ComfyUIとは?使い方・モデル・テンプレート・基本機能を解説【2026年版】


ComfyUI 使い方導入ガイド|モデル・テンプレート
ComfyUIは、画像・動画・3D生成をノードベースのワークフロー形式で操作できる生成AIツールです。「モデルは何を使えばいいのか?」「テンプレートはどれがいいのか?」という疑問から、Stable Diffusionとの違い・モデルの種類からインストール方法まで、まとめて解説します。
目次
ComfyUIとは
モデルや処理をブロックのようにつなぎ、自由に生成フローを構築できるのが最大の特徴です。
2024年10月〜2025年8月にかけて大幅なアップデートが行われ、UIデザインも一新。
起動時にテンプレートを選ぶだけで必要なモデルが自動ダウンロードされるため、初心者でもすぐに画像生成を始められるようになりました。
以前は「上級者向け」という印象が強かったComfyUIですが、現在は初心者から上級者まで幅広くおすすめできるツールに進化しています。
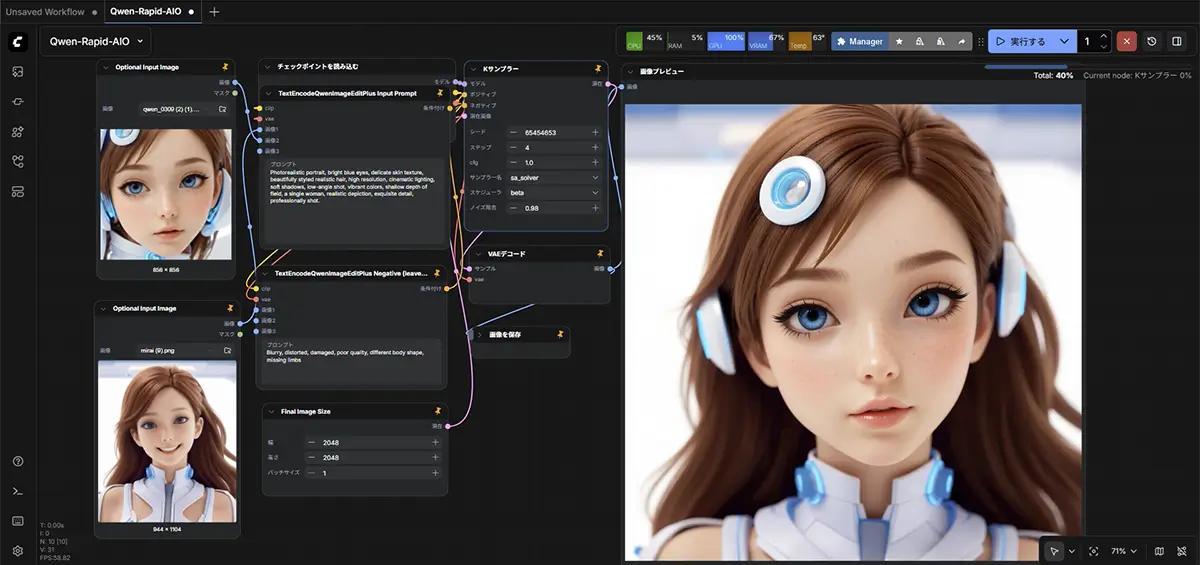
 未来
未来“ノード”をつないで自由にワークフローを組めるのが最大の特徴です。
Stable DiffusionとComfyUI
ComfyUIは、以前はStable Diffusionを「ノード(処理のブロック)をつないで動かす」形式で操作できる画像・動画生成ツールでしたが、
いまでは、画像・動画・3D生成までをノードベースで操作できる生成AIワークフローツールです。
ComfyUIの主な特徴
「SDXLや、QwenなどのモデルにLoRAを適用して、ControlNetでポーズを指定し、画像を動画に変換」という複雑な処理が、1画面でまとめて操作できるのがノードの強みです。
| 特徴 | 内容 |
|---|---|
| ノードベースの自由な構成 | 生成の流れを細かく制御でき、失敗箇所だけ再実行できる |
| 高い拡張性 | ControlNet・LoRA・動画生成・アップスケーラーなどを追加可能 |
| モデル学習にも対応 | LoRAのトレーニングや出力調整もノードで管理 |
| 軽量・マルチプラットフォーム | Windows/Mac/Linuxに対応、Colab上でも動作可能 |
AUTOMATIC1111(A1111)との違い
ComfyUIはAUTOMATIC1111(A1111)と並ぶStable Diffusion用UIでしたが、
現在は画像・動画・3D生成をひとつの画面で完結できる、マルチモーダルな生成AIツールです。
| 項目 | AUTOMATIC1111 | ComfyUI |
|---|---|---|
| 操作方法 | パネル型(直感的) | ノード型(自由度高い) |
| 処理速度 | 標準 | 速い(VRAMを効率使用) |
| カスタマイズ性 | 中 | 高 |
| 初心者向け | ◎ | ◯(2025年時点) |
| ワークフロー再利用性 | △ | ◎ |
| トラブル対応のしやすさ | 普通 | 処理の流れが見えるので対応しやすい |
| 動画生成 | △(拡張機能が必要) | ◎(WANなどのワークフローを標準搭載) |
| 3D生成 | ✕ | ◎(Tripo 3.1・Hunyuan3Dなどのノードに対応) |
A1111に慣れた方なら、ComfyUIのノード構成に移行することでさらに細かい制御が可能になります。特に環境構築の面では、テンプレートベースのセットアップによりA1111より圧倒的にスムーズに始められるようになりました。
未来今や、ComfyUIはただの画像生成ツールではないんです!
