【AI画像生成 Text-to-Image 完全ガイド】初心者から中級者向け基礎・比較・活用術

AI画像生成 Text-to-Image
 未来
未来「Text-to-Image Generation」 は、テキスト(文章)を入力するだけで、画像を自動生成する技術のことだけど、思い通りの画像になる?
 SAKASA
SAKASAそれが、なかなか思うような画像にならないんだよなぁ…
 セレナ
セレナAIは自然言語から視覚的なイメージを作り出す技術を持っているけど
ちょっとしたコツがあるから、まずは仕組みからお話するわね。
目次
Text-to-Imageとは?
想像をそのまま“画像”にする
「ユニコーンが火星を歩いている光景を見たい」―
もし数年前にそう言ったら、「空想家だね」と笑われたかもしれませんが、今は現実の画像として数秒で手に入ります。しかも、AIがゼロから描いたものとして。
これが、Text-to-Image(テキストから画像を生成する)AIの技術です。
使われている代表的な仕組みは、「拡散モデル(Diffusion Model)」と呼ばれています。
これは、一度“ノイズだらけの真っ白な画像”にしてから、少しずつ意味のある画像に戻していくという逆転の発想の技術です。
まるで霧の中から絵が浮かび上がってくるように、AIは意味ある形を再構成していきます。
参照:OpenAI DALL·E2 技術報告書
https://openai.com/research/dall-e
歴史の裏話:DALL·Eの名前の由来
「DALL·E(ダリ)」という名前を聞いて、あの有名な画家「サルバドール・ダリ(Salvador Dalí)」を思い浮かべた人は鋭いです。
実はこの名前、「ダリ」+「ウォーリーをさがせ!(Pixar映画“WALL·E”)」から来ているそうです。
つまり「想像力あふれる芸術性 × 知能を持った機械」という、ユニークな掛け合わせなのです。
高性能なモデル(DALL·E 3やStable Diffusion 3など)の登場
商用利用や個人クリエイターによる活用が急増
FigmaやCanvaと連携し、Webデザインにも活かせる
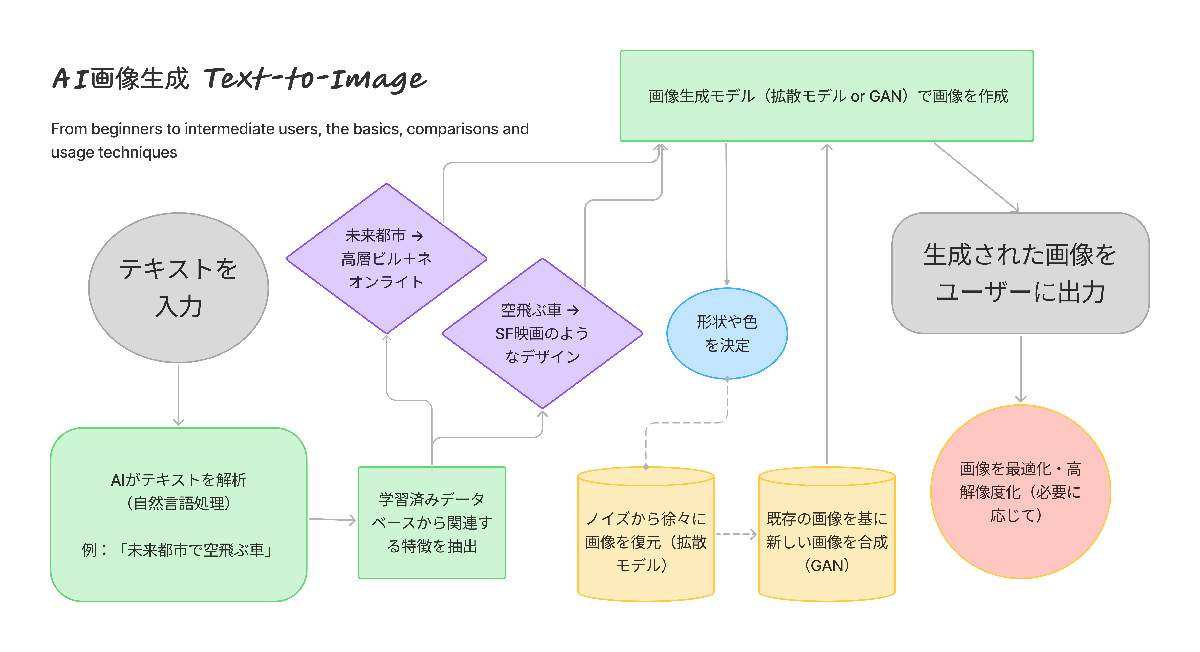
この技術は、**ディープラーニング(深層学習)**を活用し、上の図の様なステップで画像を生成している。
主要ツールの特徴と比較
目的で選ぶ!Text-to-Imageツール
Text-to-Imageには、さまざまなツールがあります。それぞれ得意分野や操作性が異なるため、「どれを使えばいいかわからない」という方も多いかも知れません。
