深層学習(ディープラーニング)と自己学習(セルフラーニング)と自律学習(オートノマスラーニング)と生成AI

生成AIの学習の仕組みを知る
ディープラーニング(深層学習)を活用して画像や文章を生成する生成AIの学習スタイルは複雑。
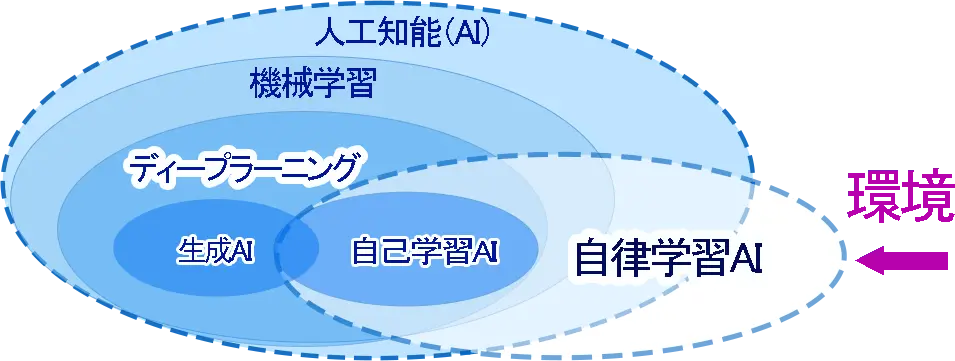
ディープラーニング(深層学習)は AIが学習するための技術 の一つであり、自己学習は 学習の仕組みの概念 で、
「自己学習型AI」がディープラーニング(深層学習)を利用することもありますが、必ずしもイコールではありません。
学習方法の違い
| 深層学習(ディープラーニング) | 自己学習(Self-Learning) | 自律学習(Autonomous Learning | |
|---|---|---|---|
| 定義 | 多層ニューラルネットを使った学習手法 | AIが自律的にデータから学ぶ仕組み | 目的を持ち、 計画を立てながら学習 |
| 学習方法 | 教師あり学習 / 教師なし学習 / 強化学習 | 強化学習 / 自己教師あり学習 | 環境との相互作用を通じて 自己判断で学習 |
| 人の介入 | データラベル付けやチューニングが必要 | 人間の介入なしで学習可能 | ほぼ不要(ただし学習の枠組みは設定される) |
| 例 | 画像認識、音声認識 | AlphaGo、GPT、スパムフィルター | 強化学習、AlphaGo、自律ロボット、無人探索AI |
「自己学習AI」と「自律学習AI」の関係
「自己学習AI」は「自律学習AI」の一部である
つまり、「自律学習AI」の中に「自己学習AI」が含まれる関係になっています。
では、それぞれの特徴を見てみましょう。
🔹 自己学習AI(Self-Learning AI)とは?
➡ 「自分で学習データを作り出し、学習を進めるAI」
人間が用意したデータだけでなく、AIが自らデータを生成・補完しながら学習する仕組みを持っています。
特徴
- 人間が用意するデータに依存しないため、より多様な学習が可能
自律学習AI(Autonomous Learning AI)とは?
➡ 「環境との相互作用を通じて、試行錯誤しながら独自に学習するAI」
自己学習AIよりも広義で、単なるデータ解析ではなく、AIが「行動→フィードバック→学習」を繰り返しながら進化する。
特徴
- 強化学習をベースにした試行錯誤の学習
- 環境に適応し、意思決定を自律的に行う
自己学習AIは「データを生成しながら学習するAI」であり、試行錯誤を繰り返して学ぶ「自律学習AI」の一部として考えられる。
目次
生成AIの学習方法
生成AI(ChatGPTやMidjourneyなど)は、基本的に 深層学習(ディープラーニング) を活用しています。
その学習プロセスは以下のように進みます:
- 事前学習(Pre-training) → 巨大なデータセット(テキストや画像)を使い、パターンを学習
- 教師あり学習(Supervised Learning) → 正しい出力を与えて学習させる
- 強化学習(Reinforcement Learning, RLHF) → 人間のフィードバックで改善
- 推論(Inference) → 学習済みの知識を使い、新しいデータに対応
この中で 「自己学習型」 に近い部分があるのは 事前学習の一部 です。
例えば、ChatGPTは 自己教師あり学習(Self-Supervised Learning) を使い、データの一部を隠して予測する形で学習します。
しかし、完全に「自分で新しいことを学び続ける」わけではありません。
生成AI(Generative AI)は、自己学習型AIといえるのか
結論 生成AIは「自己学習型」とは必ずしも言えない
生成AIは 「自己学習(Self-Learning)」を一部活用 しているが、完全な自己学習型AIとは言えない。
なぜなら、自己学習型AIは「※ラベルなしデータから自律的に学ぶAI」 を指すことが多いからです。
※ラベルなしデータとは?
ラベルなしデータとは、入力データには含まれているものの、それに対応する「正解」(ラベル)が付与されていないデータのことを指します。
例えば:
- ラベルありデータ(教師あり学習)
- 画像 → 「犬」「猫」などのラベル付き
- メール → 「スパム」「通常メール」のラベル付き
- ラベルなしデータ(教師なし学習)
- 画像のみ(何が写っているかは不明)
- 未分類のテキストデータ
ラベルなしデータの活用
ラベルなしデータは、以下のような方法でAIに学習させることができます。
- 教師なし学習(Unsupervised Learning)
- クラスタリング(K-means, 階層的クラスタリングなど)
→ データを似た特徴ごとにグループ分けする - 次元削減(PCA, t-SNEなど)
→ データを簡潔にまとめて可視化・分析しやすくする
- クラスタリング(K-means, 階層的クラスタリングなど)
- 半教師あり学習(Semi-Supervised Learning)
- ラベルのあるデータとラベルなしデータを組み合わせて学習
- 少量のラベル付きデータを活用し、未ラベルデータの分類精度を向上させる
- 自己教師あり学習(Self-Supervised Learning)
- AIがデータの一部を推測することで学習
- 例:「文章の一部を隠して、AIに補完させる」→ GPTやBERTの学習手法
なぜラベルなしデータが重要なのか?
- 大量のデータを活用できる
→ ラベル付きデータを作るには人手が必要でコストが高いが、ラベルなしデータなら大量に収集可能。 - 未知のパターンを発見できる
→ AIが自動的にデータの構造を見つけ、新たな傾向や関係を把握できる。 - 最近のAI(自己教師あり学習)では不可欠
→ ChatGPTのような大規模AIは、ラベルなしデータを使って膨大な知識を学習している。
自己学習型AI(Self-Learning AI)との違い
「自己学習型AI」とは、人間の介入なしにデータから自律的に学び、進化できるAI を指します。
例えば、次のようなAIが自己学習型に近いと言えます:
- AlphaGo Zero(囲碁AI)→ 最初は何も知らず、自分で試行錯誤しながら学習
- 自己回帰型モデル(Self-Recursive Learning) → 生成したデータを再利用し、自己改善
一方、現在の生成AI(ChatGPTやMidjourney)は「学習済みモデル」を使う ため、
ユーザーが使うたびに新しい知識を「自分で学習し続ける」わけではありません。
学習のアップデートには 再トレーニング や 人間のフィードバック が必要。

まとめ
生成AIは 深層学習の一種 であり、学習済みのモデルをもとにコンテンツを作る
自己学習型AIとは異なり、人間の介入なしに学び続けるわけではない
一部の生成AIは「自己教師あり学習」など自己学習技術を活用 しているが、完全に自己学習型ではない
将来的には自己学習型生成AIが登場する可能性もある