- 動画生成:WANなどのワークフローが公式テンプレートとして用意されており、
テキストや画像から動画を生成できます。Wanについて詳しくはこちらの記事をご覧ください - 3D生成:Tripo 3.1やHunyuan3Dなどのノードに対応しており、
テキスト・画像から3Dモデルの生成が可能です。3D生成について詳しくはこちらの記事をご覧ください
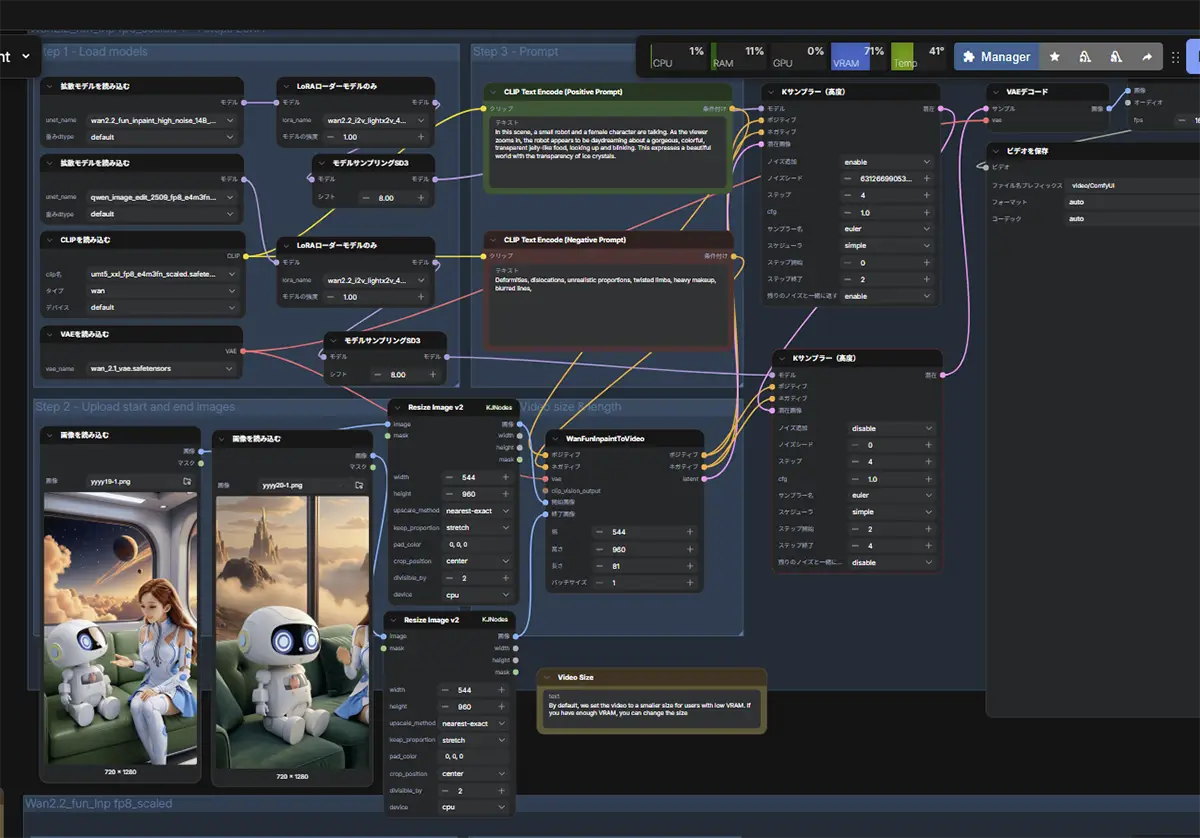
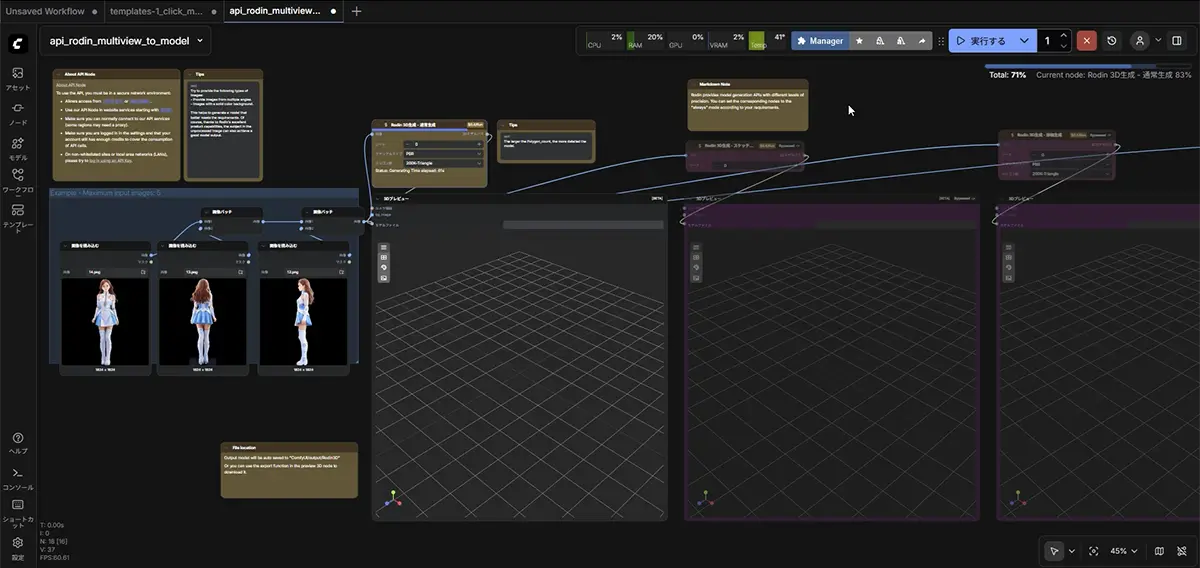
ComfyUIで使えるモデルの種類
SAKASA AI
ComfyUIで使えるモデルとは?FLUX・SDXL・WAN・Qwenの違いと選び方【2026年版】 | SAKASA AI ComfyUIモデルとは?探し方・選び方を初心者向けに解説 ComfyUI では、画像生成・動画生成・3D生成など様々なAIモデルを追加して利用できます。現在は、公式テンプレートだ…
ComfyUIで使えるモデルは大きく3種類あります。それぞれの役割を理解しておくと、モデル選びがぐっと楽になります。
| 種類 | 役割 | 目安サイズ |
|---|---|---|
| Checkpoint(チェックポイント) | 画像の全体スタイルを決定するメインモデル。必ず必要 | 4〜7GB程度 |
| LoRA | Checkpointに追加して特定スタイル・キャラ・画風を強化 | 数十MB〜数百MB |
| VAE | 色味や細部のクオリティを補正する(Checkpointに同梱の場合も) | 300MB〜1GB程度 |
代表的なCheckpointモデルのサイズ目安
| モデル | 用途 | サイズ目安 |
|---|---|---|
| FLUX.1 Schnell | 軽量・高速画像生成 | 約4GB |
| FLUX.1 Dev | 高品質画像生成 | 約12GB |
| FLUX.2 | 次世代高品質画像生成 | 20GB超クラスも存在 |
| SDXL 1.0 Base | 汎用画像生成 | 約6.6GB |
| SDXL Refiner | 高品質仕上げ | 約6.6GB |
| Stable Diffusion 1.5 | 軽量画像生成 | 約4GB |
| Stable Diffusion 2.1 | SD1.5強化版 | 約5.2GB |
| Stable Diffusion 3.5 | 構図・文字理解向上 | 10GB〜15GB前後 |
| WAN 2.x | 動画生成(Text/Image to Video) | 14GB〜30GB前後 |
| Hunyuan Video | 高品質動画生成 | 20GB〜40GB超 |
| Qwen-Image | 画像編集・理解系 | モデル構成によって大きく変動 |
| Tripo / Hunyuan3D | 3D生成 | VRAM消費大きめ |
※Flux系は量子化版(GGUF / FP8)によってサイズが大きく変わります。
代表的なモデルを揃えるだけで合計約26GBになります。SSDの空き容量は最低30GB以上を確保してください。
VAEやLoRAを追加すると、さらに数GB〜数十GB必要になります。