ここでは、特に人気のあるツールの分類を踏まえて、特徴・向いている人・活用シーンをご紹介します。
AI画像生成モデルの大まかな系譜
- Stable Diffusion(Stability AI) が2022年に登場
↓
オープンソース化によって、世界中の開発者・企業が自由に改良できるように。
↓ - そのオープンモデルをもとに、
- Midjourney(完全クローズドにして芸術性特化)
- Leonardo AI(UIと安定品質重視)
- Playground、Firefly、Mage.Space、NightCafe など
といった “商用派生系” が次々登場。
↓ - 結果として今のAI画像界は
「Stable Diffusion派生組」 vs 「完全独自開発組(例:DALL·E 3)」
に分かれている状態。
主なText-to-Imageツール比較
| ツール名 | 特徴 | 操作性 | カスタマイズ | 商用利用 | プロンプトの自由度 |
|---|---|---|---|---|---|
| DALL·E 3(OpenAI) | ChatGPTと連携、使いやすい | 会話型UI | ✕(内部モデル非公開) | ◯ | ◯(英語がやや得意) |
| Leonardo.Ai | ゲーム・デザイン向けの高精度出力 | Web UI | 〇(LoRA相当のFine-tune可) | ◯ | ◯(フィルタ多彩) |
| Midjourney | 芸術的・幻想的なビジュアルが得意 | Discord | △(パラメータ・スタイル指定) | ◯ | ◯(表現は独特) |
| Stable Diffusion | ローカルでも使える高自由度モデル | カスタム | ◎(モデル・LoRA完全自由) | ◎ | ◎(詳細制御可能) |
DALL·E 3(ChatGPT内蔵)
- 特徴:自然な絵作り、人物や構図も安定。修正指示が通じやすい。
- 向いている人:プロンプトが苦手でも大丈夫!まずAI画像を体験したい人に最適。
- 活用例:ブログのアイキャッチ、資料の挿絵、教育用途など
ポイント:ChatGPT Plusを使えば、DALL·E 3をそのまま会話で使えます。
Leonardo.Ai
公開されている技術資料や挙動で、
明確にSDXLを基盤にして再学習・強化したモデル群を運用してる。
例:Leonardo Diffusion XL、AlbedoBase XL、DreamShaper XL など
