200MB程度(内容やrankによる)
学習時間:10~60分程度(GPU、**学習ステップ数などによる後で解説)
※高性能GPU(例:A100やRTX 4090):高速処理が可能で、同じステップ数でも短時間で学習できます。
※低スペックGPU(例:T4やVRAM 8GB以下):メモリ制限や処理速度の関係で、同じ条件でも2倍〜数倍時間がかかることがあります。
目安としては、RunPodなどでは、A100(VRAM 80GB)であれば10分程度、
ColabでT4(VRAM 16GB)なら20〜40分程度が目安になります(ステップ数500前後)。
LoRAが使える主なツールとフレームワーク
LoRAは、
「学習」フェーズ(LoRAを作る)と
「推論/使用」フェーズ(LoRAを使う)で
使うツールや目的が異なります。
LoRAの「推論/使用」フェーズ:【画像生成系】(Stable Diffusion関連)
「推論/使用」フェーズでは、ツールでLoRAをLoRAモデルとして「読み込み」、使用する事を指しています。
目的: 作ったLoRAを使って画像生成する(学習は行わない)場合。
| ツール名 | 特徴 |
|---|---|
| web UI (AUTOMATIC1111) | Stable Diffusion定番UI。LoRAの読み込みに対応(<lora:name:weight>など) |
| ComfyUI | ノード式でLoRAを差し込むノードがある(LoRA Loaderなど) |
| InvokeAI / Fooocus | 一部LoRAに対応しているツールも増えている |
| Stable Diffusion XL 対応UI | SDXL対応版はLoRA Block Weightなど専用ノードが必要なことも |
LoRAモデルはmodelsフォルダにセットして使用します。
LoRAモデルをmodelsフォルダにセットして画像生成を行う方法についてはこちらで書いています。
SAKASA AI
【完全ガイド】Stable Diffusion WebUI(AUTOMATIC1111) LoRA モデルの使い方と設定手順 | SAKASA AI Stable Diffusion WebUI(AUTOMATIC1111)での、”LoRAモデルの配置方法から、強度の設定・プロンプト調整までを、わかりやすく解説しています
フォルダ構成(例)
上のリンク記事内では、Automatic1111でのLoRAモデルの配置と使用方法などを書ていますが、他のツールにおいてもフォルダ構成や、使用方法は、よく似ています。