スペックが不安な方は、画像生成用GPUの選び方とクラウドGPU(RunPod)もあわせてご覧ください。
画像生成のためのGPUの選び方
【2026年】AI画像生成GPU おすすめ比較|RTX4060〜5090・5060Ti【Stable Diffusion・ComfyUI・LoRA対応】 画像・動画生成AIを使いたい!GPUは何を選べばいい? Stable DiffusionやComfyUIで画像生成に挑戦したい――そう思ったとき、最初に立ちはだかる壁が「GPU選び」ではない…
あわせて読みたい
【Runpodとは?】なにが出来る?特徴・メリット・注意点を徹底解説【2026年版】 Runpodは、AI画像生成や動画生成、LoRA学習などに利用できるクラウドGPUサービスです 高価なGPUを購入しなくても、必要な時だけRTX 5090やA100などの高性能GPUをレンタ…
ComfyUIおすすめモデル
ComfyUIはCheckpointモデルを切り替えるだけで、生成画像のテイストが大きく変わります。用途別に選ぶのがポイントです。
軽量・高速向け(まず試したい人)
| モデル名 | 特徴 |
|---|---|
| FLUX.1 Schnell | FLUX系で最も高速。動作確認・プロトタイプ向け |
| Stable Diffusion 1.5 | VRAM 6GB前後でも動作しやすい。軽量で扱いやすい |
| Stable Diffusion 2.1 | SD1.5より少し高品質。比較的軽量 |
高品質・汎用向け
| モデル名 | 特徴 |
|---|---|
| FLUX.1 Dev | 高品質なFLUX系。リアル・アート系両対応 |
| Stable Diffusion XL | 高品質で汎用性が高い。LoRA資産も豊富 |
| Stable Diffusion XL Refiner | SDXLの仕上げ用。ディテール強化向け |
最新世代・次世代モデル
| モデル名 | 特徴 |
|---|---|
| FLUX.2 | FLUX系次世代モデル。高画質・高指示追従寄り |
| Stable Diffusion 3.5 | 文字理解・構図理解が向上。最新世代SD系 |
| Qwen-Image | 編集・理解系に強い。生成より画像操作寄り |
注意点
- 最新世代モデルはVRAM消費量が大きい
- PyTorch / CUDA依存が強い
- 古いComfyUIテンプレでは動かない場合あり
- RTX 4090 / L40 / H100系が安定しやすい
モデルの探し方・ダウンロード方法
ComfyUIモデルの探し方や選び方はこちらの記事で詳しく解説しています。
SAKASA AI
ComfyUIで使えるモデルとは?FLUX・SDXL・WAN・Qwenの違いと選び方【2026年版】 | SAKASA AI ComfyUIモデルとは?探し方・選び方を初心者向けに解説 ComfyUI では、画像生成・動画生成・3D生成など様々なAIモデルを追加して利用できます。現在は、公式テンプレートだ…
モデルのダウンロード方法
ComfyUIでのモデル取得は主に2つの方法があります。
- ComfyUI Manager経由:UI画面上部の「Manager」→「Model Manager」から検索してダウンロード