これらは明らかに「Stable Diffusion XL 1.0」を改変したバージョンとされている。
最近では、ユーザーアップロードモデル(自作スタイルを反映する “Fine-tune”)に対応しており、
“中間的な自由度” が評価できます。
- 特徴:ゲーム、背景、コンセプトアート向き。テンプレや編集機能が充実。
- 向いている人:ビジュアルデザインに強い興味がある人、プロ志向の方。
- 活用例:UIデザイン、背景素材、ファンタジー風景、アイテム素材など
便利機能:プロンプトライブラリ、デザインテンプレ、要素の削除・置換など。
Midjourney
公式には「独自モデル」とされているが、
初期バージョンはStable Diffusionをベースに独自学習を重ねたものと推測されている。
以降はクローズド化して独自方向に進化(内部的にSDXL構造を取り入れている可能性が高い)したツール。
- 特徴:写真風・幻想的・ファンタジー系の表現が得意。構図が独創的。
- 向いている人:アート系や世界観づくりをしたい人。
- 活用例:ビジュアルストーリーテリング、YouTube背景、アートブックなど
注意点:Discord経由で使うため、最初は少し学習が必要です。
Stable Diffusion(特にSDXLなど)
Stable Diffusion系のWebUI
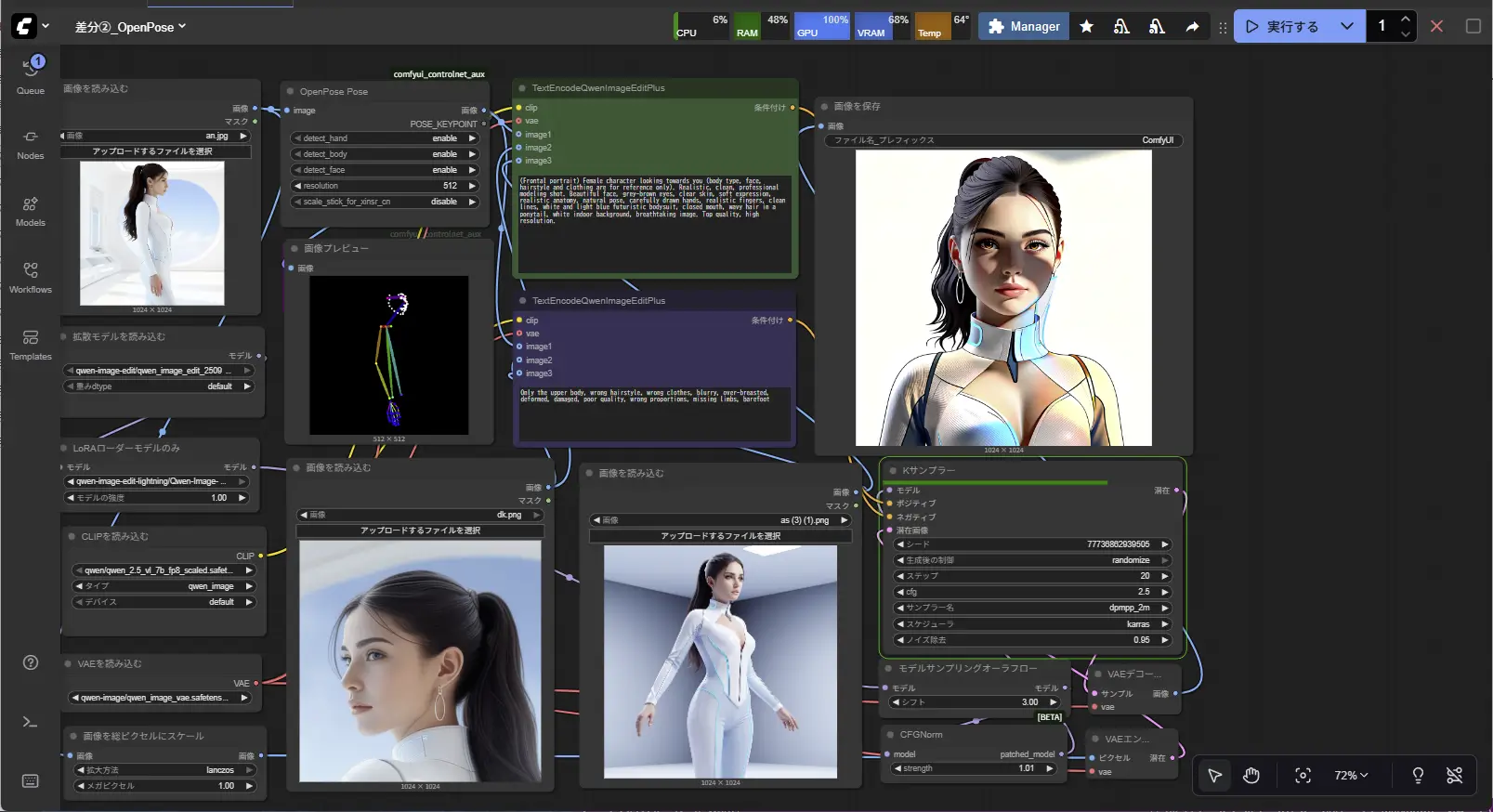
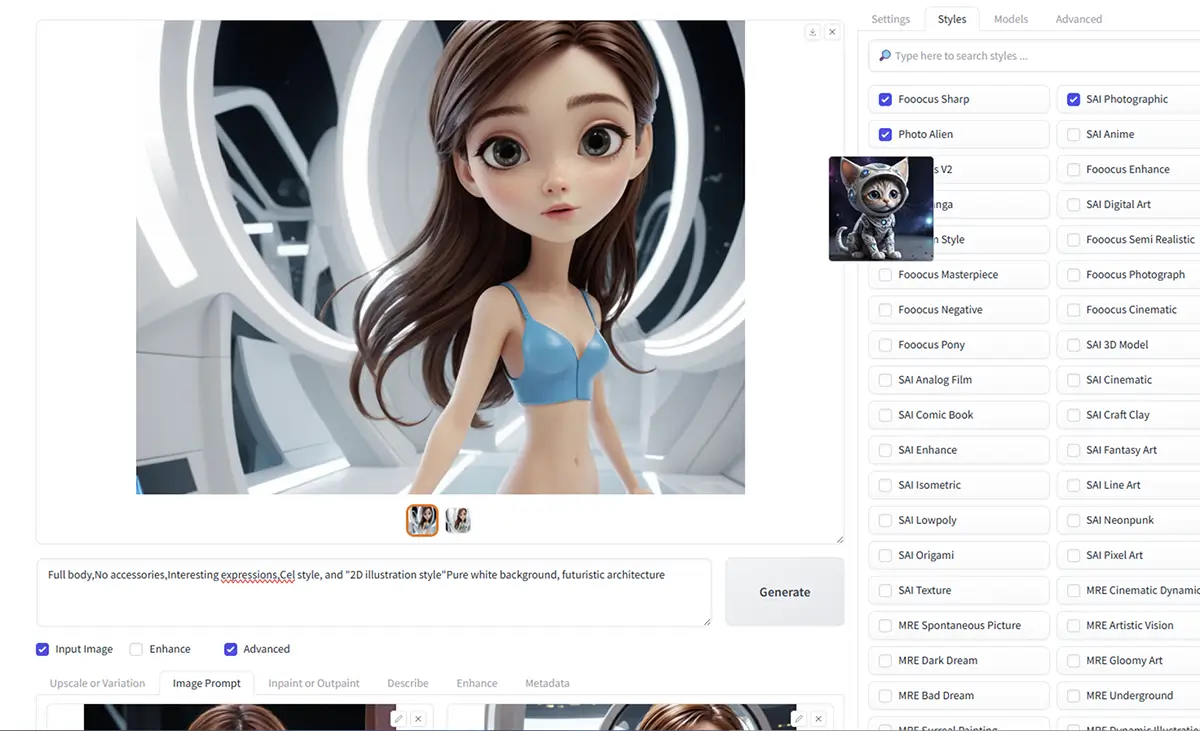
- 特徴:細かく構成をコントロールでき、コミュニティも活発。
- 向いている人:自分で細かく調整したい・ローカルで運用したい方。
- 活用例:マンガ風、ファッションイラスト、アバター制作など
SAKASA AI
Stable Diffusion 各モデルの特徴・用途・対応ツール【最新版】 | SAKASA AI Stable Diffusion 各モデルの特徴・用途・対応ツール・実行方法と商用利用OKな組み合わせ、商用利用OKのモデルライセンスと注意点などをまとめました。
ポイント:日本語モデルやLoRAの導入で大きく表現力UPできる。
| ツール | おすすめユーザー |
|---|---|
| DALL·E 3 | とにかく簡単に使いたい人、ChatGPTユーザー |
| Leonardo.Ai | ゲームやUI素材を綺麗に作りたい人 |
| Midjourney | 世界観・アート系の表現を楽しみたい人 |
| Stable Diffusion | 自分のキャラやスタイルを極めたい人 |