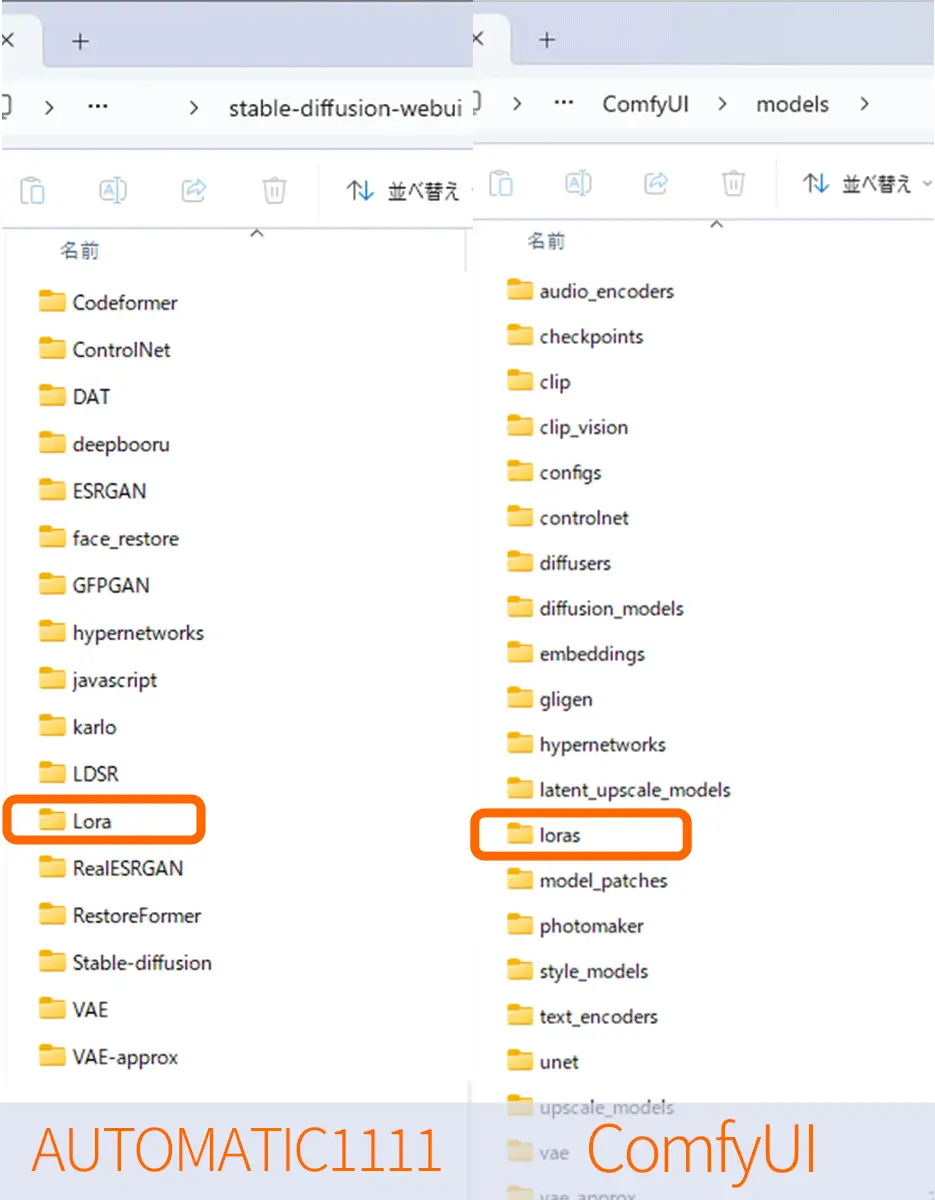
StableDiffusion Automatic1111では、Stable-Diffusion-webui/Loraとなっていますが、
ComfyUIでは、ComfyUI/models/lorasがLoRAモデルの配置場所になっています
LoRAの「学習」フェーズ:【画像生成系】(Stable Diffusion関連)
目的:絵柄や特定のスタイル・キャラの特徴をAIに覚えさせる
主に使用されているツールは、Kohya_ssです。
| ツール名 | 特徴 |
|---|---|
| Kohya_ss | 最も有名なLoRA学習ツール。細かい設定が可能。 Colab RunPodでの使用方法についてはこちらhttps://sakasaai.com/runpod-set01/ 自分のPCにインストールする方法はこちらhttps://sakasaai.com/local_kohya_ss/ |
| sd-scripts | Kohyaのベース。コマンドライン操作が必要で、玄人向け |
| ComfyUI (学習向け拡張あり) | ノード式で直感的。LoRA学習用ノードも登場しつつあるが、構築がやや難しい |
| Diffusers (Transformers系) | HuggingFaceベースのコードライクな学習。LoRA統合も可能だがやや専門的 |
作ったLoRAを再び学習にかけて、さらに調整したり、別のスタイルを混ぜたりと、再学習(ファインチューニング)も可能です。Kohya_ssなどでは、元のLoRAを初期値として使うことで、そこからさらにデータを加えて再学習ができます。
LoRA学習で使用できるモデル
Kohya_ssでLoRA学習を行うには、
必ず「学習元となるCheckpointモデル」が必要です。
これは、Stable Diffusionで画像生成に使用する.ckpt や .safetensors 形式のベースモデルを指します。
LoRAは「ゼロから絵を学習する」のではなく、
既存のモデルに対して差分(LoRA)を学習する仕組みのため、
このCheckpointモデルが存在しないと学習は開始できません。
「ベースモデル(Checkpoint)」とは?
- LoRAは「何もない状態」からは学習できない
- 必ず 元になるCheckpointモデル を1つ指定する必要がある
Checkpointは1つだけ選べる・・・何がいい?