- HuggingFace / Civitai から直接ダウンロード:Model Managerにないモデルはこちらから入手
FluxやSDXL一部モデルはHugging Faceの「認証が必要なモデル」です。認証モデルのダウンロード方法は[こちらの記事]で解説しています。
ComfyUIのテンプレートとは?種類と使い方とおすすめ
ComfyUIのV1アップデート以降、起動時に左上の「ワークフロー」メニューから様々なテンプレートを選択できます。テンプレートを選ぶだけで、必要なモデルが不足している場合はシステムが自動でダウンロードを促してくれます。
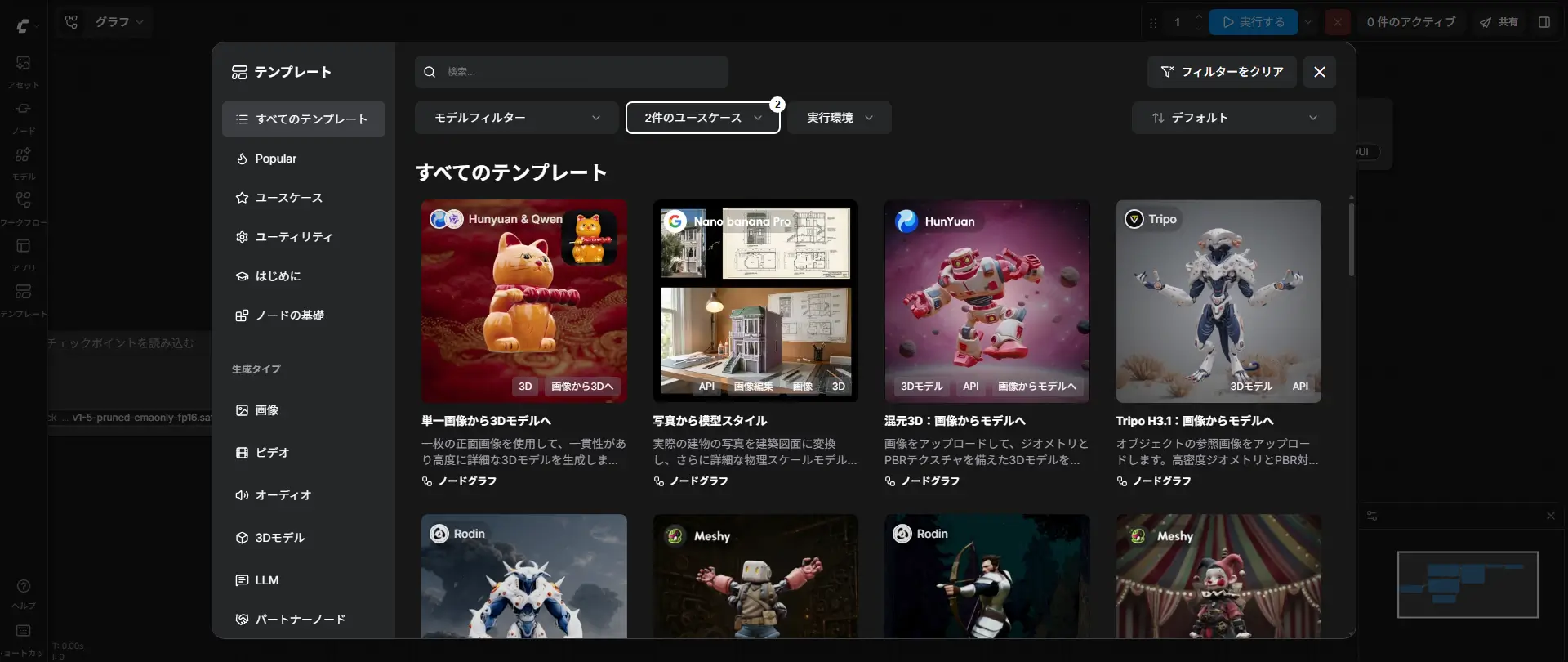
テンプレートの種類と使い方
最近では、FLUX・WAN・Qwen系の画像/動画生成や、LLM連携、外部APIを組み合わせた高度なワークフローも増えています。
以下は、ほんの一部の例ですが、テンプレートページ上部のモデルフィルターでジャンルごとに絞り込み検索するか、使用したいジャンルで絞り込み検索して使用します。
| カテゴリ | テンプレート名 | 用途・特徴 |
|---|---|---|
| 基本生成 | Image Generation | テキストから画像を生成する最もシンプルな構成 |
| 基本生成 | Simple txt2img | 最小構成のテキスト→画像生成 |
| モデル別 | Flux Dev | FLUX.2モデル用・高品質画像生成に特化 |
| モデル別 | Flux Schnell | FLUX.2モデル用・高速生成・動作確認に最適 |
| モデル別 | SDXL | SDXLベースモデル向け・高品質で汎用性が高い |
| モデル別 | SD1.5 | Stable Diffusion 1.5向けの軽量テンプレート |
| 高度な機能 | Image-to-Image | 既存画像をベースに新画像を生成 |
| 高度な機能 | Upscale | 画像の高解像度化(アップスケール) |
| 高度な機能 | ControlNet系 | ポーズ指定・線画からの生成など構図をコントロール |
| 高度な機能 | LoRA適用 | スタイルやキャラクター再現用 |
| 動画生成 | Hunyuan系 | テキスト・画像から動画を生成 |
| 動画生成 | WAN系 | クラウド環境向けの動画生成ワークフロー |
テンプレートのカスタマイズと保存
一度作成したノードの組み合わせは、選択した状態で右クリック →「Save Selected as Template」から.json形式で保存できます。
よく使う設定をテンプレート化しておくと作業効率が大幅に向上します。
また、OpenArtなどのオンラインプラットフォームでは、コミュニティが作成した多数のワークフローテンプレートが無料で公開されており、ダウンロードしてそのまま使えます。
ComfyUIの使い方・基本
ComfyUIの使用環境は、大きく
- クラウド(GPUをレンタルする方法)と
- ローカル(自分のパソコンにComfyUIをインストールする方法)
の2種類があります。
| 使用環境 | クラウド(RunPodなど) | ローカル(自分のPC) |
|---|---|---|