思い通りに近づけるヒント集
ヒント①:具体的なワードで攻める!
×「かっこいいロボット」
○「金属質な質感、光沢のある未来的アンドロイド、背景はネオン輝く夜の街」
AIは抽象より具体が大好物。「どこで」「どう見えて」「何をしてる」が明確だとGood!
ヒント②:絵コンテを描く気持ちで
Prompt(プロンプト)は、まるで監督がカメラマンに指示を出すようなもの。
例:「中心に立つ若い女性、視線は右上、光源は左、曇り空の下で傘を持っている」
**構図・光・感情の表現も意識して。**プロンプトは“映像ディレクター気分”で!
ヒント③:トライ&エラーが当たり前
1回でうまくいくのは奇跡です(AIも人間も)。 「出力 → 見て調整 → 出力」のループが成功の鍵。
キーワードを足したり削ったり、逆にしてみたり。
最初はピカソでも、やがてダ・ヴィンチになる!
ヒント④:ツールごとのクセを知る
Midjourneyは幻想的・芸術的に、
Leonardo.Aiは商業向き・高精細に、
DALL·Eはユニーク・意外性がある…
「どのAIが、どの表現が得意か」を知るのは、付き合い方の第一歩!
4. プロンプト生成のお助け道具
- PromptHero:プロンプトのアイデア集
- Lexica:他人の生成画像とプロンプトを検索
- ChatGPTに「◯◯風の画像プロンプトを作って」ってお願いする
一部だけ気に入ってるのにここがあるせいで使えない!という画像をプロンプトを使って直す方法、設定で直す方法、そして、編集で直す方法を以下の記事でご紹介しています!ぜひ参考になさって下さい。
SAKASA AI
画像生成AIでキャラクターの顔を維持しつつ、再生成する!【5つの方法】▶ 2025.10.16更新 | SAKASA AI 画像生成AIで顔を変えたい時と、顔を変えたくない時。キャラクターの顔を固定しつつ再生成したい時の設定と指示についてのプロンプトの工夫。
まとめ
画像生成AIは「思った通り」にするにはコツが必要。でもそのプロセスこそ、創作の醍醐味。ちょっとズレた画像にも「おお…これはこれでアリ」と感じる日もあるかもしれません。まるで、「自分だけのアシスタントAI画家」と一緒に、創作をする感覚。
イマジネーションが、カタチになりますよ!
SAKASA AI
Flux.1とは?画像生成AIの特徴・使い方・導入方法を徹底解説【2025年最新】 画像生成AIの進化形「Flux.1」がスゴい。誰でも手軽に使える導入法から、WebUI・クラウド・API連携まで、用途に合わせた活用法をわかりやすくまとめました。