おすすめは、SD1.5
おすすめは、SD1.5の
Anything v5 / Counterfeit / AOM3系 のいずれかです。
理由
- 学習事例が多い
- WD14タグとの相性が良い
- 生成時の破綻が少ない
- LoRAが「素直に効きやすい」
迷ったら Anything v5系 を選ぶと安心です。多くのLoRA学習記事・テンプレでも採用されており、
初心者でも再現しやすいCheckpointです。
SDXL
※ SDXLについては
【Kohya_ss×SDXL 】SDXLでLoRAをつくる人が最初に知っておくべきことで解説しています。
重要点
SD1.x と SDXL は「別物に近い」
- SD1.5系
- 512px前提
- CLIP(テキストエンコーダ)が1系統
- 学習データ・タグ文化が成熟している
- SDXL
- 1024px前提
- CLIPが2系統(text + text2)
- 構図・光・質感の解釈が全く違う
「同じプロンプト・同じ絵柄」でも、モデルの理解の仕方が違う
他ツール由来の絵柄を入れると起きがちなこと
たとえば:
- SD1.5系で作られたアニメ絵
- NovelAI系の作風
- 他のDiffusion系ツールの癖が強い画像
これを SDXLベースでLoRA学習すると
- 破綻はしない
- 学習も完走する
- 再現性が低い
- トリガーが効きにくい
- 絵柄が「ぼやける」「平均化される」
ということが起きやすいです。
「ダメ」になるケース
完全にダメになるのは、だいたい次のパターンです
解像度と前提がズレすぎている
- 512px前提の絵を、そのまま1024pxで雑に拡大
- アップスケールの質が悪い
キャプションがモデルと合っていない
- SD1.5向けタグ(danbooru寄り)を
- SDXLにそのまま投げる
WD14を使っても、タグ文化の差は残る
それでも「やっていい」ケース
やってもOKなケース
- 「完全再現」ではなく「雰囲気移植」が目的
- 元の絵柄を ベース参考 として使う
- 学習後に
- 学習率を下げる
- rankを低めにする
- 強めに学習しすぎない
この場合「うまくいきにくいけど、うまくいけば価値はある」
Kohya_ssでLoRA学習をする方法
Kohya_ssとは?LoRA学習に特化したGUI版の使い方【完全ガイド2026年最新版】 Kohya_ssとは? 本記事では、Kohya_ssとは何かという基礎から、LoRA学習に特化したGUI版の使い方、そして2026年時点の最新UIの実践手順までをまとめて解説します。 Kohy…
LoRAの使い分け例(画像・言語モデル)
| タイプ | 使用目的 | 推奨ツール |
|---|---|---|
| 画像生成 | キャラ特化・画風学習 | Kohya_ss、sd-scripts |
| 画像生成 | LoRAモデルのテスト・合成 | A1111、ComfyUI |
| 文章生成(LLM) | 文章スタイル・応答の調整 | PEFT、QLoRA、Axolotl |
| 音声・動画系 | 試験的導入が進行中 | まだ一般向けツールは少ない |
LoRAを組み合わせる活用例
| 活用パターン | 説明 |
|---|---|
| 複数LoRAの組み合わせ | 「キャラLoRA」+「画風LoRA」+「構図LoRA」などをA1111などで合成使用 |
| 管理ツールとの併用 | LoRA Manager拡張などで効率的に切り替え・比較 |
| LoRA強度(weight)調整 | <lora:name:0.6> のように、生成時に強度を調整可能(ComfyUIでも可) |
Stable Diffusionモデルに新しい情報(人物・スタイル・キャラクターなど)を学習させるためのLoRA系の軽量学習手法(ファインチューニング手法)
類似手法
| 手法名 | 概要 | 備考 |
|---|---|---|
| LoRA | モデルの重みの一部(特定の層)にだけ低ランク行列を追加して学習 | 現在の主流、非常に軽量 |
| LyCORIS | LoRAの拡張版。複数の変換方法を組み合わせて柔軟性を向上 | より精細なチューニングが可能 |
| LoHa / LoCon | LyCORISに含まれる手法。LoRAよりも学習が安定しやすいことがある | 画像ジャンルによって相性がある |
| Dylora(Dynamic LoRA) | LoRAを層ごとに動的に使い分ける発展型 | 学習の柔軟性が高いがやや複雑 |
LoRA系は「後から読み込み式(追加モジュール)」で、WebUIやCivitaiで多用されています。
Kohya_ss を使用した、LoRA学習
LoRA学習で最も使用されている、Kohya_ss を使用してLoRA学習をする方法
LoRA学習時の学習パラメータ等の詳細についてはKohya_ssとは?のページで解説しています。
Kohya_ssの使用方法
Kohya_ssとは?LoRA学習に特化したGUI版の使い方【完全ガイド2026年最新版】 Kohya_ssとは? 本記事では、Kohya_ssとは何かという基礎から、LoRA学習に特化したGUI版の使い方、そして2026年時点の最新UIの実践手順までをまとめて解説します。 Kohy…


【言語モデル系(LLM)】
| フレームワーク | 主な用途 | 備考 |
|---|---|---|
| PEFT (Hugging Face) | LLM向けのLoRA学習ライブラリ。 | ChatGPTのようなLLMにもLoRAが使われる |
| QLoRA | メモリ節約型LoRA。GPUが小さくても学習可能。 | LLM学習の省リソース化に最適 |
| Axolotl | LLaMA系のLoRA微調整に使われる。 | GPUクラスタでも使える学習基盤 |
| OpenVINO / ONNX | エッジ端末でのLoRA適用に対応。 | 展開用途に適している |