| 初期費用 | 不要 | GPUによっては高額 |
| 利用料金 | 使った分だけ | 無料(電気代のみ) |
| スペック不要 | ◎ | △ |
| 大型モデル(SDXL・Flux) | ◎ | VRAMに依存 |
| おすすめ対象 | まず試したい方/重いモデル、動画生成など | 長期的に使いたい方 |
まずクラウドで試してみて、慣れてきたらローカル環境に移行するのもおすすめです。
必要なスペック
ComfyUI はCPUだけでも起動できますが、快適に画像・動画生成を行うにはGPU(グラフィックボード)がほぼ必須です。
| 条件 | 内容 |
|---|---|
| 最小推奨GPU | NVIDIA RTX 3060以上 |
| VRAM 6GB以上 | Stable Diffusion 1.5系が普通に動作 |
| VRAM 12GB以上 | SDXLやFluxなど大型モデルが快適に動作 |
| システムメモリ | 最低8GB以上 |
用途別のスペック目安
| 用途 | 推奨GPU | VRAM目安 |
|---|---|---|
| 軽い画像生成(SD1.5) | RTX 3060 | 6GB〜8GB |
| SDXL・LoRA | RTX 4070 / 4070 SUPER 以上 | 12GB前後 |
| FLUX・動画生成(WANなど) | RTX 4090 / クラウドGPU | 16GB〜24GB以上 |
| 3D生成・大型モデル | L40 / H100系 | 24GB以上推奨 |
メモリ・ストレージの目安
| 項目 | 推奨 |
|---|---|
| メモリ | 16GB以上 |
| ストレージ | SSD 50GB以上 |
| OS | Windows 10/11 推奨 |
※モデルは数GB〜20GB以上あるため、SSD容量には余裕が必要です。
ComfyUIはクラウドGPUが快適
最近はモデルサイズも大きく出来る事も据えてどうしても生成速度が遅くなりがちです。
スペックが足りない場合は、クラウドGPU(RunPodなど) がおすすめです。
RunPodにはComfyUIがすぐに使えるテンプレートが用意されており、アカウント作成後にテンプレートを選ぶだけで、すぐにComfyUIを使用できます。
Wanや、Hunyuanなどの動画生成はもとより、Qwenなどもサクサク生成が進みます。
また、GPU性能がクラウド側にあるため、自分のPCが重くならず、ノートPCでも本格的な画像生成が可能です。
おすすめクラウドGPU
【Runpodとは?】なにが出来る?特徴・メリット・注意点を徹底解説【2026年版】 Runpodは、AI画像生成や動画生成、LoRA学習などに利用できるクラウドGPUサービスです 高価なGPUを購入しなくても、必要な時だけRTX 5090やA100などの高性能GPUをレンタ…
クラウドGPU比較記事
【2026年版】クラウドGPU比較|Runpod・Colab・Paperspace・Lambda Labsの特徴と選び方 クラウドGPUのニーズと記事の目的 近年、AI生成や3Dモデル作成、機械学習の学習用途などで、高性能GPUの需要が急速に高まっています。個人のPCでは対応が難しい処理も、…
ノートPCで本格画像生成!
【ノートPCでStableDiffusion】VRAM不足を解決する方法|クラウドGPU活用術 生成向けPCはもういらない?クラウド化が進むんでいる ノートPCでAI画像生成(Stable Diffusion など)を動かしたいけど、VRAM不足で諦めていませんか?実は、クラウドG…
画像生成のためのGPUの選び方
【2026年】AI画像生成GPU おすすめ比較|RTX4060〜5090・5060Ti【Stable Diffusion・ComfyUI・LoRA対応】 画像・動画生成AIを使いたい!GPUは何を選べばいい? Stable DiffusionやComfyUIで画像生成に挑戦したい――そう思ったとき、最初に立ちはだかる壁が「GPU選び」ではない…
時間をかけずに確実に動かしたい方へ
RunPodの最適なリージョン選びや、Templateの選び方・おすすめテンプレート
無駄な課金を防ぐ「コスト節約チェックリスト」、すぐに動くComfyUIの特製テンプレート設定は、SAKASAのnote記事【2026年最新版 Runpod使い方とコスト節約のコツ】にて限定公開中です。
試行錯誤の時間をショートカットしたい方はぜひチェックしてみてください!
note(ノート)
2026年最新【Runpod】使い方とコスト節約のコツと注意点|ComfyUIがすぐ使える版|SAKASA この記事では、完全初心者の方でも迷わずRunpodでComfyUIをセットアップできるよう、普段RunPodを使い倒している筆者が、スクリーンショットと解説動画とを組みあわせ、 Ru…
ローカルPCで使う方法
ローカルPCへのインストール
- 自分のPCにComfyUIをインストールして利用する方法です
- 一度セットアップすれば、以降は無料で使える
- ネットに接続せずに作業できるため、データを外に出さずに完結可能
- ただし GPU性能が低いと重い/モデルが動かない こともある
長く使いたい場合や、ネットに依存せず作業したい場合はローカルがおすすめです。
最新バージョンを体験したい場合は、ポータブルバージョンまたは手動インストール推奨です。
ComfyUI PortableとDesktopの違い
ComfyUIの通常使われるインストール方法は2種類で、それぞれ特徴が異なります。
| 項目 | Desktop版 | Portable版 |
|---|---|---|
| インストール | インストーラー形式 | zipを解凍するだけ |
| コマンド操作 | 不要 | 不要 |
| 最新開発版の利用 | △ | ◎ |
| 他のPCへの移行 | 手間がかかる | フォルダごとコピーでOK |
| カスタムノード追加 | やや不向き | 向いている |
| おすすめ対象 | 初心者 | 中〜上級者 |
はじめてComfyUIを使う方にはDesktop版がおすすめです。
最新機能を試したい・カスタムノードをたくさん入れたい方はPortable版または手動(GitHub)インストールを選びましょう。
インストール方法
※詳細なインストール方法は、こちらのページで解説しています。
SAKASA AI
【2026年版】ComfyUIのインストール方法|Desktop・Portable・GitHub版の違いとおすすめ | SAKASA AI ローカルPCへComfyUIをインストールする方法 以前のComfyUIは「上級者向け」の印象が強く、環境構築で止まる人も多いツールでした。 しかし現在は、Desktop版の登場やテン…
ComfyUIの使い方
ComfyUIの使い方はこちらの記事で詳しく解説しています。
SAKASA AI
ComfyUIの使い方|テンプレートのおすすめ・画像生成・基本操作を解説【2026年版】 | SAKASA AI ComfyUIの基本操作とテンプレートの選び方 この記事では、ComfyUIの基本操作、テンプレートの選び方から基本的な画像生成でのUI画面の使い方を解説しています。 ComfyUIで…
方法①:テンプレート選択時に自動ダウンロード 起動時にテンプレートを選択すると、必要なモデルが不足している場合にシステムが自動で案内してくれます。
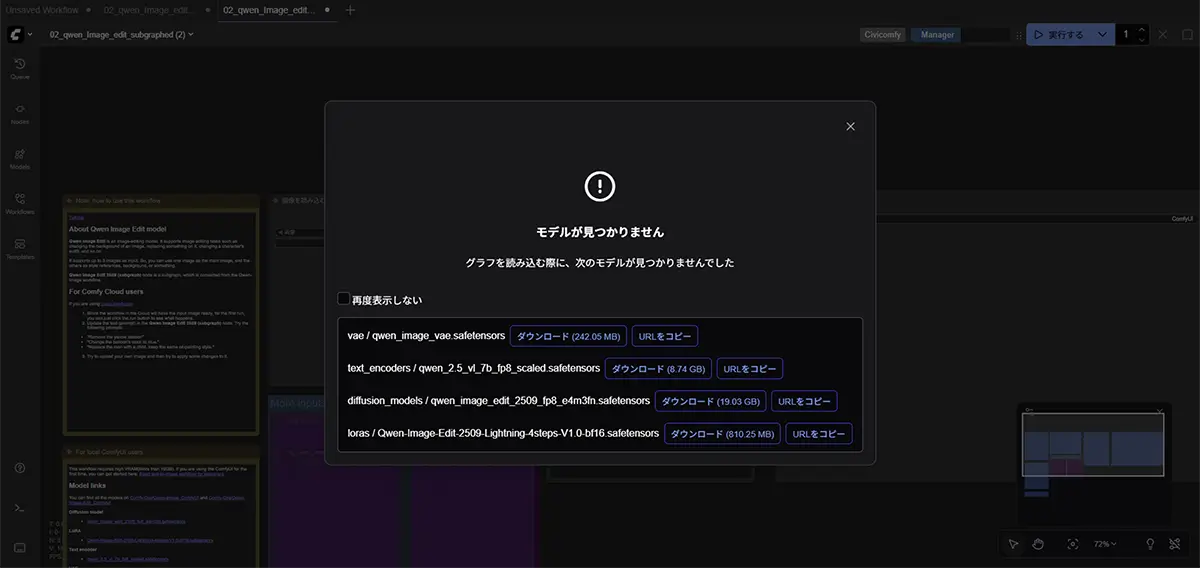
方法②:ComfyUI Manager(Model Manager)から
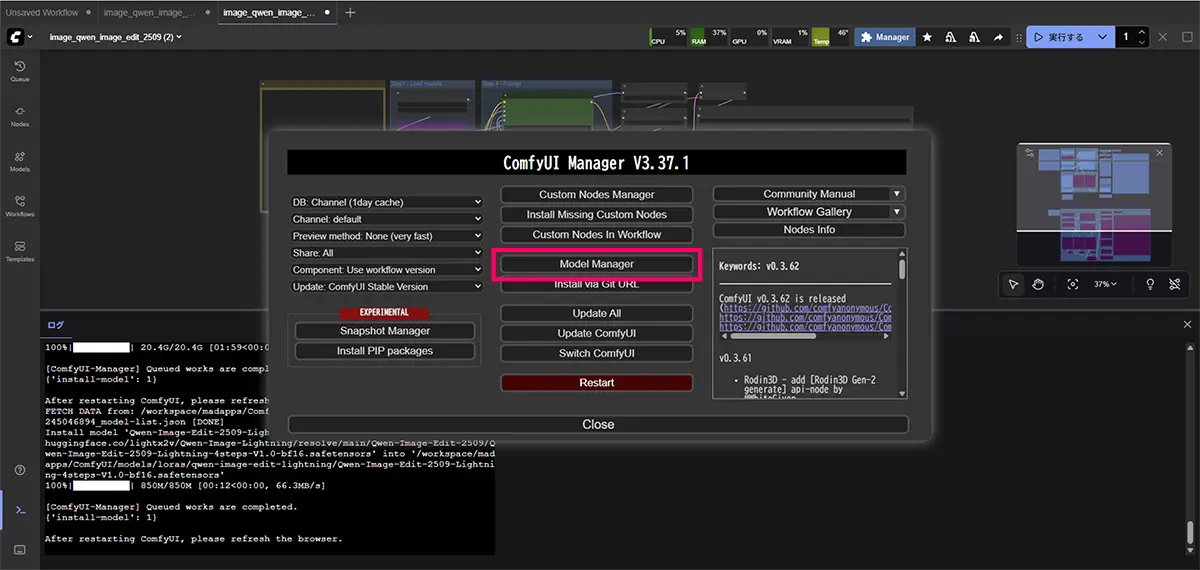
- UI画面上部の「Manager」を開く
- 「Model Manager」からモデルを検索
- ダウンロードボタンをクリック
- UIを再起動
- ComfyUIを起動すると、ノードからモデルが選べるようになります
あわせて読みたい
Civitaiとは?LoRA・Checkpointモデルの探し方と安全な使い方【2026年版】 Civitaiとは?AIモデルの探し方・LoRA/Checkpointの選び方を初心者向けに解説【2026年版】 引用元:Civitai公式サイト Civitai(シビタイ)は、AI画像生成で使われる「…
Fluxや一部のSDXL系は、Hugging Face の「認証が必要なモデル」です。認証モデルのダウンロード方法に関しては以下の記事の中で書いています。
あわせて読みたい
ComfyUIで認証モデルを使う方法|Hugging Face Tokenの発行手順 HuggingFaceでのトークン発行 https://huggingface.co/settings/tokens 「Write」権限(読み込みだけなら「Read」でも可)のトークンを発行 コピーしておく モデルの…
SAKASA AI
Stable Diffusion・FLUX・Qwen主要モデル比較【2026年最新版】 | SAKASA AI Stable Diffusion・FLUX・Qwenの主要モデルを徹底比較。SDXL、SD3.5、FLUX.2、Qwen-Imageの特徴、用途、推奨VRAM、対応ツール、おすすめモデルを2026年最新版でわかりやす…
SAKASA AI
【画像編集】ComfyUIで“描き直す”高画質化|Qwen-Image-Edit-Rapid-AIOの使い方と実力 | SAKASA AI ComfyUIでQwen-Image-Rapid AIO(v18)を使い、ディテールを“描き直す”高解像度化の方法を解説。ぼやけた画像をシャープに改善する仕組みや導入手順、向いている用途までわか…
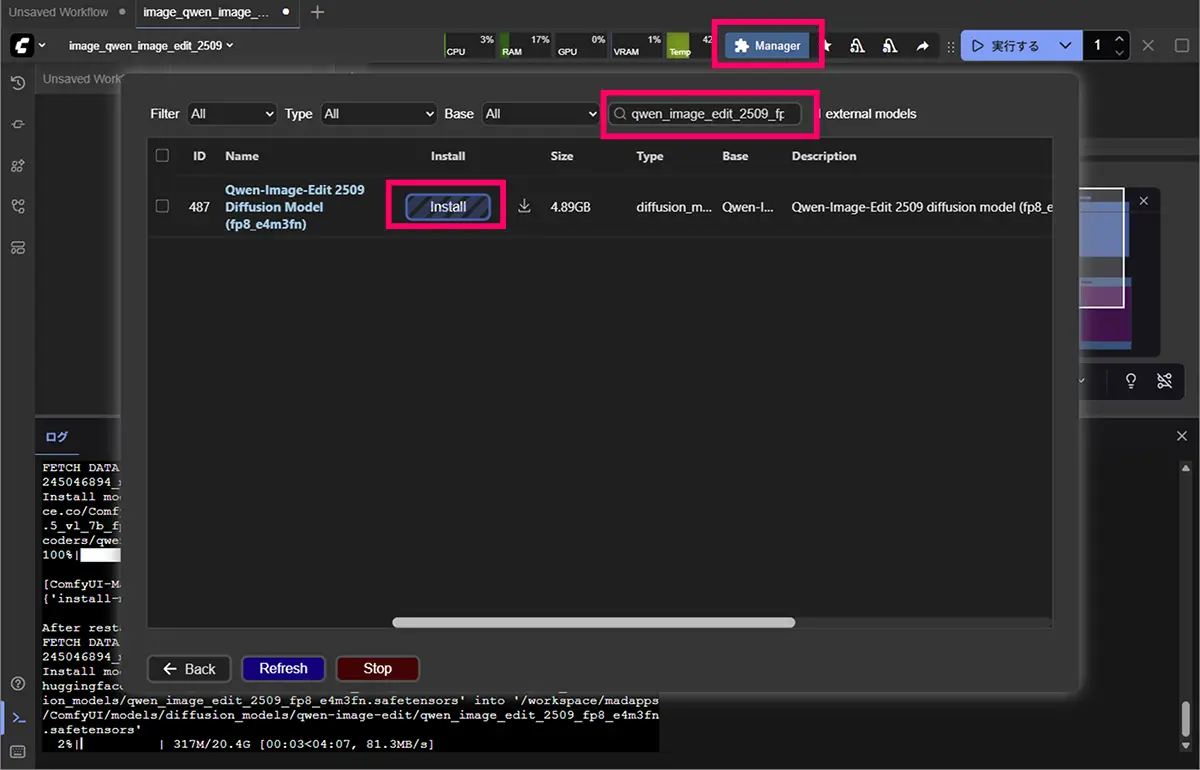
方法③:HuggingFace / Civitaiから直接ダウンロード Model Managerにないモデルは外部サイトから入手し、以下のフォルダに配置します。
ComfyUI/models/checkpoints/ ← Checkpointモデル
ComfyUI/models/loras/ ← LoRAモデル
ComfyUI/models/controlnet/ ← ControlNetモデル
ComfyUI/models/vae/ ← VAEモデル最新アップデート(v0.3.76〜v0.21.1)「※2026年5月時点」
| バージョン | リリース日 | 主なトピック |
|---|---|---|
| v0.3.76 | 2025年12月 | Nodes 2.0 パブリックベータ、リニアモード追加 |
| v0.20.1 | 2026年4月 | SUPIR・SAM3.1対応、動画4K解像度サポート |
| v0.21.0 | 2026年5月 | BiRefNet・Gemma4対応、LoRA非同期ロードで高速化 |
| v0.21.1 | 2026年5月 | Claude LLMノード追加、HiDream-O1-Image対応 |
v0.21.1でComfyUIにClaude(Anthropic)のLLMノードが正式追加されており、テキスト生成ワークフローとの連携が可能になっています。
まとめ
ComfyUIは、画像・動画・3D生成をノードベースで自由に操作できる高機能ツールです。2026年時点では初心者向けの整備も進み、テンプレート選択→モデル自動ダウンロードという流れで誰でも始めやすくなっています
| 目的 | おすすめの選択 |
|---|---|
| とりあえず試したい | Flux Schnell テンプレート × Desktop版 |
| 高品質な画像を作りたい | SDXL / Flux Dev × LoRA組み合わせ |
| ポーズ・構図を指定したい | ControlNet + テンプレート |
| PCスペックが足りない | クラウドGPU(RunPodなど) |
| 動画も生成したい | WAN系テンプレート(クラウド推奨) |
まずはテンプレートから始めて、慣れてきたら自分でノードをカスタマイズしていくのがおすすめです。
ComfyUIでQwenを使う

ComfyUIでWANを使う


Comfyのエラー
SAKASA AI
【保存版】ComfyUIが急に動かない原因はこれだった!ローカル環境の落とし穴と、クラウドで一発解決できる… ComfyUIが急に動かない?起動エラーの本当の原因を、ローカル環境の依存関係・CUDA衝突まで徹底解説。DockerやRunPodで一発解決する方法も詳しくまとめています。